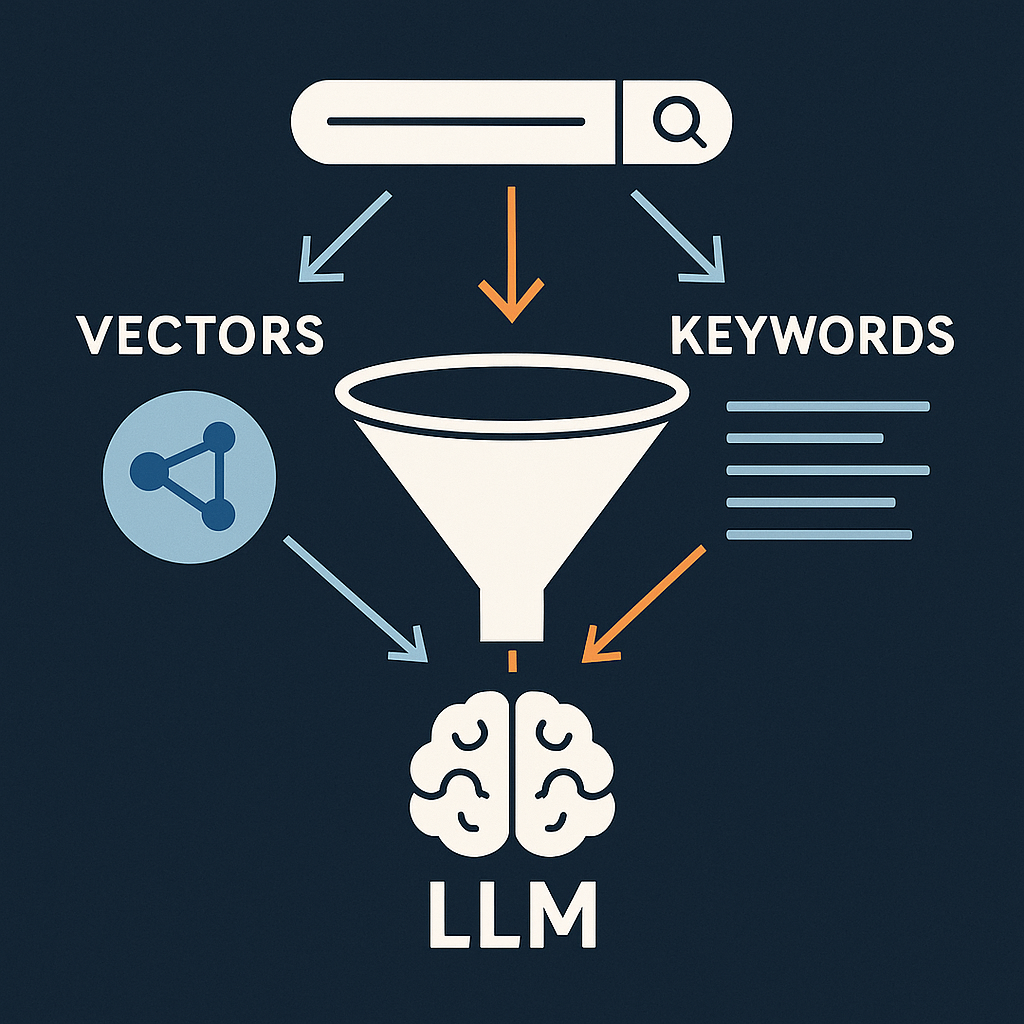
Article 5 Tokenization - Converting Text to Number
Article 5: Tokenization - Converting Text to Numbers for Neural Networks
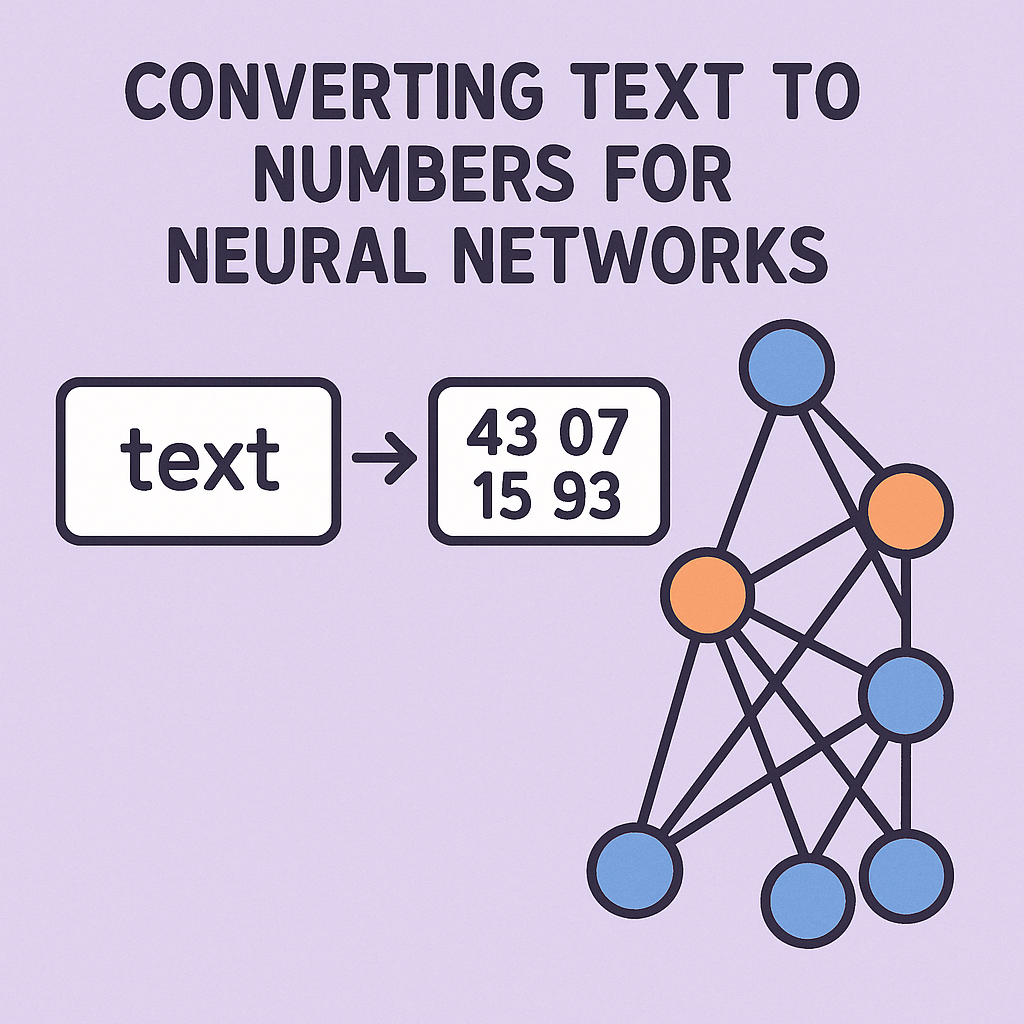
Introduction: Why Tokenization Matters
Imagine trying to teach a computer to understand Shakespeare without first teaching it to read. This is the fundamental challenge of natural language processing. Computers speak mathematics, while humans speak words. Tokenization is the crucial bridge between these two worlds.
Every time you ask ChatGPT a question, search for information online, or get an auto-complete suggestion in your email, tokenization works silently behind the scenes. It converts your text into the numerical sequences that power these intelligent systems.