November 3, 2024
mindmap
root((Advanced SQL Techniques for ETL))
CASE Statements
Conditional Logic
Data Standardization
Conditional Aggregation
FILTER Alternative
GROUP BY Operations
Data Aggregation
Monthly Metrics
Handling Nulls
COALESCE Function
Window Functions
Partitioning
RANK
Rolling Aggregates
Duplicate Detection
SQL Functions
LEAD & LAG
ROW_NUMBER
DENSE_RANK
Cumulative Metrics
Table Partitioning
Performance Optimization
Date-Based Partitioning
Query Efficiency
Scalability
Advanced SQL Techniques for ETL
- CASE Statements with conditional logic, standardization, and FILTER alternatives
- GROUP BY Operations including aggregation, metrics, and null handling
- Window Functions with partitioning, ranking, and duplicate detection
- SQL Functions like LEAD(), LAG(), and ROW_NUMBER()
- Table Partitioning for performance and scalability
Ever wrestled with massive datasets using procedural scripts? You know that feeling—like moving a mountain with a teaspoon. Transform that struggle into power with advanced SQL techniques that turn hours into minutes.
These SQL methods revolutionize ETL processes. Database engines optimize operations at their core, unlocking possibilities you never imagined. Complex transformations execute in seconds, not hours. Your ETL workflows gain scalability, consistency, and maintainability.
Ready to command your data instead of following it? Let’s dive into the techniques that separate data engineers from data heroes.
ETL Fundamentals
ETL (Extract, Transform, Load) processes form the backbone of data engineering. They transform raw data into meaningful formats for analysis and storage. While SQL appears simple at first, using its full power demands mastery of advanced techniques like CASE statements, GROUP BY clauses, and partitioning.
Using CASE Statements for Conditional Logic
Data transformation often requires converting inconsistent values into standardized forms. The CASE statement provides flexible conditional logic for these scenarios.
Cleaning Product Categories
Consider a table with inconsistent product categories—typos, variations, and mixed cases. Transform these into uniform values:
SELECT product_id,
product_name,
CASE
WHEN LOWER(category) IN ('elec', 'electronics', 'elctronics')
THEN 'Electronics'
WHEN LOWER(category) IN ('furn', 'furniture', 'furnishings')
THEN 'Furniture'
ELSE 'Other'
END AS standardized_category
FROM raw_products;
The CASE statement standardizes different spellings and variations. Using LOWER() ensures case differences don’t affect transformation. This approach handles data cleansing without complex scripting languages or additional tools.
Conditional Aggregation
Apply CASE within GROUP BY queries to calculate category-specific metrics:
SELECT region,
SUM(CASE WHEN category = 'Electronics' THEN sales_amount ELSE 0 END)
AS electronics_sales,
SUM(CASE WHEN category = 'Furniture' THEN sales_amount ELSE 0 END)
AS furniture_sales
FROM sales_data
GROUP BY region;
Step-by-Step Breakdown:
SELECT regionretrieves the region column for grouping- First
SUM(CASE...)creates electronics_sales column by summing only Electronics sales - Second
SUM(CASE...)creates furniture_sales column for Furniture items only FROM sales_dataspecifies the source tableGROUP BY regiongroups rows by region before applying SUM functions
Analyzing Store Performance
Count unique products and sales periods per store:
SELECT store_id,
COUNT(DISTINCT product_id) as num_products,
COUNT(DISTINCT( to_char(sale_date, 'dd/mm/yyyy') ||
to_char(end_of_sale_period, 'dd/mm/yyyy') )) as num_sale_periods
FROM sales_data
GROUP BY store_id
ORDER BY store_id ASC;
This query reveals:
- num_products: Product variety per store
- num_sale_periods: Frequency of sales events
- Efficient summarization using
COUNT(DISTINCT)withGROUP BY
Beyond CASE: Using FILTER
PostgreSQL’s FILTER clause offers cleaner conditional aggregation:
-- Traditional CASE approach
SELECT region,
SUM(CASE WHEN category = 'Electronics' THEN sales_amount ELSE 0 END) AS electronics_sales,
SUM(CASE WHEN category = 'Furniture' THEN sales_amount ELSE 0 END) AS furniture_sales
FROM sales_data
GROUP BY region;
-- Cleaner FILTER approach
SELECT region,
SUM(sales_amount) FILTER (WHERE category = 'Electronics') AS electronics_sales,
SUM(sales_amount) FILTER (WHERE category = 'Furniture') AS furniture_sales
FROM sales_data
GROUP BY region;
FILTER Benefits:
- Enhanced readability
- Potential performance improvements
- Easier maintenance
Database Support:
- Supported: PostgreSQL, SQLite 3.30+, Amazon Redshift, Google BigQuery
- Not Supported: MySQL, SQL Server, Oracle (use CASE instead)
GROUP BY for Data Aggregation
The GROUP BY clause transforms granular data into meaningful summaries—essential for reporting and analysis.
Calculating Monthly Metrics
Transform transaction timestamps into monthly summaries:
SELECT DATE_TRUNC('month', transaction_date) AS sales_month,
COUNT(*) AS total_transactions,
SUM(sales_amount) AS total_sales
FROM transactions
GROUP BY sales_month
ORDER BY sales_month;
DATE_TRUNC('month', transaction_date) converts timestamps to month beginnings, enabling monthly grouping. Combine with COUNT() and SUM() for comprehensive monthly insights.
Handling Null Values with COALESCE
Ensure comprehensive reporting by handling null values:
SELECT COALESCE(region, 'Unknown') AS region,
COUNT(*) AS transaction_count
FROM transactions
GROUP BY COALESCE(region, 'Unknown');
COALESCE() returns the first non-null value, grouping null regions as ‘Unknown’. This approach:
- Replaces nulls with meaningful defaults
- Ensures data consistency
- Simplifies complex null-handling logic
Window Functions and Partitioning
Window functions perform calculations across data subsets without collapsing rows—crucial for maintaining granularity during transformations.
Ranking Customer Transactions
Identify highest-value transactions per customer:
SELECT customer_id,
transaction_id,
sales_amount,
RANK() OVER (PARTITION BY customer_id ORDER BY sales_amount DESC) AS transaction_rank
FROM transactions;
PARTITION BY segments data by customer, while RANK() assigns rankings within each segment based on sales amount.
Rolling Aggregates
Calculate moving averages for trend analysis:
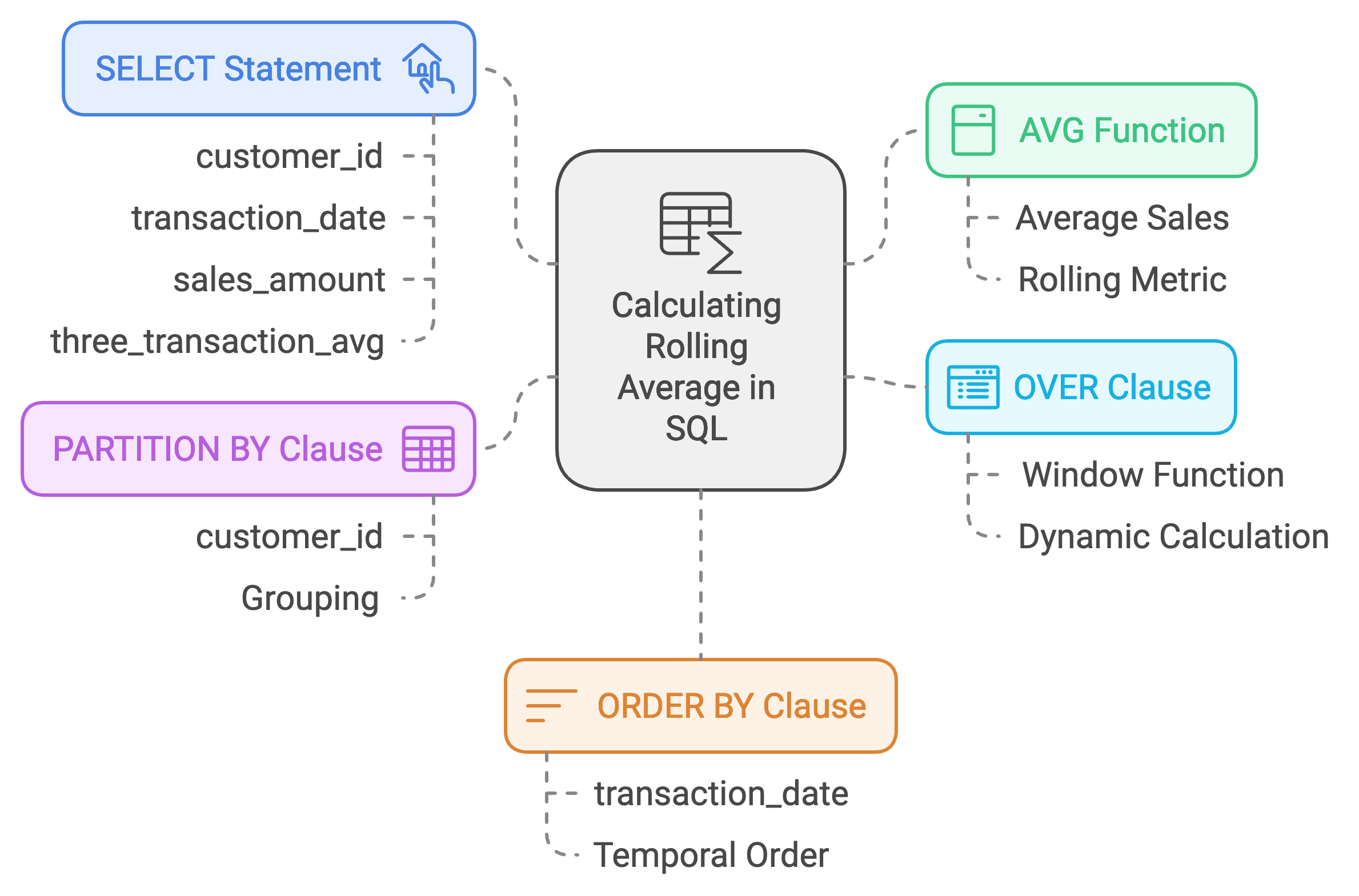
SELECT customer_id,
transaction_date,
sales_amount,
AVG(sales_amount) OVER (PARTITION BY customer_id
ORDER BY transaction_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
AS three_transaction_avg
FROM transactions;
Step-by-Step Breakdown:
- Selects customer_id, transaction_date, and sales_amount
- Creates three_transaction_avg using window function
- Partitions by customer_id for individual customer analysis
- Orders by transaction_date within partitions
- Defines window frame as current row plus two preceding rows
- Calculates rolling three-transaction average
Identifying Duplicate Records
Detect potential duplicate orders for data quality:
SELECT *,
COUNT(*) OVER (PARTITION BY customer_id, order_date, product_id) > 1 as is_duplicate
FROM sales_orders
ORDER BY customer_id ASC, order_date ASC, product_id ASC;
- Groups data by customer_id, order_date, and product_id
- Marks records with count > 1 as duplicates
- Sorts results for easier analysis
Essential Window Functions
classDiagram
class WindowFunction {
+name: string
+purpose: string
+syntax: string
+applyToPartition(): result
}
class RankingFunction {
+assignRank(): number
}
class AggregateFunction {
+calculate(): number
}
class NavigationFunction {
+accessRow(): value
}
WindowFunction <|-- RankingFunction
WindowFunction <|-- AggregateFunction
WindowFunction <|-- NavigationFunction
class RANK {
+handleTies: boolean
}
class DENSE_RANK {
+noGaps: boolean
}
class ROW_NUMBER {
+unique: boolean
}
class SUM_OVER {
+cumulative: boolean
}
class LEAD {
+offset: number
}
class LAG {
+offset: number
}
RankingFunction <|-- RANK
RankingFunction <|-- DENSE_RANK
RankingFunction <|-- ROW_NUMBER
AggregateFunction <|-- SUM_OVER
NavigationFunction <|-- LEAD
NavigationFunction <|-- LAG
Step-by-Step Explanation:
WindowFunctionbase class defines common window function propertiesRankingFunctionsubclass handles ranking operationsAggregateFunctionsubclass performs calculationsNavigationFunctionsubclass accesses adjacent rows- Specific functions inherit from appropriate subclasses
- Each function has unique characteristics (e.g., RANK handles ties)
Key Window Functions:
- RANK(): Assigns ranks with gaps for ties
- ROW_NUMBER(): Unique sequential integers
- DENSE_RANK(): Ranks without gaps
- NTILE(n): Divides rows into n buckets
- SUM/AVG/MAX/MIN OVER: Partition-based aggregations
- LEAD/LAG: Access subsequent/preceding rows
- FIRST_VALUE/LAST_VALUE: Partition boundaries
- PERCENT_RANK/CUME_DIST: Distribution metrics
Detecting Overlapping Product Launches
Identify scheduling conflicts using LEAD:
SELECT *,
(end_date > LEAD(start_date) OVER (PARTITION BY product_line
ORDER BY start_date)) as is_overlapping
FROM product_launches
ORDER BY product_line ASC, start_date ASC, product_id ASC;
- Partitions by product_line for line-specific analysis
- LEAD accesses next product’s start date
- Flags overlaps when current end_date exceeds next start_date
Tracking Price Changes
Analyze pricing trends with LAG:
SELECT
product_id,
update_date,
price,
LAG(price) OVER (PARTITION BY product_id ORDER BY update_date)
as previous_price,
price - LAG(price) OVER (PARTITION BY product_id ORDER BY update_date)
as price_change
FROM product_pricing
ORDER BY product_id ASC, update_date ASC;
- Tracks individual product price history
- LAG retrieves previous price
- Calculates price change between updates
Optimizing with Partitioned Tables
Physical partitioning enhances query performance for large datasets:
Date-Based Partitioning
CREATE TABLE sales_partitioned (
sales_id BIGINT,
transaction_date DATE,
sales_amount DECIMAL(10, 2),
customer_id BIGINT
)
PARTITION BY RANGE (transaction_date);
ALTER TABLE sales_partitioned
ADD PARTITION FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
Partitioning by transaction_date:
- Enables partition pruning for date-filtered queries
- Reduces scan times for time-series analysis
- Improves ETL workflow efficiency
Conclusion
Advanced SQL techniques transform ETL from a challenge into an advantage. Master these tools:
- CASE statements for data standardization
- GROUP BY for meaningful aggregations
- Window functions for sophisticated analysis
- Partitioning for performance optimization
Your ETL processes become faster, more reliable, and easier to maintain. Practice these techniques on real datasets. Transform from data mover to data master.
Glossary
| Term | Description |
|---|---|
| ETL | Extract, Transform, Load - Process for data movement and transformation |
| COUNT(DISTINCT) | Counts unique values in a column |
| FILTER clause | PostgreSQL feature for conditional aggregation |
| GROUP BY | Groups rows with same values for aggregation |
| Window functions | Calculations across row sets without grouping |
| RANK() | Assigns ranks within partitions |
| LAG() | Accesses previous row values |
| PARTITION BY | Divides rows for window function application |
| CASE statement | Conditional logic in SQL |
| LEAD() | Accesses subsequent row values |
| Table partitioning | Physical division of large tables |
About the Author
Rick Hightower brings over two decades of experience as a software architect and data engineering expert. His expertise spans Python, Java, Kotlin, and SQL. He focuses on database optimization and ETL workflow design.

Rick has led numerous projects involving complex data systems and cloud architecture. As a prolific writer and speaker, he’s authored several books on Java and cloud computing. He shares insights on data engineering best practices at conferences and through technical blogs.
When not crafting SQL queries, Rick mentors aspiring data engineers. He contributes to open-source projects pushing data processing boundaries.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting