May 20, 2025
Ready to transform your chat experience? Discover how our latest enhancements—real-time streaming, context-aware conversations with RAG, and AWS Bedrock integration—transform a simple chat app into a powerful knowledge tool! Dive into the future of AI-driven communication.
Enhancements to the Multi-Provider Chat App include real-time streaming responses, Retrieval-Augmented Generation (RAG) for context-aware interactions, and AWS Bedrock integration for access to high-quality foundation models, improving user experience and responsiveness.
This article is an continuation of this one Multi-Provider Chat App: LiteLLM, Streamlit, Ollama, Gemini, Claude, Perplexity, and Modern LLM Integration.
In our journey to build a more powerful, flexible chat application, we’ve continued to evolve our Multi-Provider Chat App with three major enhancements: Retrieval-Augmented Generation (RAG), real-time streaming responses, and AWS Bedrock integration. These improvements transform our chat application from a simple interface into a platform that can access your organization’s knowledge, provide dynamic responses as they’re generated, and tap into Amazon’s foundation models.
Let’s explore how these features work together to create a better chat experience, picking up where we left off with our Streamlit and LiteLLM multi-provider chat application.
The Evolution of Our Chat Application
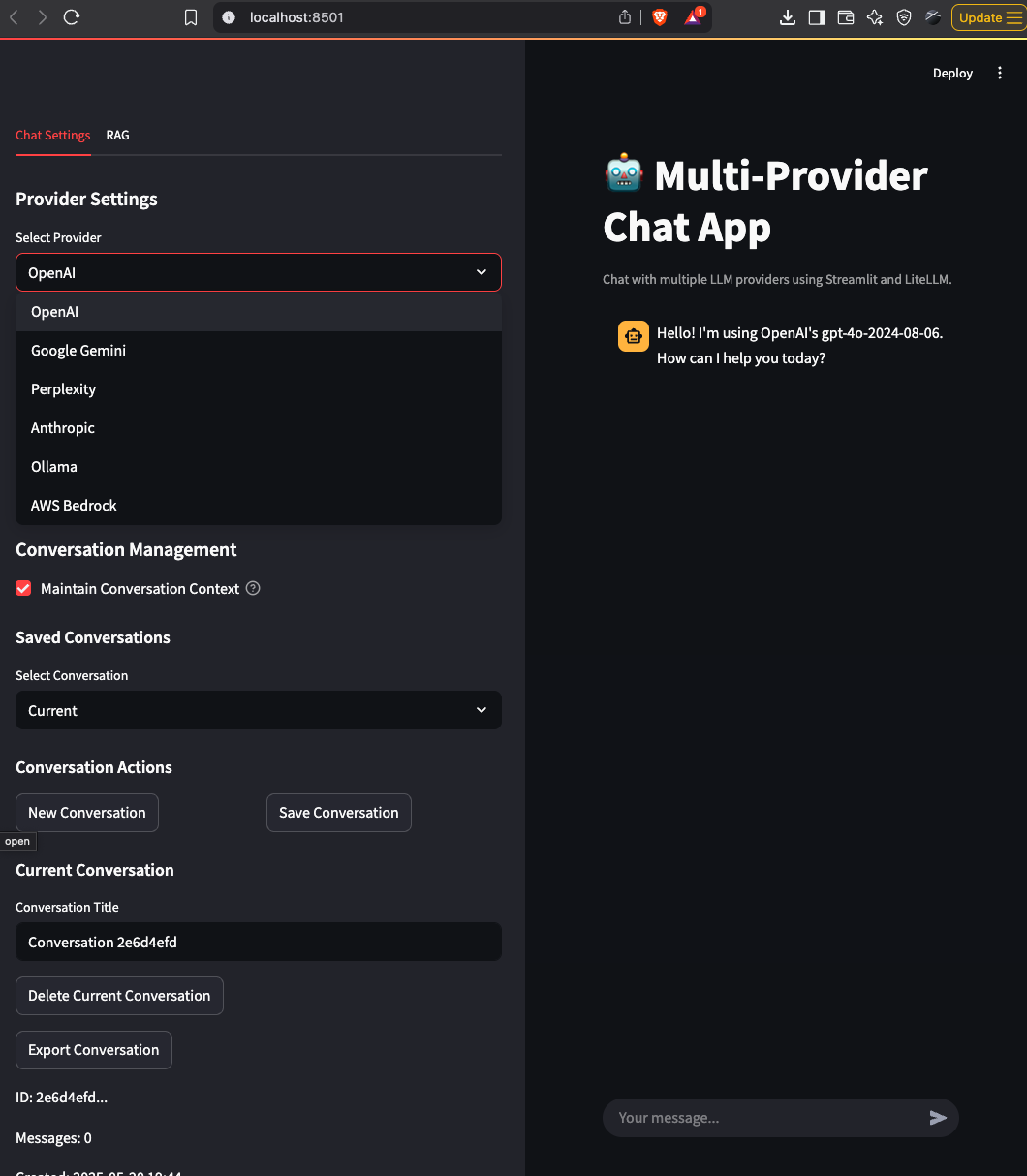
In our previous article, we built a flexible chat application that could leverage multiple LLM providers—including OpenAI, Anthropic Claude, Google Gemini, Perplexity, and Ollama—through a clean, user-friendly interface. The application allowed users to:
- Chat with various LLM providers through a unified interface
- Select different models from each provider
- Maintain conversation history across provider switches
- Save, load, and manage conversations
- Configure provider-specific settings
Now, we’ve taken this application to the next level with three powerful enhancements:
1. Real-Time Streaming: Watch AI Think in Real-Time
The most immediately noticeable improvement is the addition of streaming responses. Rather than waiting for the complete response from the LLM, the application now displays text as it’s generated, character by character.
Have you ever wanted to see how an AI “thinks” in real-time? With streaming support, you can watch as the model formulates its response word by word, giving you immediate feedback and a more interactive experience. This is useful for longer responses, where waiting for the complete answer could take several seconds.
How Streaming Works
At a high level, streaming works by establishing a connection that receives chunks of text as they’re generated, rather than waiting for the complete response. Here’s how we implemented it:
async def generate_completion_stream(
self,
prompt: str,
output_format: str = "text",
options: Optional[Dict[str, Any]] = None,
conversation: Optional[Conversation] = None,
callback: Optional[Callable[[str], None]] = None
) -> AsyncGenerator[str, None]:
"""Generate a streaming completion from the LLM."""
# Implementation details will vary by provider
Each provider class now implements this method, which returns an asynchronous generator that yields text chunks as they’re generated. The UI then receives and displays these chunks in real-time using a callback function:
def update_message_placeholder(chunk: str):
nonlocal full_response
full_response += chunk
# Add blinking cursor to show it's still streaming
message_placeholder.markdown(full_response + "▌")
This creates a more engaging experience, mimicking the way a human might type a response. For complex queries that require significant processing time, users get immediate feedback rather than staring at a loading indicator.
Benefits of Streaming
-Improved User Experience: Users don’t have to wait for complete responses -Real-Time Feedback: You can see how the model “thinks” as it constructs its answer -Faster Perceived Response Times: Even if the total generation time is the same, users perceive the response as faster because they receive content immediately
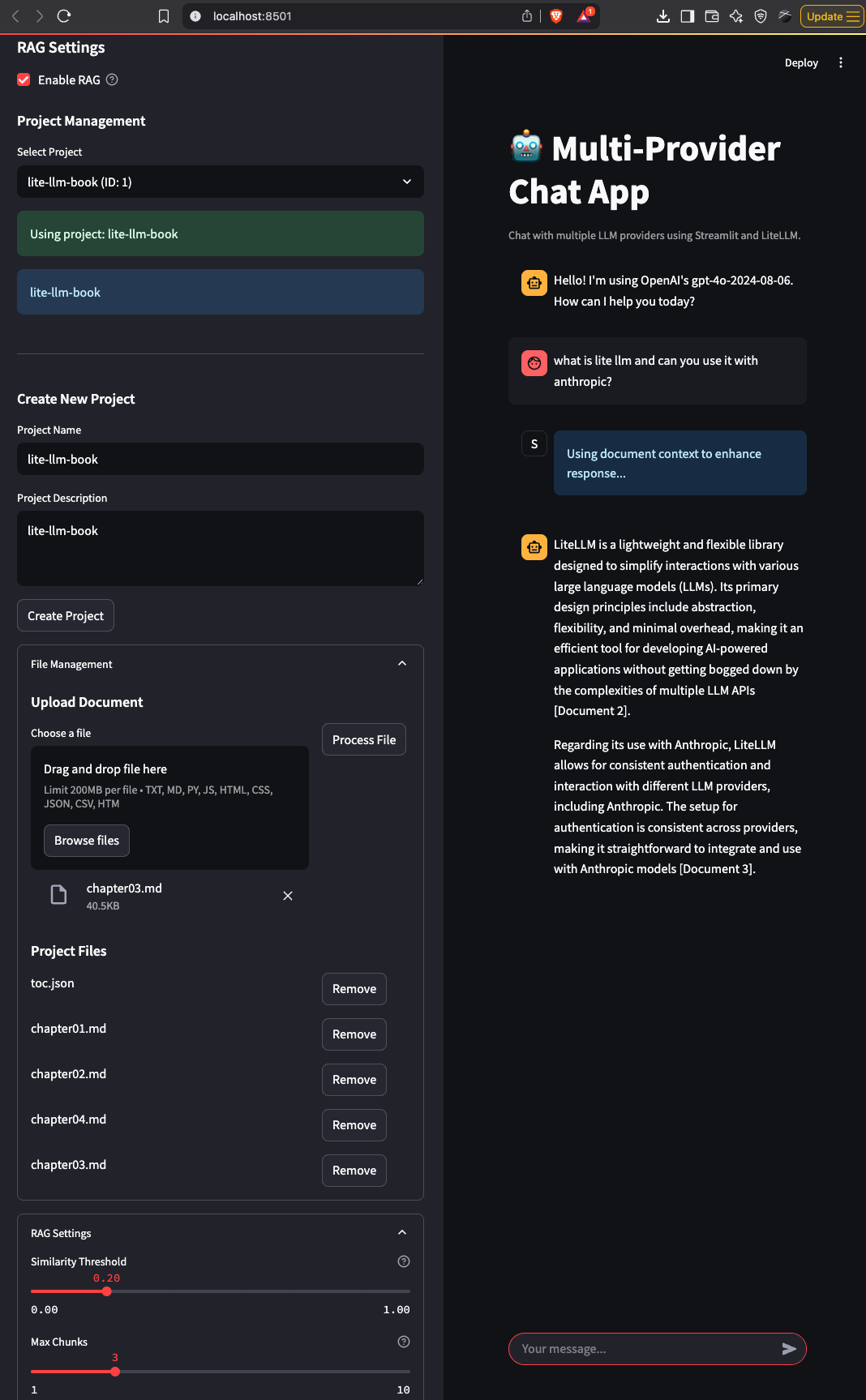
2. Retrieval-Augmented Generation (RAG): Context-Aware Conversations
One of the key enhancements we’ve added is RAG (Retrieval-Augmented Generation) capabilities. RAG allows the chat application to pull information from your documents and provide contextually relevant responses. This is useful for domain-specific applications where you want the LLM to have access to your proprietary information.
What is RAG and Why It Matters
RAG combines the generative capabilities of large language models with the ability to retrieve information from a knowledge base. Instead of relying solely on what the LLM was trained on, RAG allows the model to access external data sources, providing more accurate, up-to-date, and relevant responses.
Our vector-rag implementation provides a comprehensive system for:
- Storing and retrieving documents from a PostgreSQL database with pgvector
- Breaking documents into searchable chunks
- Creating and storing vector embeddings for semantic search
- Performing similarity searches to find relevant information
The RAG Architecture
Our RAG implementation uses a sophisticated architecture with several components:
1.Document Processing: The system processes documents, breaking them into manageable chunks 2.Embedding Generation: These chunks are converted into vector representations (embeddings) 3.Vector Storage: We use PostgreSQL with the pgvector extension to store and index these embeddings 4.Similarity Search: When a user asks a question, the system finds the most relevant document chunks 5.Context-Enhanced Generation: The retrieved information is provided to the LLM as context for generating a response
Implementation Details
The RAG system comprises several key components:
-Chunkers: Different strategies for breaking documents into meaningful pieces - LineChunker: Splits text based on line count - SizeChunker: Splits text based on character count - WordChunker: Splits text based on word count -Embedders: Classes that generate vector representations of text - OpenAIEmbedder: Uses OpenAI’s embedding API - SentenceTransformersEmbedder: Local embedding using Sentence Transformers - MockEmbedder: For testing purposes -Database Handlers: Manage the storage and retrieval of documents and embeddings - DBFileHandler: Stores files, chunks, and embeddings in PostgreSQL - ensure_vector_dimension: Ensures the database has the correct vector dimension
This architecture allows for flexible information retrieval, enabling the chat application to provide contextually rich responses based on your organization’s knowledge base.
Example Usage
Here’s how a simple query might flow through the RAG system:
- User asks: “What’s the implementation of the streaming feature in our application?”
- The query is converted to an embedding
- The system searches for similar embeddings in the database
- Relevant code snippets and documentation are retrieved
- The LLM generates a response explaining the streaming implementation, using the retrieved context
3. AWS Bedrock Integration: Enterprise-Grade Foundation Models
The third major enhancement is the integration with Amazon Bedrock, which provides access to a range of high-quality foundation models through a unified API. This integration expands our application’s capabilities by supporting models from providers like Anthropic (Claude), Meta (Llama), Amazon (Titan), and Cohere. This was addition to Ollama based models, Perplexity, Open AI, Anthropic and Google LLMs.
What is AWS Bedrock?
AWS Bedrock is Amazon’s managed service that makes foundation models from leading AI companies available through a unified API. It provides a secure way to access and use these models for enterprise applications.
Implementing Bedrock Support
Adding Bedrock support required creating a new provider class that interfaces with AWS’s API:
class BedrockProvider(LLMProvider):
"""Integration with Amazon Bedrock foundation models using both direct API and LiteLLM."""
def __init__(self, api_key: Optional[str] = None,
model: str = "anthropic.claude-3-sonnet-20240229-v1:0",
inference_profile: Optional[str] = None):
# Initialize AWS credentials from environment variables
self.aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
self.aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
self.aws_session_token = os.getenv("AWS_SESSION_TOKEN")
self.aws_region = os.getenv("AWS_REGION", "us-west-2")
# Initialize boto3 client for AWS Bedrock
# ...
The implementation includes support for both direct API calls using boto3 and integration through LiteLLM, providing flexibility based on the model requirements.
Available Models in Bedrock
Through Bedrock, our application now supports:
- Claude (from Anthropic)
- Llama 3 (from Meta)
- Titan (from Amazon)
- Command (from Cohere)
These models can be accessed by configuring AWS credentials in the application’s .env file, ensuring the AWS account has access to the selected models, and choosing the appropriate region where the models are available.
Benefits of Bedrock Integration
-Enterprise Security: AWS’s security and compliance capabilities -Simplified Billing: Consolidate AI model usage through your AWS account
- Model Choice: Access to multiple models without managing separate API keys -Scalability: AWS’s infrastructure for handling high-volume requests
Bringing It All Together: The Enhanced User Experience
These three enhancements work together to create an improved user experience. Let’s look at a typical workflow with our enhanced application:
- User loads the application and selects a provider (e.g., AWS Bedrock with Claude 3 Sonnet)
- User types a question related to company documentation
- The application:
- Searches the document database using RAG
- Retrieves relevant context
- Sends the query and context to the selected LLM
- Displays the response in real-time with streaming
Let’s see how this might look for a specific use case:
Use Case: Technical Documentation Search
Imagine a developer trying to understand a complex part of your company’s codebase:
- Developer asks: “How does our streaming implementation handle errors?”
- RAG system retrieves relevant code and documentation
- The query is sent to Claude 3 Sonnet via AWS Bedrock
- The developer sees the response stream in real-time, explaining how error handling works in the streaming code
This process is more efficient than manually searching through documentation or waiting for a complete response without any visual feedback.
Technical Implementation Highlights
Let’s look at some of the key technical implementations that make these features possible:
Streaming Implementation
Our streaming implementation uses asynchronous programming with Python’s async/await syntax, which allows the application to handle multiple streaming responses efficiently. The key components include:
-Asynchronous Generators: Each provider implements an asynchronous generator that yields text chunks as they’re generated -Callbacks: A callback mechanism updates the UI in real-time
- Error Handling: Error handling ensures a graceful fallback to non-streaming mode if issues occur -UI Updates: Streamlit’s UI elements are updated with each received chunk
Error Handling and Fallback Mechanisms
One important aspect of our implementation is the error handling. If streaming fails for any reason, the system gracefully falls back to the standard generation mode:
try:
# Try streaming approach
async for chunk in stream_response(...):
# Process streaming chunks
except Exception as e:
# Fall back to standard approach
response = await provider.generate_completion(...)
RAG Integration with PostgreSQL and pgvector
The RAG system uses PostgreSQL with the pgvector extension to store and query vector embeddings efficiently. Key SQL operations include:
- Creating a vector index for similarity search:
CREATE INDEX idx_chunks_embedding ON chunks
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 500);
- Querying for similar documents using vector operations:
# In Python, using SQLAlchemy:
similarity_expr = (literal(1.0, type_=Float) - distance_expr).label("similarity")
base_query = (
select(self.Chunk, similarity_expr)
.where(similarity_expr >= threshold_expr)
)
AWS Bedrock Authentication and Model Access
For AWS Bedrock, proper authentication is crucial. Our implementation checks for the presence of AWS credentials and provides helpful feedback if they’re missing:
def render_bedrock_settings():
"""Render AWS Bedrock-specific settings."""
# Get current AWS settings from environment variables
current_region = os.environ.get("AWS_REGION", "us-east-1")
# Allow the user to select a region
aws_regions = ["us-east-1", "us-east-2", "us-west-1", "us-west-2", ...]
# Check AWS credentials
aws_access_key = os.environ.get("AWS_ACCESS_KEY_ID", "")
aws_secret_key = os.environ.get("AWS_SECRET_ACCESS_KEY", "")
if not aws_access_key or not aws_secret_key:
st.warning("⚠️ AWS credentials not configured.")
else:
st.success("✅ AWS credentials configured")
Challenges and Solutions
Implementing these features wasn’t without challenges. Here are some of the issues we encountered and how we addressed them:
Challenge: Different Streaming Formats
Each LLM provider implements streaming differently, with varying formats and response structures. For example, Anthropic Claude returns content as message blocks, while OpenAI returns token-by-token updates.Solution: We created a unified streaming utility that abstracts away these differences, providing a consistent interface for all providers:
async def stream_response(
client,
messages: list,
stream_options: Dict[str, Any],
callback: Optional[Callable[[str], None]] = None
) -> AsyncGenerator[str, None]:
"""Stream a response from any LLM provider using LiteLLM."""
# Implementation handles provider-specific differences
Challenge: Vector Database Performance
When implementing RAG with large document collections, query performance became a concern for complex searches with multiple filters.
Solution: We optimized the database schema with appropriate indexes and implemented more efficient JSON handling for metadata filtering:
# Create GIN indexes for JSONB metadata
CREATE INDEX IF NOT EXISTS idx_chunk_metadata ON chunks USING gin (chunk_metadata);
# Create index for text search
CREATE INDEX IF NOT EXISTS idx_chunk_metadata_gin_ops
ON chunks USING gin (chunk_metadata jsonb_path_ops);
Challenge: AWS Bedrock Model Compatibility
Some models in AWS Bedrock, newer versions of Claude, required different API approaches and only worked with “on-demand throughput” rather than “provisioned throughput.”
Solution: We implemented dynamic detection of model capabilities and adjusted our API calls accordingly, with appropriate error handling and user feedback:
# For Claude 3.7, use direct boto3 calls
if self.use_direct_api:
return await self._generate_with_boto3(...)
else:
# For other models, use LiteLLM
return await self._generate_with_litellm(...)
Future Directions
While our current implementation adds value, there are several directions for future development:
1.Multi-Modal Support: Expanding beyond text to handle images and other media types 2. Fine-Tuning Integration: Allowing users to use fine-tuned models 3.Advanced RAG Techniques: Implementing advanced approaches like Hypothetical Document Embeddings (HyDE) and Multi-Vector Retrieval 4. Hybrid Retrieval with BM25, pgvector, embedding rerank, LLM Rubric Rerank & HyDE 5. Combine it with MPC 6. Use it in combination with keyword and meta-data search. 7.Enhanced Analytics: Providing insights into usage patterns and model performance
Design of the application
1. Project Overview
This project consists of two main components:
1.Multi-Provider Chat Application: A Streamlit-based chat interface that enables users to interact with multiple Large Language Model (LLM) providers through a unified interface. It supports OpenAI, Anthropic Claude, Google Gemini, Perplexity, Ollama (for local models), and AWS Bedrock. 2. Vector-RAG (Retrieval-Augmented Generation) System: A system that enhances the chat application with context-aware responses by retrieving relevant information from a document database. It uses vector embeddings stored in PostgreSQL with pgvector for semantic search capabilities.
Purpose and Functionality
The system solves several core problems:
- Unified LLM Access: Provides a single interface to interact with multiple AI providers, allowing users to switch between different models and services. -Context-Aware Responses: Enhances AI responses with relevant information from a document database using RAG technology. -Real-Time Interaction: Implements streaming responses to show AI outputs as they’re generated, improving user experience. -Conversation Management: Allows saving, loading, and managing conversations across different AI providers. -Enterprise Integration: Supports AWS Bedrock for organizations that prefer to use Amazon’s infrastructure for AI services. -Local Model Support: Integrates with Ollama to enable running open-source models locally for privacy and reduced API costs.
2. Features
Features
- Multi-Provider Support
- Connect to multiple LLM providers (OpenAI, Anthropic, Google, Perplexity, AWS Bedrock)
- Run local models through Ollama
- Switch between providers/models seamlessly during conversations
- Conversation Management
- Maintain conversation history across provider switches
- Save, load, and delete conversations
- Generate conversation titles automatically
- Export conversations as text files
- Document Management and RAG
- Process and store documents in a vector database
- Break documents into chunks for improved retrieval
- Generate vector embeddings for semantic search
- Search documents based on similarity to queries
- Include relevant document context in LLM prompts
- Response Streaming
- Display LLM responses in real-time as they’re generated
- Provide fallback mechanisms if streaming fails
- Show visual indicators during streaming
- Provider-Specific Settings
- Configure model-specific parameters (temperature, context size)
- Handle provider-specific authentication requirements
- Adjust parameters based on model capabilities
- AWS Bedrock Integration
- Connect to AWS Bedrock service for accessing foundation models
- Manage AWS authentication and region settings
- Check available models in the user’s AWS account
3. Technology Stack
Programming Languages
-Python: Primary language for both the chat application and vector-RAG system
Frameworks and Tools
-Streamlit: Web framework for building the user interface -PostgreSQL: Database for storing vectors, documents, and conversation data -pgvector: PostgreSQL extension for vector similarity search -SQLAlchemy: ORM for database operations -Pydantic: Data validation and settings management -Docker: Containerization for the PostgreSQL database
Libraries and Packages
Chat Application
- litellm: Unified interface for multiple LLM providers -python-dotenv: Environment variable management -requests: HTTP client for API calls -boto3: AWS SDK for Python, used for Bedrock integration -asyncio: Asynchronous programming support
Vector-RAG System
-pgvector: PostgreSQL extension for vector embeddings -sentence-transformers: Local embedding generation -openai: OpenAI API client for embeddings -torch: Backend for sentence-transformers -sqlalchemy: Database ORM -psycopg2-binary: PostgreSQL adapter for Python -jsonschema: JSON schema validation
4. Architecture and Design
Overall Architecture
The project uses a modular layered architecture with clear separation of concerns:
1.Presentation Layer: Streamlit web interface for user interaction 2.Service Layer: Provider classes that handle communication with various LLM APIs 3.Data Layer: Conversation storage and vector database components
Key Components for Chat Application
- LLM Provider System
- Abstract base class (
LLMProvider) defining the interface for all providers - Concrete implementations for each supported provider (OpenAI, Anthropic, etc.)
- Provider manager for initializing and managing provider instances
- Abstract base class (
- Conversation Management
Conversationclass for managing message historyConversationStoragefor saving/loading conversations to/from disk- UI components for displaying and managing conversations
- User Interface
- Chat display and input handling
- Provider settings sidebar
- Streaming response handling
- Utilities
- JSON processing utilities
- Streaming utilities
- Logging configuration
Key Components for Vector-RAG System
- Document Processing
Project,FileandChunkmodels for representing documents and their segments- Chunking strategies (
LineChunker,SizeChunker,WordChunker)
- Vector Embedding
Embedderinterface for generating vector embeddings- Implementations for different embedding providers (OpenAI, SentenceTransformers)
- Database Management
- PostgreSQL with pgvector extension
DBFileHandlerfor managing files, chunks, and embeddings- Query utilities for semantic similarity search
- Search and Retrieval
- Similarity search functionality
- Metadata filtering
- Pagination for search results
5. Diagram Generation
Flowchart: Main Chat Application Workflow
flowchart TD
A[User Opens Application] --> B[Initialize Providers]
B --> C[Select Provider and Model]
C --> D[Enter Message]
D --> E{Streaming Enabled?}
E -- Yes --> F[Stream Response in Real-time]
E -- No --> G[Generate Complete Response]
F --> H[Update Conversation History]
G --> H
H --> I{Save Conversation?}
I -- Yes --> J[Store Conversation to Disk]
I -- No --> D
%% Add RAG integration
D --> K{RAG Enabled?}
K -- Yes --> L[Search Vector Database]
L --> M[Retrieve Relevant Context]
M --> N[Add Context to Prompt]
N --> E
K -- No --> E
Class Diagram: LLM Provider System
classDiagram
class LLMProvider {
<<abstract>>
+generate_completion(prompt, output_format, options, conversation)
+generate_json(prompt, schema, options, conversation)
+generate_completion_stream(prompt, output_format, options, conversation, callback)
}
LLMProvider <|-- OpenAIProvider
LLMProvider <|-- AnthropicProvider
LLMProvider <|-- GoogleGeminiProvider
LLMProvider <|-- PerplexityProvider
LLMProvider <|-- OllamaProvider
LLMProvider <|-- BedrockProvider
class OpenAIProvider {
-api_key
-model
-client
+generate_completion()
+generate_json()
+generate_completion_stream()
-_generate_completion_gpt4_series()
-_generate_completion_o_series()
}
class AnthropicProvider {
-api_key
-model
-original_model_name
-client
+generate_completion()
+generate_completion_stream()
}
class GoogleGeminiProvider {
-api_key
-model
-client
+generate_completion()
+generate_completion_stream()
}
class PerplexityProvider {
-api_key
-model
-client
+generate_completion()
+generate_completion_stream()
-_validate_message_sequence()
-_is_online_model()
}
class OllamaProvider {
-model
-original_model_name
-base_url
-client
+generate_completion()
+generate_completion_stream()
}
class BedrockProvider {
-aws_access_key_id
-aws_secret_access_key
-aws_session_token
-aws_region
-original_model
-model
-inference_profile
-bedrock_runtime
-use_direct_api
+generate_completion()
+generate_completion_stream()
-_generate_with_boto3()
-_generate_with_litellm()
}
Class Diagram: Conversation Management
classDiagram
class Conversation {
+id: str
+title: Optional[str]
+messages: List[Message]
+created_at: datetime
+updated_at: datetime
+add_message(content, message_type, role)
+to_llm_messages()
+ensure_alternating_messages()
}
class Message {
+timestamp: datetime
+message_type: MessageType
+content: str
+role: str
+to_llm_message()
}
class MessageType {
<<enum>>
INPUT
OUTPUT
}
class ConversationStorage {
-storage_dir: Path
+save_conversation(conversation)
+load_conversation(conversation_id)
+delete_conversation(conversation_id)
+list_conversations()
+generate_conversation_title(conversation)
+update_conversation_title(conversation_id, new_title)
}
Conversation "1" *-- "many" Message
Message *-- MessageType
ConversationStorage -- Conversation : manages >
Class Diagram: Vector-RAG System
classDiagram
class Chunker {
<<abstract>>
+chunk_text(file)
}
class LineChunker {
-chunk_size
-overlap
+chunk_text(file)
}
class SizeChunker {
-chunk_size
-overlap
+chunk_text(file)
}
class WordChunker {
-chunk_size
-overlap
+chunk_text(file)
}
class Embedder {
<<abstract>>
-model_name
-dimension
+get_dimension()
+embed_texts(texts)
}
class OpenAIEmbedder {
-client
-batch_size
+embed_texts(chunks)
}
class SentenceTransformersEmbedder {
-model
-batch_size
+embed_texts(chunks)
}
class MockEmbedder {
+embed_texts(texts)
}
class FileHandler {
<<abstract>>
+create_project(name, description)
+add_file(project_id, file_model)
+get_file(project_id, file_path, filename)
+delete_file(file_id)
+list_files(project_id)
+search_chunks_by_text(project_id, query_text, page, page_size, similarity_threshold)
}
class DBFileHandler {
-engine
-embedder
-Session
-chunker
+session_scope()
+get_or_create_project(name, description)
+add_chunks(file_id, chunks)
+add_file(project_id, file_model)
+search_chunks_by_embedding(project_id, embedding, page, page_size, similarity_threshold, file_id, metadata_filter)
}
Chunker <|-- LineChunker
Chunker <|-- SizeChunker
Chunker <|-- WordChunker
Embedder <|-- OpenAIEmbedder
Embedder <|-- SentenceTransformersEmbedder
Embedder <|-- MockEmbedder
FileHandler <|-- DBFileHandler
DBFileHandler --> Chunker : uses
DBFileHandler --> Embedder : uses
Sequence Diagram: Chat Interaction with Streaming
sequenceDiagram
participant User
participant UI as Streamlit UI
participant Provider as LLM Provider
participant Conversation as Conversation Manager
User->>UI: Enter message
UI->>Provider: generate_completion_stream(prompt)
activate Provider
Provider->>Provider: Initialize streaming
Provider-->>UI: Start streaming chunks
loop For each chunk
Provider-->>UI: Send text chunk
UI->>UI: Update display with chunk
end
Provider-->>UI: Complete streaming
deactivate Provider
UI->>Conversation: Add message to history
Conversation->>Conversation: Update conversation
UI->>UI: Display full response
Sequence Diagram: RAG Integration Flow
sequenceDiagram
participant User
participant UI as Streamlit UI
participant VectorDB as Vector Database
participant LLM as LLM Provider
User->>UI: Ask question
UI->>VectorDB: search_chunks_by_text(query)
activate VectorDB
VectorDB->>VectorDB: Generate query embedding
VectorDB->>VectorDB: Find similar chunks
VectorDB-->>UI: Return relevant chunks
deactivate VectorDB
UI->>UI: Combine query with context
UI->>LLM: generate_completion(enhanced_prompt)
activate LLM
LLM->>LLM: Process with context
LLM-->>UI: Return response
deactivate LLM
UI->>UI: Display response to user
Schema Diagram: Vector-RAG Database
erDiagram
PROJECTS {
int id PK
string name
string description
datetime created_at
datetime updated_at
}
FILES {
int id PK
int project_id FK
string filename
string file_path
string crc
int file_size
datetime last_updated
datetime last_ingested
datetime created_at
}
CHUNKS {
int id PK
int file_id FK
string content
vector embedding
int chunk_index
jsonb chunk_metadata
datetime created_at
}
PROJECTS ||--o{ FILES : contains
FILES ||--o{ CHUNKS : divided_into
Entity Relationship Diagram
erDiagram
Project ||--o{ File : contains
File ||--o{ Chunk : contains
Conversation ||--o{ Message : contains
Project {
int id
string name
string description
datetime created_at
datetime updated_at
}
File {
int id
int project_id
string filename
string file_path
string crc
int file_size
datetime created_at
}
Chunk {
int id
int file_id
string content
vector embedding
int chunk_index
jsonb metadata
datetime created_at
}
Conversation {
string id
string title
datetime created_at
datetime updated_at
}
Message {
datetime timestamp
enum message_type
string content
string role
}
User Journey Diagram
journey
title Chat Application User Journey
section Initial Setup
Log in to Application: 5: User
Select LLM Provider: 3: User
Configure Provider Settings: 3: User
section Basic Chat
Type Question: 5: User
View Streaming Response: 4: User
Follow Up Question: 5: User
section Working with RAG
Ask Domain-Specific Question: 5: User
Review Sources from Documents: 4: User
Refine Query Based on Context: 4: User
section Conversation Management
Save Conversation: 5: User
Load Previous Conversation: 4: User
Export Conversation: 3: User
section Advanced Features
Try Different Providers: 4: User
Compare Model Responses: 5: User
Use AWS Bedrock Integration: 3: User
Use Case Diagram
graph TD
subgraph Actors
User([User])
end
subgraph Chat Application
UC1[Chat with LLMs]
UC2[Select Provider/Model]
UC3[Manage Conversations]
UC4[Configure Provider Settings]
UC5[View Streaming Responses]
UC6[Export Conversations]
end
subgraph RAG System
UC7[Search Knowledge Base]
UC8[Add Documents to KB]
UC9[Receive Context-Enhanced Responses]
UC10[Filter by Metadata]
end
User --> UC1
User --> UC2
User --> UC3
User --> UC4
User --> UC5
User --> UC6
User --> UC7
User --> UC8
User --> UC9
User --> UC10
Mind Map
mindmap
root((Multi-Provider<br>Chat App))
LLM Providers
OpenAI
GPT-4o
GPT-4.1
Anthropic
Claude 3 Opus
Claude 3 Sonnet
Claude 3 Haiku
Google Gemini
Perplexity
Ollama
Local Models
Custom Settings
AWS Bedrock
Claude Models
Llama Models
Titan Models
Features
Streaming Responses
Conversation Management
Save/Load
Export
Auto-Title
RAG Integration
Vector Search
Document Chunking
Metadata Filtering
Provider Settings
Temperature Control
Context Length Adjustment
UI Components
Chat Interface
Sidebar Settings
Conversation History
Provider Selection
Vector-RAG System
Database
PostgreSQL
pgvector Extension
Embedding Generation
OpenAI Embeddings
Sentence Transformers
Chunking Strategies
Line-based
Size-based
Word-based
Architecture Diagram
graph TD
subgraph "User Interface Layer"
A[Streamlit Web Interface]
B[Sidebar Controls]
C[Chat Display]
end
subgraph "Service Layer"
D[Provider Manager]
E[LLM Provider Interface]
F[Conversation Manager]
G[Streaming Controller]
H[Vector Search API]
end
subgraph "Provider Implementations"
I[OpenAI]
J[Anthropic]
K[Google Gemini]
L[Perplexity]
M[Ollama]
N[AWS Bedrock]
end
subgraph "Data Layer"
O[Conversation Storage]
P[PostgreSQL + pgvector]
Q[Document Processor]
R[Embedding Generation]
end
subgraph "External Services"
S[OpenAI API]
T[Claude API]
U[Gemini API]
V[Perplexity API]
W[Local Ollama Server]
X[AWS Bedrock Service]
end
A <--> B
A <--> C
B <--> D
C <--> F
C <--> G
D <--> E
E <--> I
E <--> J
E <--> K
E <--> L
E <--> M
E <--> N
F <--> O
G <--> E
I <--> S
J <--> T
K <--> U
L <--> V
M <--> W
N <--> X
H <--> P
H <--> Q
H <--> R
E <--> H
6. Directory Structure
Chat Application Directory Structure
chat/
├── ./
│ └── pyproject.toml # Project metadata and dependencies
├── test/ # Test directory
│ ├── test_all_providers_streaming.py # Test streaming functionality
│ ├── test_bedrock.py # Test AWS Bedrock provider
│ ├── test_bedrock_access.py # Check AWS Bedrock model access
│ ├── test_litellm_streaming.py # Test litellm streaming independently
│ ├── test_stream_anthropic.py # Test Anthropic streaming
│ ├── test_stream_openai.py # Test OpenAI streaming
│ ├── test_stream_openai_json.py # Test OpenAI JSON streaming
│ ├── test_streaming.py # General streaming tests
│ └── chat/ # Additional chat tests
├── docs/ # Documentation
│ └── images/ # Images for documentation
└── src/ # Source code
└── chat/ # Main application code
├── __init__.py # Package initialization
├── app.py # Main application entry point
├── ai/ # LLM provider implementations
│ ├── __init__.py
│ ├── anthropic.py # Anthropic Claude provider
│ ├── bedrock.py # AWS Bedrock provider
│ ├── google_gemini.py # Google Gemini provider
│ ├── llm_provider.py # Abstract provider interface
│ ├── ollama.py # Ollama local model provider
│ ├── open_ai.py # OpenAI provider
│ ├── perplexity.py # Perplexity provider
│ └── provider_manager.py # Provider management
├── conversation/ # Conversation management
│ ├── __init__.py
│ ├── conversation.py # Conversation and message models
│ └── conversation_storage.py # Conversation persistence
├── ui/ # UI components
│ ├── __init__.py
│ ├── chat.py # Chat display and input handling
│ ├── chat_utils.py # Chat-specific utilities
│ ├── conversation_manager.py # UI for conversation management
│ └── sidebar.py # Sidebar UI components
└── util/ # Utility functions
├── __init__.py
├── json_util.py # JSON processing utilities
├── logging_util.py # Logging configuration
└── streaming_util.py # Streaming helper functions
Vector-RAG Directory Structure
vector-rag/
├── ./
│ └── pyproject.toml # Project metadata and dependencies
├── tests/ # Test directory
│ ├── conftest.py # Test configuration
│ ├── embeddings/ # Embedder tests
│ │ ├── test_embedders.py # General embedder tests
│ │ ├── test_openai_embedder.py # OpenAI embedder tests
│ │ └── test_sentence_transformers_embedder.py # Local embedder tests
│ ├── integration/ # Integration tests
│ │ └── test_ingestion.py # Document ingestion testing
│ ├── chunking/ # Chunking strategy tests
│ │ ├── test_line_chunker.py # Line-based chunker tests
│ │ ├── test_size_chunker.py # Size-based chunker tests
│ │ └── test_word_chunker.py # Word-based chunker tests
│ ├── db/ # Database tests
│ │ ├── test_add_chunk_direct.py # Chunk addition tests
│ │ ├── test_db_file_handler.py # File handler tests
│ │ ├── test_dimension_utils.py # Vector dimension utilities tests
│ │ ├── test_semantic_search.py # Semantic search tests
│ │ └── test_semantic_search_with_metadata.py # Metadata filtering tests
│ └── api/ # API tests
│ └── test_search_api.py # Search API tests
├── db/ # Database scripts
│ ├── scripts/ # Database management scripts
│ │ ├── create_index.py # Index creation script
│ │ └── import_data.py # Data import script
│ └── sql/ # SQL scripts
│ └── init.sql # Database initialization SQL
├── environment/ # Environment configuration
├── src/ # Source code
├── scripts/ # Utility scripts
│ ├── init_db.py # Database initialization script
│ └── run_example.py # Example usage script
└── vector_rag/ # Main package
├── __init__.py # Package initialization
├── config.py # Configuration management
├── logging_config.py # Logging setup
├── model.py # Core data models
├── embeddings/ # Embedding generation
│ ├── __init__.py
│ ├── base.py # Base embedder interface
│ ├── mock_embedder.py # Mock embedder for testing
│ ├── openai_embedder.py # OpenAI embeddings
│ └── sentence_transformers_embedder.py # Local embeddings
├── chunking/ # Document chunking strategies
│ ├── __init__.py
│ ├── base_chunker.py # Base chunker interface
│ ├── line_chunker.py # Line-based chunking
│ ├── size_chunker.py # Size-based chunking
│ └── word_chunker.py # Word-based chunking
├── db/ # Database operations
│ ├── __init__.py
│ ├── base_file_handler.py # Abstract file handler
│ ├── db_file_handler.py # Concrete file handler
│ ├── db_model.py # Database models
│ └── dimension_utils.py # Vector dimension utilities
└── api/ # API interfaces
└── __init__.py # API package initialization
Main Components Description
Chat Application
1.src/chat/ai/: Contains implementations for different LLM providers. Each provider (OpenAI, Anthropic, etc.) implements the abstract LLMProvider interface, allowing for consistent interaction regardless of the backend service.
2.src/chat/conversation/: Manages conversation history and persistence. The Conversation class represents a chat session, while ConversationStorage handles saving and loading conversations from disk.
3.src/chat/ui/: Houses the Streamlit UI components. The chat.py module handles chat display and user input, while sidebar.py manages provider selection and settings.
4.src/chat/util/: Contains utility functions for JSON processing, logging configuration, and streaming response handling.
5.src/chat/app.py: The main entry point that ties all components together, defining the Streamlit application flow.
Vector-RAG System
1.src/vector_rag/chunking/: Contains different strategies for breaking documents into chunks. These include LineChunker (line-based), SizeChunker (character-based), and WordChunker (word-based).
2.src/vector_rag/embeddings/: Houses the embedding generation components. It includes OpenAIEmbedder for using OpenAI’s API and SentenceTransformersEmbedder for local embedding using HuggingFace models.
3.src/vector_rag/db/: Manages database operations. The DBFileHandler class handles file, chunk, and embedding storage in PostgreSQL, while dimension_utils.py ensures the vector dimensions are properly configured.
4.src/vector_rag/api/: Provides a simplified API for integrating the RAG system with other applications, such as the chat interface.
5.src/vector_rag/model.py: Defines the core data models, including Project, File, and Chunk.
6.src/vector_rag/config.py: Handles configuration management, loading settings from environment variables and .env files.
Key Features and Implementation Highlights
1.Provider Abstraction: The LLMProvider interface abstracts away the differences between various LLM services, allowing for consistent interaction regardless of the backend.
2.Streaming Support: All providers implement generate_completion_stream for real-time, token-by-token response generation, with proper error handling and fallback mechanisms.
3.AWS Bedrock Integration: The BedrockProvider class enables access to foundation models through AWS’s infrastructure, supporting both direct API calls and LiteLLM integration.
4.Semantic Search: The vector-RAG system implements similarity search with metadata filtering, allowing for contextually relevant document retrieval.
5.Flexible Chunking: Multiple chunking strategies enable optimal document processing for different content types, with configurable chunk sizes and overlap.
6.Local and Remote Embeddings: Support for both OpenAI’s API and local SentenceTransformers models for generating vector embeddings.
7.Conversation Management: Comprehensive features for saving, loading, and managing conversation history, with automatic title generation.
8.Provider-Specific Settings: Tailored settings for each provider, including specialized options for Ollama’s local models and AWS Bedrock configuration.
This project demonstrates an approach to integrating multiple LLM providers with a RAG system, creating a powerful and flexible chat application with context-aware responses.
Conclusion
The enhancements we’ve made to our multi-provider chat application—streaming responses, RAG capabilities, and AWS Bedrock integration—transform it from a simple chat interface into a powerful knowledge access tool. These features work together to provide a more responsive, informative, and flexible experience for users across a variety of use cases.
By combining the generative capabilities of leading LLMs with the context-awareness of RAG and the real-time feedback of streaming responses, through a clean interface, our application demonstrates the potential of modern AI tools for practical applications.
The complete source code for this project is available on GitHub at https://github.com/RichardHightower/chat, with the RAG implementation at https://github.com/SpillwaveSolutions/vector-rag.
Whether you’re building internal tools for your organization, exploring AI capabilities, or looking for a flexible way to interact with multiple LLM providers, we hope this implementation provides a starting point for your own projects.
About the Author
Rick Hightower is an AI specialist with a background in ML and Data Engineering. He has a passion for AI and natural language processing. He has extensive experience in building scalable, distributed systems and is currently focused on AI integration in enterprise applications.
Connect with Rick on LinkedIn or follow his articles on Medium.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting