November 28, 2024
Trail Talk: Rick and Chris Review Machine Learning
On a crisp Saturday morning, Rick and Chris were hiking up a favorite mountain trail, the sun casting a golden glow through the trees. Backpacks strapped on and water bottles filled, they set a steady pace up the incline.
Rick: adjusting his backpack straps
“Chris, you’ve been diving deep into machine learning lately. I keep hearing terms like supervised and unsupervised learning, but I’m a bit fuzzy on what they actually mean.”
Chris: puts on his mentor hat
“Well, think of supervised learning like our kickboxing coach guiding us through techniques. We have labeled data—input-output pairs—that the model learns from.”
Rick: “So it’s like when Coach shows us the correct form for a punch, and we practice until we get it right?”
Chris: “Pretty much…unsupervised learning, on the other hand, is like us exploring new hiking trails without a map. The model tries to find patterns and groupings in the data without any guidance.”
Delving into Linear Regression
As they continued uphill, the conversation flowed as smoothly as the gurgling creek beside them.
Rick: “I’ve heard about linear regression. How does that fit into all this?”
Chris: “Fit. Good word choice! Linear regression is a supervised learning technique used to predict an outcome based on one or more predictors, usually resulting in a single numeric guess.”
Rick: “Like estimating how many calories we’ll burn on this hike based on distance and elevation gain?”
Chris: “Uh huh. We could use past hike data to create a model that predicts calorie burn. I bet that watch on your wrist with the app on your phone is a good starting point for our dataset. The cost function helps us measure how accurate our predictions are compared to actual values.”
“Another example - imagine you’re trying to predict house prices based on their size. You could plot size on one axis and price on the other, and put a dot for each data point. Then linear regression comes in to find the best fitting straight line through that data. That line represents our model, and its equation allows us to predict the price for any house size.”
“It’s a simplification, but it’s a powerful starting point.”
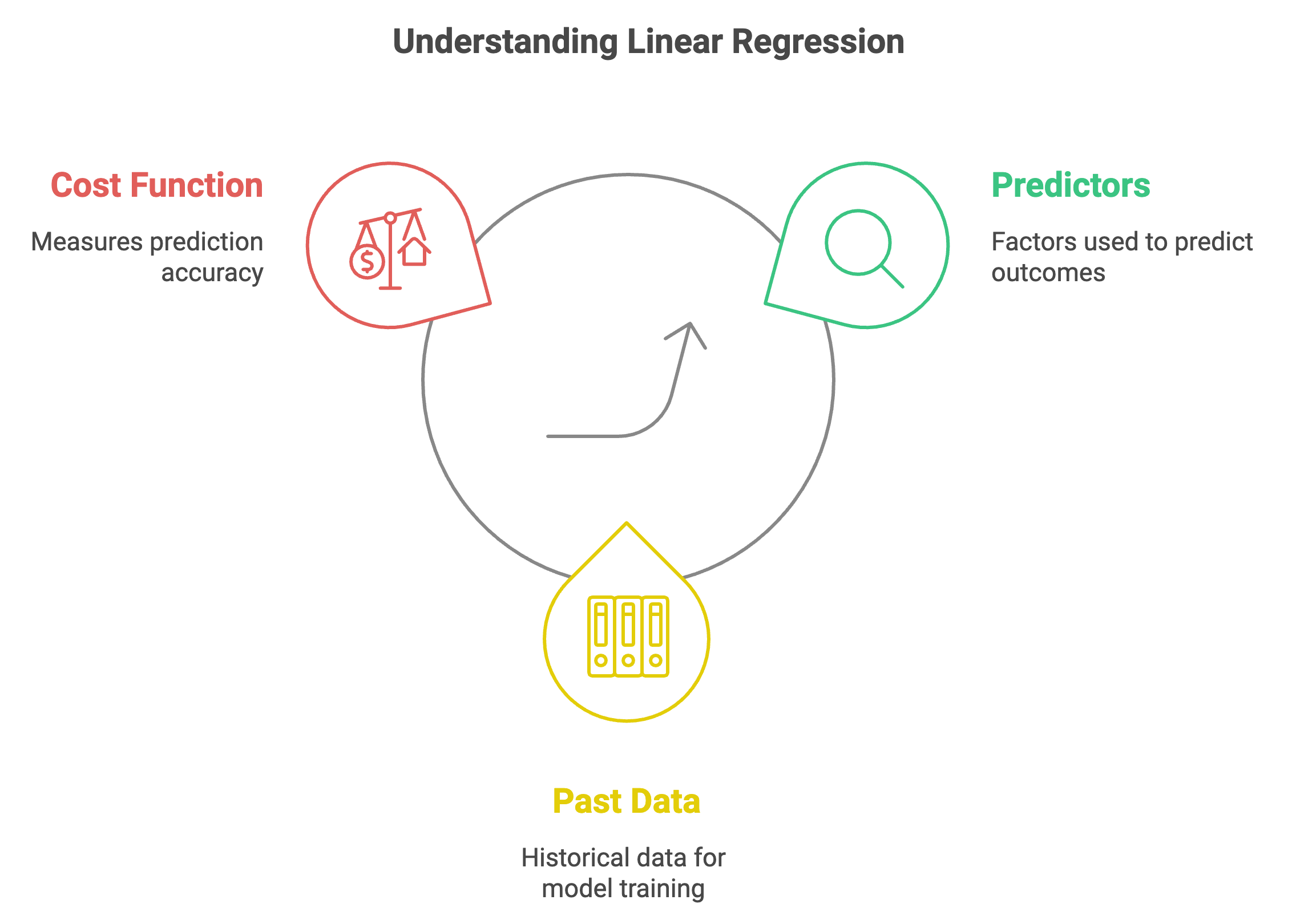
Rick: “And we minimize this cost function to improve our model?”
Chris: “You’ve got it. Understanding the concept of the cost function is crucial here. It’s really at the core of how algorithms learn.”
Rick: “How so?”
Chris: “Think of the cost function as a measure of how well our line fits the data points. A lower cost means a better fit.”
“Picture that line shifting around, trying to get as close as possible to relative center of all those data points. That’s what the algorithm is striving for.”
“And the algorithm that actually does the line shifting to find the best fit, the lowest cost, is called gradient descent.”
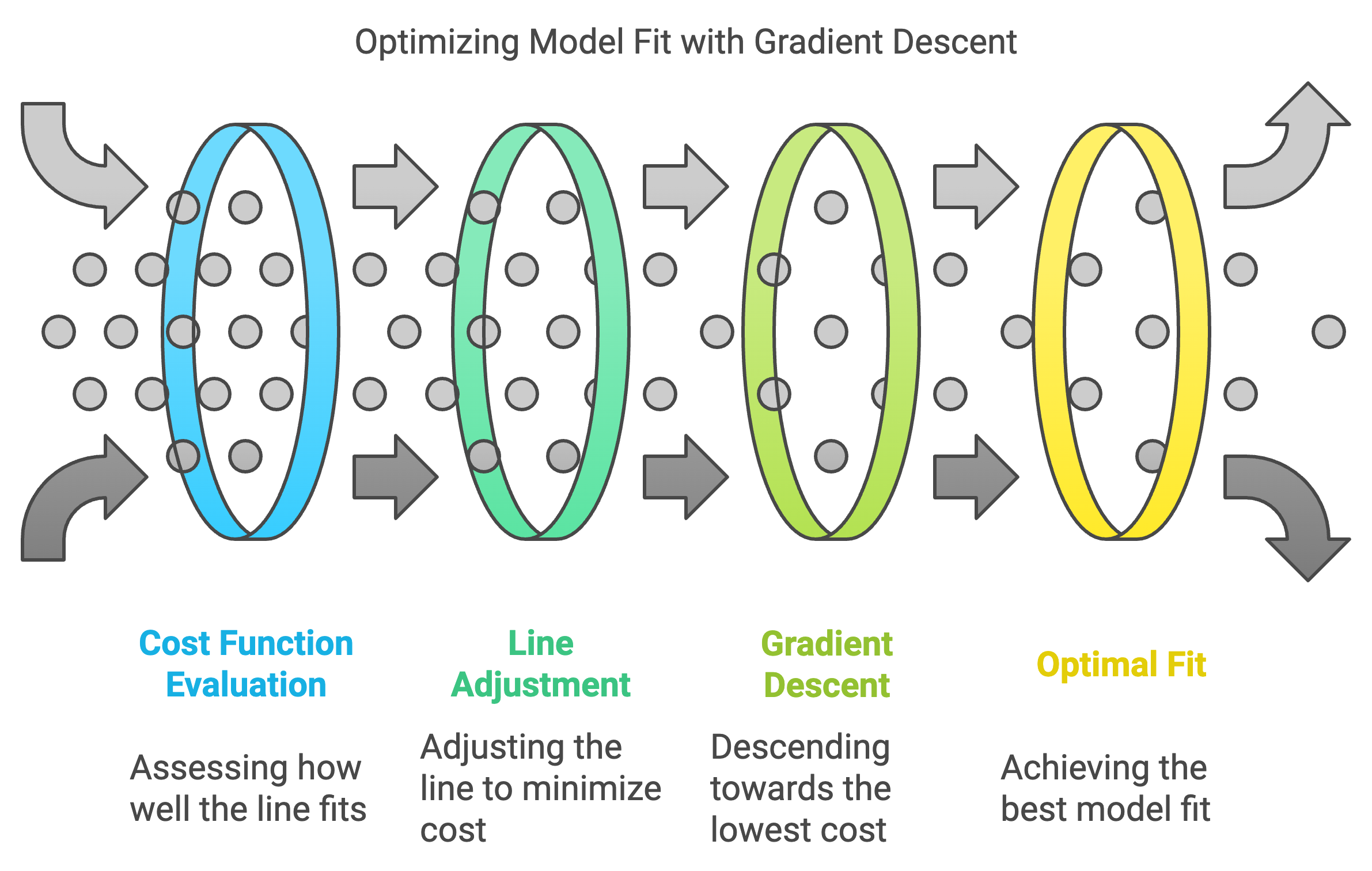
Rick: “It’s like a hiker carefully descending a mountain, taking small steps in the steepest downward direction.”
Chris: “Exactly.”
Rick: “Kind of a dangerous way to hike I guess, but the line is just on a graph, in no apparent danger. So - what guides those steps is the gradient, which points in the direction of the steepest descent.”
Chris: “It gets a bit into calculus territory, but the essence is beautifully intuitive.”
Rick: “It is.”
Chris: “Even massive, complex AI models ultimately rely on this foundational algorithm to optimize their performance.”
“But here’s where it gets really interesting.”
“It’s not just about finding any fit.”
“It’s about finding the Goldilocks fit that’s just right.”
Understanding Underfitting and Overfitting
They reached a scenic overlook and paused to catch their breath.
Rick: “But sometimes models get it wrong, right? What’s that about?”
Chris: “Right, imagine trying to fit a straight line to a data set that clearly curves.”
Rick: “Because the model is too simple. Real data is probably rarely linear. So, linearity misses the nuances of the data.”
Chris: “Good job! That’s underfitting. Maybe like trying to describe a beach ball - sphere - using only a 2d rectangles.”
Rick: “And overfitting?”
Chris: “That’s when the model gets a little too enthusiastic and tries to perfectly match every single data point, even the noise and outliers.”
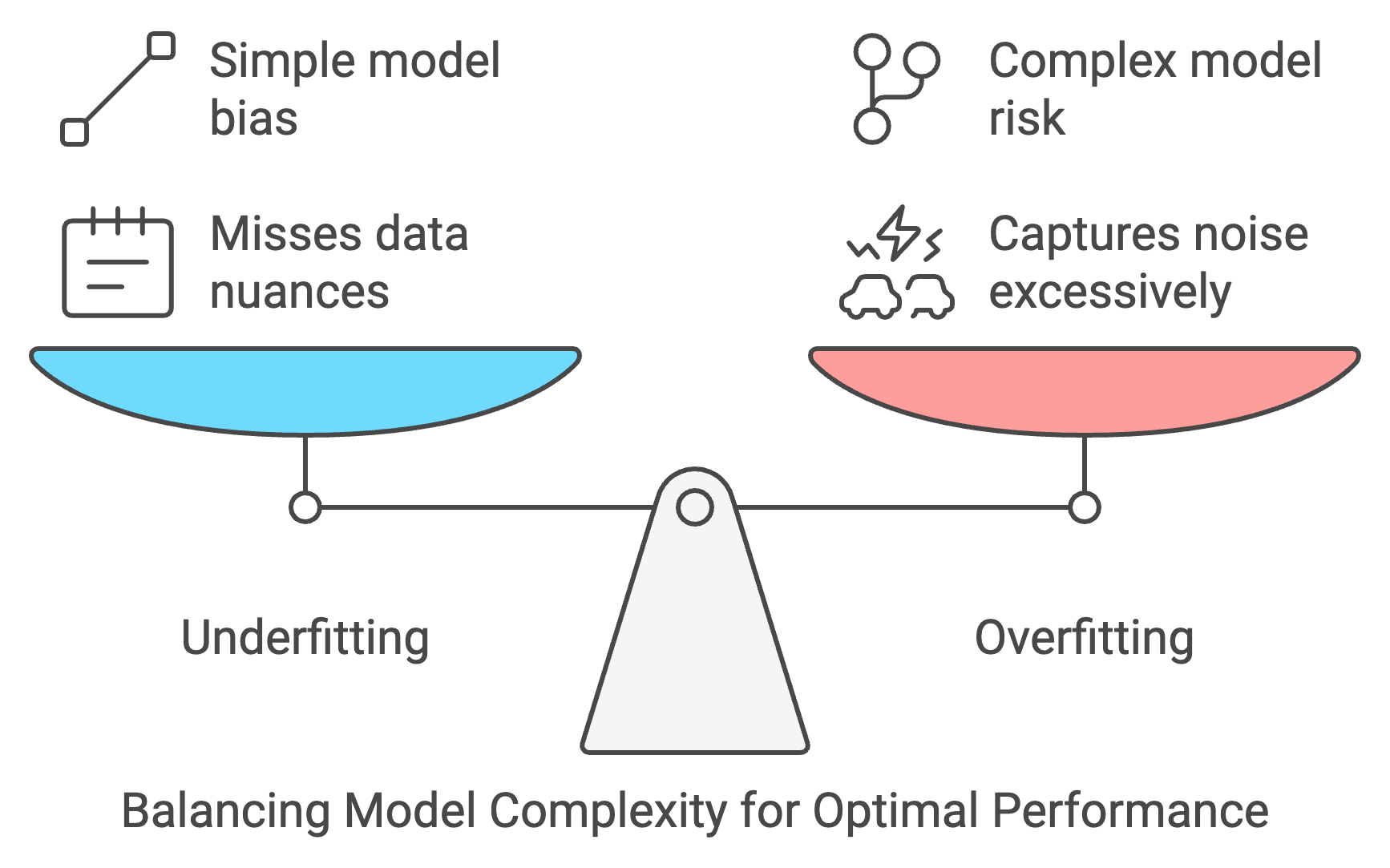
Rick: “So it’s like memorizing every twist and turn of a single trail and getting lost when we hike a new one?”
Chris: Laughs, “Yes! It’s a classic case of too much of a good thing. Lets consider regularization.”
Rick: “What exactly is regularization?”
Chris: “Well, imagine a model that’s supposed to detect fraudulent credit card transactions.”
Rick: “Yeah.”
Chris: “An overfitted model might create a super intricate decision boundary that perfectly classifies every transaction in the training data as either fraud or legitimate.”
“But then when you use it to assess new transactions, it could be completely off the mark.”
Rick: “And that’s a problem, especially in finance where accuracy is crucial.”
Chris: “Absolutely.”
Rick: “So how do we strike that balance, that sweet spot between underfitting and overfitting?”
Chris: “Exactly where regularization comes in. It’s a technique that helps prevent overfitting by adding a penalty to our cost function for having overly complex models.”
Rick: “It’s like adding a constraint that says, ‘Hey, model, I know you’re eager to learn all the intricate details of this data, but let’s keep things a bit simpler and more generalizable.’”
Chris: “Right. It encourages the model to find a solution that’s not only accurate on the training data but also robust enough to perform well on new data.”
Rick: “So in a way, regularization is like the voice of reason, preventing the model from going down the rabbit hole of complexity. I could have used some regularization quite a few times in my personal life.”
Chris: Laughs,
“No doubt. And it’s not just theoretical. Regularization is widely used by engineers and data scientists. It’s one of those tools that bridges the gap between theory and practice, ensuring that our models aren’t just good on paper but actually work in the real world.”
Embracing Vectorization for Efficiency
They resumed hiking, the trail now leveling out.
Rick: “I’m guessing a lot of data is required to get the generalizability users would be looking for - and processing all this data and calcs sounds time-consuming. Is there a way to make it more efficient?”
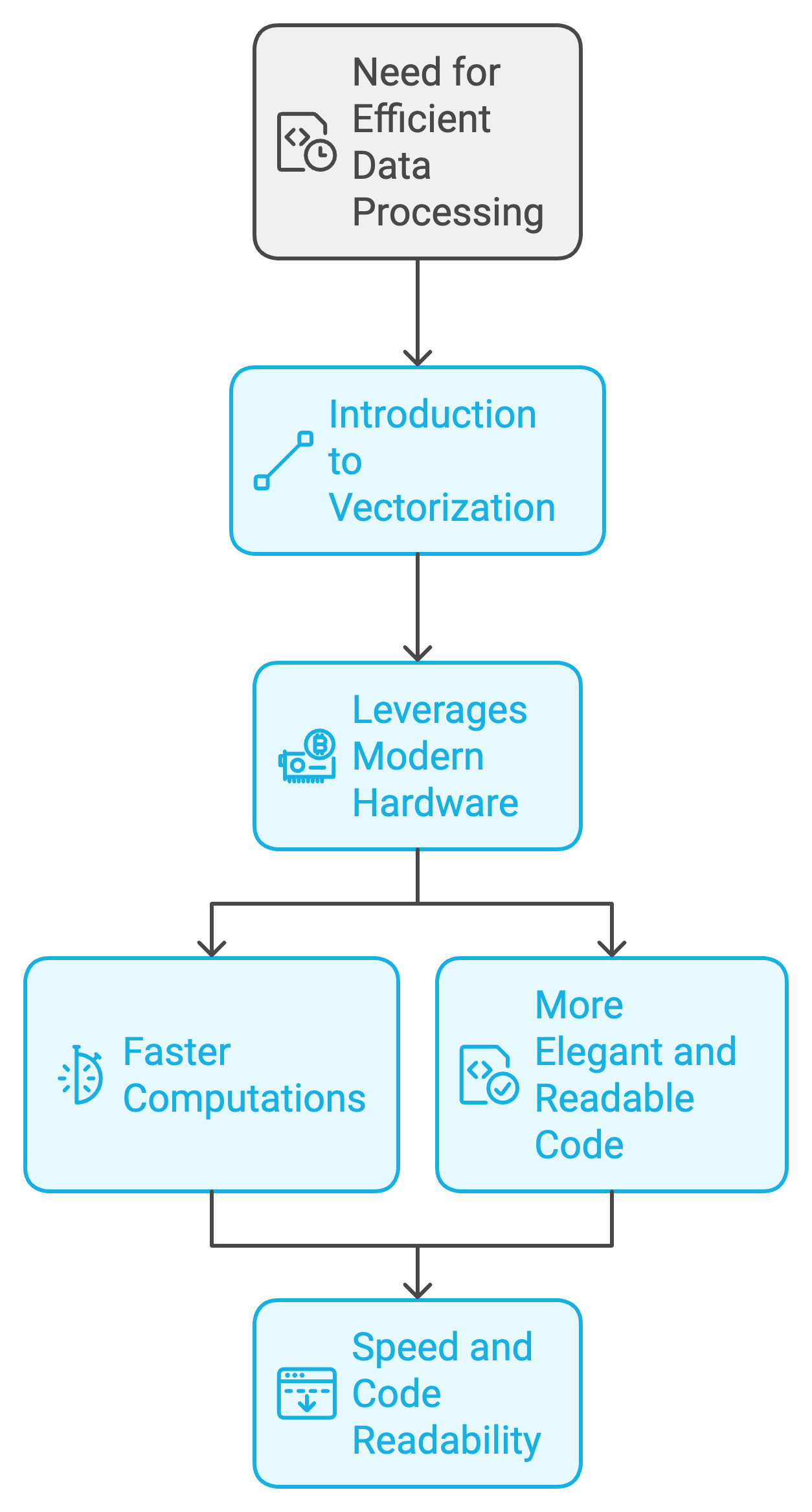
Chris: “Absolutely. Vectorization is key. It allows us to perform operations on entire arrays of data simultaneously, rather than one element at a time.”
Rick: “Kind of like when we do circuit training—working multiple muscle groups at once?”
Chris: “That’s a great analogy! It uses modern hardware capabilities, making computations much faster.”
Rick: “I sort of get what you’re saying, but I’m still not sure what’s the big idea here?”
Chris: “Well, think of it this way. Imagine you have a list of numbers and you need to perform the same operation on each number, like adding five to each one.”
Rick: “Right, I’d probably just loop through the list and add five to each element one by one.”
Chris: “Exactly. And that’s fine for small lists, but what if you’re dealing with millions or even billions of numbers? Looping through each one individually can take a really long time.”
Rick: “And we’re dealing with large amounts of data here. Okay, I’m starting to see the problem, especially when we’re talking about the massive data sets common in AI.”
Chris: “Right, and that’s where vectorization shines. Instead of processing each element sequentially, vectorization allows us to perform the operation on the entire list, or vector, simultaneously. So it’s like performing a million additions in one fell swoop.”
Rick: Giggles,
“Seems magical. How do we cast this spell, oh great one?”
Chris: Laughs,
“This is no magic, though it feels like it. Vectorization uses the parallel processing capabilities of modern hardware, especially GPUs. These specialized processors are designed to handle massive amounts of data simultaneously.”
Rick: “I see. We’re essentially harnessing the power of parallel processing to make our computations lightning fast. So it’s not just for gaming! Sounds like we should buy some NVIDIA and AMD stock.”
Chris: “Well, I’m not the best investor, and my collection of Star Wars action figures never had the payout I expected especially after my dog chewed most of their heads off. But yes, GPUs are crucial in AI. Also, vectorized code tends to be more elegant and readable. And it’s not just about speed either, is it?”
Rick:
“It isn’t? What else?”
Chris:
“No, it’s also about elegance and code readability.”
“Vectorized code tends to be much more concise and easier to understand than code that relies on loops and iterations. You need to think in vectors.”
Rick:
“I am the Borg. I think in vectors. You will be assimilated. So it’s a win-win.”
Rick starts walking mechanically and sticks his arms out like a Zombie and begins menacing approaching Chris chanting “you will be assimilated” - only to strike a low hanging branch across the forehead.
Chris: Chuckles
“You are a clown. We get faster computations and cleaner code. It is a win-win.”
Rick:
“What’s not to love about vectors? And nothing about you is fast. Let’s race down the next hill”.
Exploring Logistic Regression and Decision Boundaries
The trail began to descend, and they picked up their pace, which turned into a full trail run. Chris, the lighter and more agile of the two, easily navigated the hill, while Rick had to slow down to maintain his balance. Running down hill with backpacks was not a great idea. Rick is full of bad ideas. Chris can be impressionable.
Panting and somewhat out of breath, Rick begins to speak.
Rick: “What about when we need to make yes-or-no decisions? Is linear regression still useful?”
Chris: “For classification tasks, we use logistic regression. It predicts probabilities of outcomes that are interpreted to be categorical.”
Rick: “Logistic regression? What’s that?”
Chris: “It can be a bit tricky at first because it actually deals with classification, even though it has ‘regression’ in the name.”
Rick: “So if we’re deciding whether to bring rain gear based on weather data?”

Chris: “Exactly. Logistic regression uses the sigmoid function to output probabilities between 0 and 1.”
Rick: “And the decision boundary is like the cutoff point where we decide if it’s worth carrying extra weight for the rain gear?”
Chris: “Spot on! It’s the threshold at which the predicted probability indicates one class over another. While linear regression predicts a continuous output, logistic regression is all about predicting categories or classes.”
Rick: “So this goes back to the sigmoid function that squashes any number into a range between zero and one, allowing us to interpret the output as a probability.”
Chris: “Exactly. So if the output is 0.7, we can say there’s a 70% chance of the event happening, like a transaction being fraudulent.”
Rick: “And to really grasp how logistic regression makes its decisions, we need to understand the concept of decision boundaries.”
Chris: “Precisely. In our credit card fraud detection example, the decision boundary would be the line that separates legitimate transactions from fraudulent ones.”
Rick: “So it’s like the dividing line that the algorithm uses to classify the data.”
Chris: “Exactly. Transactions farther away from that boundary are classified with more confidence.”
Rick: “It’s like the algorithm is saying, ‘This transaction is definitely legitimate,’ or ‘This one is most likely fraudulent.’”
Chris: “That’s a great way to put it. Visualizing that decision boundary can really help us understand how the algorithm is working and what factors are influencing its decisions.”
Discussing Convergence
They continued along the trail, the sun beginning to dip lower in the sky.
Rick: “Chris, earlier you mentioned gradient descent when we talked about linear regression. How do we know when it should stop going down the mountain? Is there a way to tell if it’s done improving? Does it ‘reach the creek’ or just keep going down?”
Chris: “Great question! That’s where the concept of convergence comes into play.”
Rick: “Convergence? Sounds like a sci-fi movie. What’s that all about?”
Chris: “Convergence refers to the point during training when the model’s performance stops improving significantly. In terms of gradient descent, it’s when the cost function reaches its minimum or levels off.”
“In your analogy, we’d monitor our altitude to see if we’re descending. We can plot the cost function during training to see if it’s decreasing."
Rick: “And if it stops decreasing, or even starts to increase, that’s a sign we’ve reached the optimal point?”
Chris: “Yes, or it could indicate an issue like a learning rate that’s too high, causing the model to overshoot the minimum. Monitoring convergence helps us ensure that our model is training properly.”
Rick: “That makes sense. So by checking for convergence, we can avoid wasting time on training that’s no longer beneficial.”
Chris: “Nailed it.”
Exploring Feature Scaling
As they walked, Rick noticed the trail’s terrain changing from rocky to smooth soil.
Rick: “You know, the changing terrain got me thinking. In machine learning, do we need to adjust our models based on relative magnitudes in the different data features?”
Chris: “Funny you mention that. Yes, we often need to perform feature scaling.”
Rick: “Feature scaling? What’s the intuition behind that?”
Chris: “Well, imagine we’re using different features to predict something, like the elevation gain, body weight, heart rate, ambient temperature and distance of hikes to predict calorie burn. If one feature ranges from 1 to 10 and another ranges from 100 to 10,000, the model might give more importance to the feature with the larger values.”
Rick: “Even if the smaller-scale feature is just as important?”

Chris: “Exactly. By scaling the features, we ensure they all contribute equally to the model. It’s like leveling the playing field.”
Rick: “So it’s like adjusting the units so that each feature has a fair shot at influencing the outcome.”
Chris: “Right. Common methods include normalization and standardization, which adjust the features to a common scale without distorting differences in the ranges of values.”
Rick: “Got it. So feature scaling can significantly impact the performance of our models.”
Chris: “Absolutely. It’s a subtle but crucial step in the preprocessing of data.”
Diving into Feature Engineering
They approached a fork in the trail, and Chris pulled out a map.
Chris: “Sometimes, choosing the right path is like selecting the right features for our models. Perhaps we determine that one feature like body temperature is heavily correlated with heart rate and having both just complicates the model without adding more ‘signal’. We can drop one. It is really about select the right feature which helps to create the simplest model”
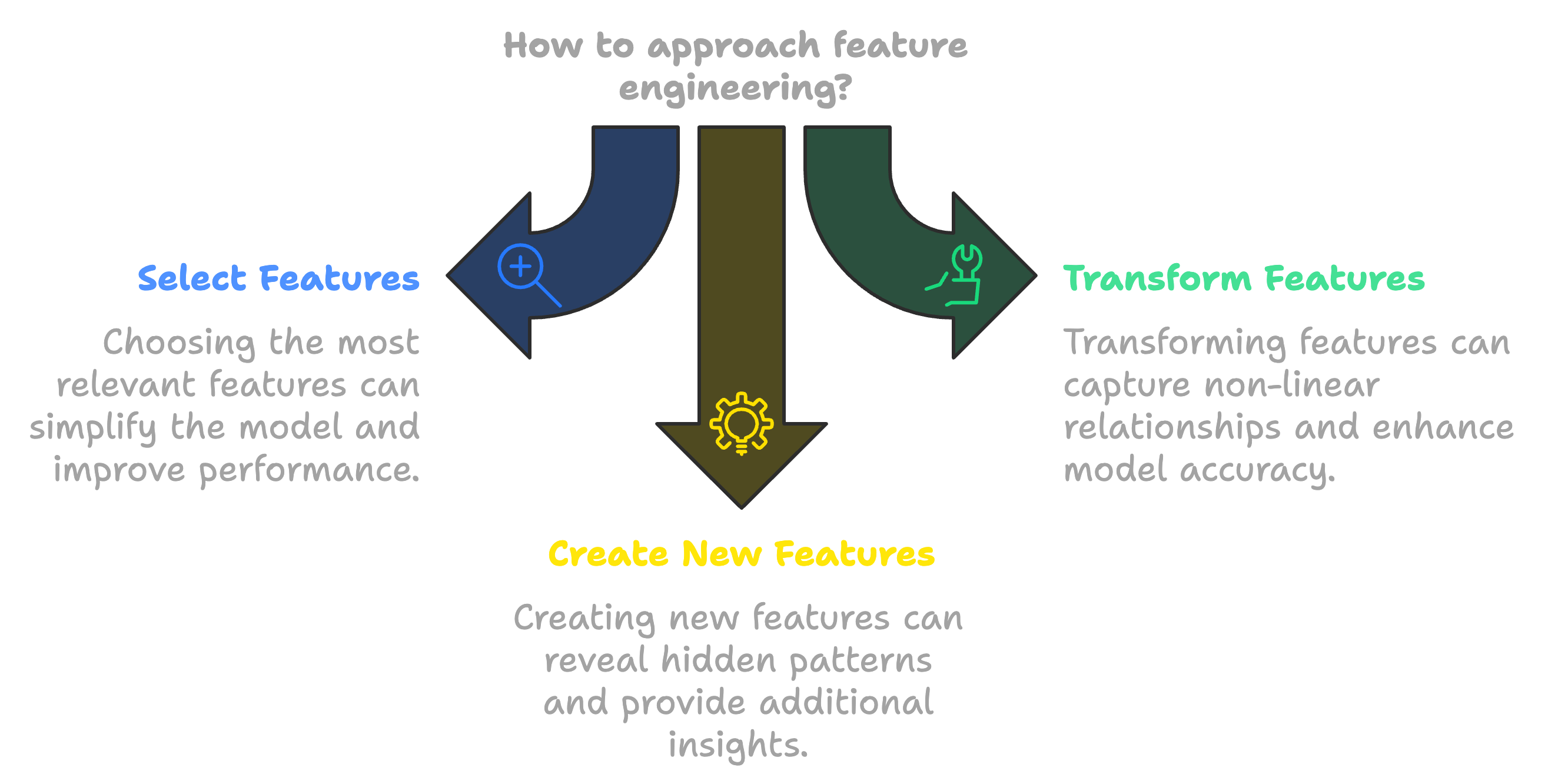
Rick: “Are you talking about feature engineering?”
Chris: “Exactly. Feature engineering is the process of selecting, transforming, and creating features to improve model performance. Finding the greatest ratio of signal to noise gives us better predictors.”
Rick: “So it’s like adding shortcuts or scenic routes to our hike to make it more enjoyable or efficient.”
Chris: “That’s a great analogy. By creating new features or combining existing ones, we can capture underlying patterns in the data that weren’t apparent before.”
Rick: “Would you say its like combining elevation gain and distance to create a difficulty score for our hikes?”
Chris: “Precisely. Sometimes we might even transform features, like using logarithms or polynomial terms, to capture non-linear relationships. Like how that 40 pounds in your rucksack makes you 2x slower than me.”
Rick: Smiles
“Sure. So you win a race but I get abs. Fair trade in my book! So - feature engineering sounds like it is both an art and a science, requiring creativity and domain knowledge.”
Chris: “You nailed it. And a little intuition too. It’s one of the areas where human insight can significantly enhance a machine learning model’s performance.”
Rick: “That’s exciting. It shows how our understanding of the problem can directly impact the effectiveness of the solution.”
Chris: “Absolutely. Feature engineering bridges the gap between data and actionable insights.”
Rick Reflects on Their Conversation
As they reached the end of the trail, the parking lot coming into view, Rick looked thoughtful as he continued to catch his breath.
Rick: “You know, Chris, this machine learning stuff is pretty fascinating. It’s like uncovering hidden patterns in everything we do.”
Chris: “I’m glad you think so. There’s so much potential to apply these concepts to areas we’re passionate about.”
Rick: “Maybe we could use machine learning to optimize our workout routines or even plan our hikes more efficiently.”
Chris: “I’d love to explore that with you. Data-driven training could take us to the next level. But its worth noting that the narrower the problem/question, the better our models can be. That is why the weather man still gets it wrong all the time.”
Rick: “So we start with something simple like how we might predict calorie burn based on just a few variables like time, distance, velocity and weight. See about adding things like hours of sleep, other mileage, hydration and all the other things later. So its like feature engineering but with iterative practices.”
Chris: “Yeah that’s one way to go about it. But there’s also distributed parallel training, Bayesian feature selection, hyperparameter optimization and other interesting techniques.”
Rick: “Ouch. My brain just started to hurt. Lets talk about TV shows we like now.”
Wrapping Up
They loaded their gear into the car, feeling both physically and mentally invigorated.
Rick: Grinning, “Thanks for the crash course. I feel like I’ve exercised my brain as much as my legs today.”
Chris: “Anytime! Next hike, we can delve into neural networks if you’re up for it.”
Rick: Laughs, “I’ll make sure to fuel up beforehand. Can’t wait!”
Conclusion
Through their shared love of the outdoors and fitness, Rick and Chris found a way to blend physical activity with intellectual curiosity. Chris’s expertise in machine learning opened up new avenues for exploration, and Rick’s eagerness to learn turned a simple hike into a journey of discovery. Together, they realized that the principles of machine learning could enhance not just their understanding of data, but also their everyday lives. This story and other like it reflect the friendship of real people, but any real reflection on real events is mostly coincidental, and is a literary device for educational and entertainment purposes.
Glossary of Terms
| Term | Definition |
|---|---|
| Machine Learning | A subset of artificial intelligence where models improve their performance on tasks through experience and data without being explicitly programmed. |
| Supervised Learning | A type of machine learning where the model is trained on labeled data, learning the mapping from inputs to outputs. |
| Unsupervised Learning | A type of machine learning that deals with unlabeled data, where the model tries to find patterns and relationships within the data on its own. |
| Linear Regression | A supervised learning algorithm used to predict a continuous outcome based on one or more input variables (predictors). |
| Predictors | Independent variables or features used by a model to make predictions about the target variable. |
| Cost Function | A function that measures the error between the model’s predictions and the actual outcomes; used to optimize the model parameters. |
| Gradient Descent | An optimization algorithm that iteratively adjusts model parameters to minimize the cost function. |
| Underfitting | A modeling error that occurs when a model is too simple and fails to capture the underlying trend of the data. |
| Overfitting | A modeling error where a model is too complex and captures the noise in the data as if it were a true pattern, reducing its performance on new data. |
| Regularization | Techniques used to reduce overfitting by adding additional information or constraints to a model, often by penalizing complexity. |
| Vectorization | The process of converting algorithms from operating on a single value at a time to operating on a set of values (vectors) simultaneously for efficiency gains. |
| Logistic Regression | A statistical model used for binary classification tasks that predicts the probability of an outcome that can have two values. |
| Classification | The process of predicting the category or class of given data points within machine learning. |
| Sigmoid Function | A mathematical function that maps any real-valued number into a value between 0 and 1, often used to model probabilities in logistic regression. |
| Decision Boundary | A hypersurface that separates data points of different classes in the feature space. |
| Convergence | The process during training when a model’s performance stops significantly improving, indicating it has learned the underlying pattern. |
| Feature Scaling | Methods used to normalize the range of independent variables or features, ensuring they contribute equally to the model. |
| Feature Engineering | The process of selecting, transforming, and creating variables (features) to improve the performance of a machine learning model. |
| Data-Driven Training | An approach to training or decision-making that relies on data analysis and patterns rather than intuition or personal experience. |
| Neural Networks | Computational models inspired by the human brain’s network of neurons, used in machine learning to recognize patterns and make decisions. |
| Hardware Capabilities | The processing power and features provided by physical computing components like CPUs and GPUs that can be leveraged for computational tasks. |
Author Bios
Chris Mathias is a versatile technologist and thought leader with extensive experience in software engineering, AI implementation, and cloud architecture. He has a proven track record of developing innovative solutions, such as consumer-friendly medical document generation and rapid data pipeline development, by using large language models and advanced cloud infrastructures. Chris is dedicated to mentoring teams, fostering the adoption of cutting-edge technologies, and integrating AI-driven efficiencies into workflows.


Beyond his technical expertise, Chris is an accomplished author and musician. His creative works include the sci-fi novella “An Awakening,” which explores the rise of a powerful artificial intelligence and its profound impact on humanity, and the re-released novel “Deader,” set in a world divided between privileged sky cities and desolate ground. Chris’s unique blend of technical acumen and creative expression reflects his commitment to exploring the intersections of technology, society, and the human experience.
Chris was also a machine learning and AI tech lead at a fortune 100, a distinguished engineer which is a director level role.
Rick Hightower is a seasoned software architect and technology innovator with over three decades of experience in enterprise software development with a strong background in AI/ML. As a prominent figure in the Java ecosystem, he has authored multiple books and technical articles, while contributing to various open-source projects, and specifications. Recently, Rick has focused on AI implementation and data engineering, using his expertise to develop innovative solutions that bridge traditional enterprise systems with cutting-edge AI technologies. Rick is also known for his contributions to microservices architecture and his work in cloud computing platforms. He is a 2017 Java Champion and former tech executive at a fortune 100.
Beyond his technical roles, Rick is an active mentor and technology evangelist, often speaking at conferences and writing about the intersection of AI, data engineering, and enterprise software development. His practical approach to technology implementation and his ability to bridge complex technical concepts with real-world applications have made him a respected voice in the technology community.
His recent experience includes the following:
In 2024:
- Data engineering and large scale ETL using AWS Glue, AWS EventBridge for integration platform. Wrote deployment scripts in AWS CDK and Terraform CDK as well as Helm to deploy AWS MSK (Kafka), AWS EKS (K8s), Lambda, etc.
- Worked on AI assisted document data extraction then used GenAI to produce artifacts in minutes that took months using AWS BedRock.
- Implemented an AI based Subject Matter Expert (SME) system using various Large Language Models (LLMs), Vector Databases, and frameworks, including LLamaIndex, ChatGPT, Perplexity, and Claude.
- Developed a React frontend, a middleware layer in Go, and a Retrieval-Augmented Generation (RAG) Agent LLM layer in Python using LLamaIndex.
- Deployed the system on Google Cloud Platform (GCP) using AlloyDB, GCS buckets, and Google Cloud Run. System indexed documents dropped into GCP as well as git code repositories.
- Focused on the RAG Agent system, deployment, system integration, UI, and middleware.
- Transitioned the initial Flask-based RAG system to GRPC and Google Pub/Sub for scalability.
- Worked on Auth0 integration from client to backend services using the JWT tokens
- Wrote a tool to detect various types of questions and answer them in real time during a meeting
- Wrote a tool to summarize meetings, pull out decisions, topics and actions items.
- Collaborated with a startup on their AR/VR system, focusing on scaling the backend services in Azure.
- Wrote TypeScript CDK Terraform deployment scripts to deploy services to Azure Kubernetes Service (AKS).
- Utilized Azure-managed Redis and Azure-managed MySQL for data storage and caching.
- Deployed a total of 7 services and developed a custom client discovery mechanism to expose services and configurations to clients in Azure.
- Conducted load testing and implemented horizontal pod scaling and vertical scaling to ensure system performance and reliability in AKS/K8s.
- Configured the Application Gateway with the AGIC (Application Gateway Ingress Controller) component running in AKS to expose services using Layer 7 load balancing.
- Leveraged AKS/Azure load balancing for Layer 4 load balancing to distribute traffic effectively and enabled UDP based load balancing.
- Worked on Auth0 integration from client to backend services using the JWT tokens.
2023:
- Utilized AI and prompt engineering to evaluate legal documents, extract entities, and perform thorough analysis at a fraction of the cost compared to a legal team.
- Created a demo for investors and potential clients to showcase the automated process.
- AI development using Open AI API to generate documentation and analyze sensitive documents. Wrote entity extraction and classification tools and did complex work with Chain of thought and synthetic prompt as a form of CoT. Used HyDE to enhance search with AI using Text Embeddings and vector sorting. Set up vector databases to analyze code bases and product documentation. Wrote tool to do complex work with feedback validation to AI—improved output from 70% accuracy to 90% accuracy. The tool can do in four hours from what used to take 3 months of effort. 2023
- Served as Acting Senior Director of backend eCommerce site, providing engineering management consulting focused on risk mitigation and staff augmentation.
- Worked with AWS, Scala, Java, JavaScript, COTS, and platform re-engineering.
- Employed AI and prompt engineering to evaluate legacy systems, write documentation/diagrams, and extract requirements.
- Engaged in recruiting, site reliability, disaster recovery, business continuity, and mentoring.
- Developed software for a security company site using AWS, CI/CD, React, Element, Kubernetes, Java, and Terraform.
- Wrote integration pieces between a company and the US government
- Utilized AI and prompt engineering to document code with documentation and diagrams.
- Worked with embedded systems, cloud technologies, and hold a security clearance.
Articles
- Articles Overview
- Rick and Chris Review Machine Learning
- Streamlit Adventures Part 5 Article
- Streamlit Part 4: Form Validation Part 2
- Streamlit Part 3 - Form Validation Part 1
- Advanced SQL Techniques for ETL
- Streamlit Part 2: Layouts, Components, and Graphs
- Conversation About Streamlit While Walking in the Park
- PrivateGPT and LlamaIndex
- OpenAI’s Latest Developments
- AI-Powered Knowledge Base for Product Managers
- ChatGPT at Scale on Azure Cloud
- Prompt Engineering with CoT and Synthetic Prompts Part 2
- Understanding LLMs and Using Chain of Thoughts
- Meta’s Llama 2 AI Model
- ChatGPT Embeddings and HyDE for Improved Search
Apache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting