May 1, 2025
Tired of LLMs hallucinating instead of citing the exact information you need? Discover the secret sauce that combines traditional keyword search with cutting-edge vector retrieval, then tops it all off with two levels of rerank. Unlock the power of hybrid retrieval and transform your RAG systems. Don’t let your search stack be the weak link—read on to level up your game!
Stop the Hallucinations: Hybrid Retrieval Using BM25, pgvector, Embedding Rerank, LLM Rerank, and HyDE
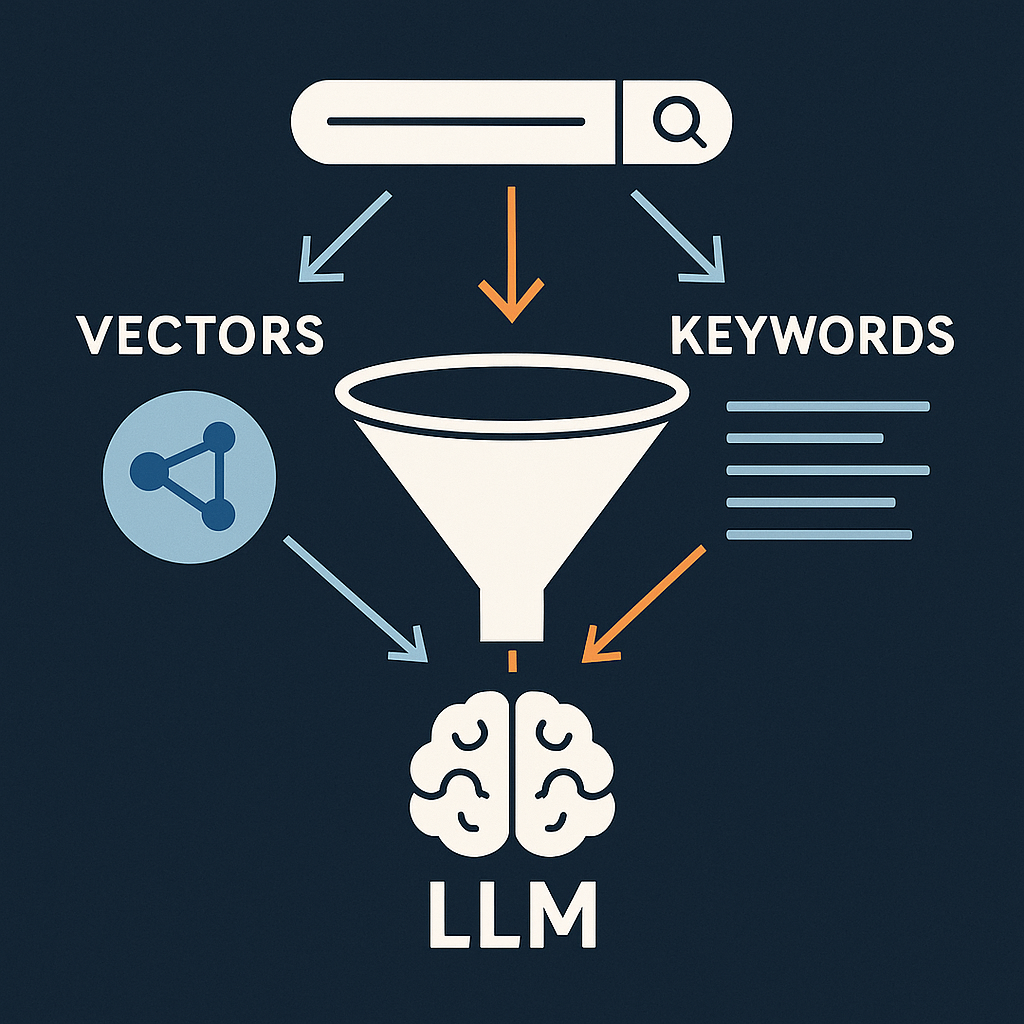
Let’s explore hybrid retrieval methods combining BM25 and vector search with rerank to reduce LLM hallucinations, enhance relevance, and improve RAG systems with practical techniques and Python implementations.
In this comprehensive guide, we’ll cut through the complexity and demonstrate practical solutions that combine multiple retrieval techniques. You’ll learn how to orchestrate BM25, vector search, and reranking in a way that’s both powerful and production-ready. Whether you’re building a documentation search engine or a customer support bot, these battle-tested patterns will help you deliver more accurate, reliable results.
A conversational guide to mixing BM25, pgvector, rerank, and HyDE in a Retrieval-Augmented Generation pipeline
Hook: You’ve embedded every document, fine-tuned your model, and still the LLM hallucinates instead of citing the exact paragraph you know is in the knowledge base. Before you blame the model, let’s talk about your search stack.
If you build Retrieval-Augmented Generation (RAG) systems, you already juggle prompts, embeddings, chunk sizes, and rerankers. Yet the quiet hero—or culprit—is often the retriever itself. In this article we’ll walk through a pragmatic, engineer-friendly recipe that layers traditionalBM25keyword ranking on top of semantic vector search, powered by Postgres extensions you probably already run in production.
Along the way we’ll:
- Demystify HyDE-style “generate-first, retrieve-second” search
- Break down BM25 and PostgreSQL full-text search (FTS) in plain English
- Show a drop-in Python snippet that merges vector and BM25 hits, then reranks them
- Close with grab-and-go tricks—query expansion, MMR diversification, metadata boosts—to squeeze even more relevance out of your corpus.
Setting the table: key terms in sixty seconds
| Jargon | Friendly meaning |
|---|---|
| RAG (Retrieval-Augmented Generation) | Pipeline that fetches reference passages and feeds them into an LLM so it can answer with grounding context. |
| HyDE (Hypothetical Document Embeddings) | Instead of embedding the user’s raw question, you first let an LLM draft a short hypothetical answer, then embed that draft for retrieval. |
| Vector search / pgvector | Finding the nearest document embeddings (dense vectors) to your query embedding using distance metrics like cosine similarity. |
| BM25 | A decades-old “bag-of-words” ranking formula that scores documents by how often query terms appear, normalized by doc length and term rarity. |
| PostgreSQL FTS | Postgres’s built-in inverted-index search; under the hood it tokenizes, removes stop-words, stems words, and stores them in a tsvector column. |
| Hybrid retrieval | Combining lexical (BM25/keyword) and semantic (vector) scores, then reranking to get the best of both worlds. |
| Embedding Rerank | Embedding rerank is a way to improve search results by giving each piece of content a new score. It works by comparing how similar the meaning of each search result is to the user’s search query. To do this comparison, it uses special number patterns called embeddings that represent the meaning of text. |
| LLM Rubric Rerank | LLM rerank is a scoring method that uses AI to grade how well each search result answers your question. Think of it like having a smart teacher review student essays - the AI reads each piece of content and gives it a score based on how well it matches what you’re looking for. It follows a specific set of rules (called rubrics) to make these decisions fairly and consistently. |
(Skimmed those? You’re ready.)
1. When pure embeddings fall short
Dense vectors are brilliant at fuzzy matching—synonyms, paraphrases, “that thing I can’t name” queries. But they occasionally:
- Missexactphrases (“ACID compliance,”
org.postgresql.Driver) - Struggle withrare tokens(internal code names, SKUs)
- Over-prioritize feel over facts (returning broad background instead of the line you need)
Engineers notice this gap most when writing technical docs, code samples, or regulatory language where a single word matters. Enterlexical search: the OG keyword index that never forgets an exact term. Sometimes vector is better. Sometimes keywords and full text pull back a better result.
2. A quick detour into BM25—minus the math headache
At its heart, BM25 rewards a document when:
- Theterm appears ofteninside it (term frequency)
- The term israrein the overall corpus (inverse document frequency)
- The document isn’t absurdly long (length normalization)
Two tunable knobs (k1 and b) control how aggressively frequency and length matter. Out of the box, Apache Lucene (and therefore Elasticsearch) uses BM25 with k1≈1.2, b≈0.75.
If you enjoy math or headaches, and who doesn’t enjoy a good headache.

Postgres can do this too
Everything BM25-ish lives in Postgres FTS:
ALTER TABLE docs
ADD COLUMN body_tsv tsvector
GENERATED ALWAYS AS (to_tsvector('english', body)) STORED;
CREATE INDEX idx_docs_fts ON docs USING GIN (body_tsv);
to_tsvector:
- Lowercases
- Drops stop-words (“the,” “and”)
- Applies the Snowball stemmer (“running”→“run”)
- Stores positions so
ts_rank_cd()can score relevance
That’s it—you now have BM25-style ranking inside your relational database.
3. HyDE: drafting your own query booster
Why rely only on the user’s question? WithHyDEyou let the LLM pretend it already knows the answer, embed that pretend answer, then retrieve. The generated draft usually contains synonyms, domain phrases, and related verbs—perfect fertilizer for the embedding model.
Typical flow:
1.Prompt: “Write a two-sentence answer to: How do I mix BM25 and vectors in Postgres?” 2.Embedthat mini-answer 3.Retrievetop-K vector neighbors 4. Optionally append the original outline or section heading as a second vector query (multi-vector search)
Now combine that vector recall with keyword precision…
4. Building a hybrid retriever in ~60 lines of Python
Below is a trimmed version of the working example. Full script sits at the end.
import psycopg2, numpy as np, openai, os
openai.api_key = os.getenv("OPENAI_API_KEY")
DB_DSN = os.getenv("DATABASE_URL")
EMBED_MODEL = "text-embedding-ada-002"
ALPHA = 0.7 # weight on vector vs BM25
def embed(text): # ① get embedding
emb = openai.Embedding.create(model=EMBED_MODEL,
input=text)["data"][0]["embedding"]
return np.array(emb, dtype=np.float32)
def vector_hits(conn, emb, k=10): # ② top-k vector
cur = conn.cursor()
cur.execute("""
SELECT id, content,
1 - (embedding <=> %s) AS vec_sim -- cosine → similarity
FROM docs ORDER BY vec_sim DESC LIMIT %s""",
(emb.tolist(), k))
return cur.fetchall()
def bm25_hits(conn, text, k=10): # ③ top-k BM25
cur = conn.cursor()
cur.execute("""
SELECT id, content,
ts_rank_cd(body_tsv, plainto_tsquery('english', %s)) AS bm25
FROM docs
WHERE body_tsv @@ plainto_tsquery('english', %s)
ORDER BY bm25 DESC LIMIT %s""",
(text, text, k))
return cur.fetchall()
def hybrid(section_draft:str):
conn = psycopg2.connect(DB_DSN)
v_hits = vector_hits(conn, embed(section_draft))
b_hits = bm25_hits(conn, section_draft)
conn.close()
# ④ normalise each score to 0-1
def norm(scores):
a=np.array(scores); return (a-a.min())/(a.ptp() or 1)
v_norm = norm([h[2] for h in v_hits]); b_norm = norm([h[2] for h in b_hits])
# ⑤ merge by document id
combined = {}
for (i,c,_), s in zip(v_hits, v_norm):
combined[i] = [c, s, 0.0]
for (i,c,_), s in zip(b_hits, b_norm):
combined.setdefault(i, [c, 0.0, 0.0])[2] = s
# ⑥ weighted rerank
scored = [(ALPHA*v + (1-ALPHA)*b, c) for c,(v,b) in combined.items()]
return sorted(scored, reverse=True)[:5]
demo = hybrid("Combining BM25 lexical ranking with pgvector semantic search")
for score, snippet in demo:
print(f"{score:.3f} → {snippet[:120]}…")
```**What just happened?**1.**HyDE draft**: you embed a short hypothetical answer.
2.**Vector retrieval**: `embedding <=> query` uses pgvector’s cosine distance.
3.**BM25 retrieval**: `ts_rank_cd()` scores keyword overlap.
4.**Normalization**: each list rescales to `[0,1]` so apples ≈ oranges.
5.**Merge & rerank**: weight the scores (`α` for semantic, `1-α` for lexical) and sort.
Adjust `α` on a validation set (or A/B test) until your engineers nod in approval.
---
## 5. Turbo-charging relevance: five pragmatic add-ons
| Technique | Why it helps | One-liner hint |
| --- | --- | --- |
|**Query expansion**| Inject synonyms, abbreviations, or ontology terms so BM25 matches more variants. | `ALTER TEXT SEARCH DICTIONARY…` or `nltk WordNet` in Python |
|**Maximal Marginal Relevance (MMR)**| Promotes diversity—avoids ten nearly identical hits. | Rerank with `λ * similarity – (1-λ) * redundancy` |
|**Metadata boosts**| Favor “chapter:intro” or recent docs via a simple WHERE clause. | `AND doc_type = 'api'` or multiply by `(1 + log(days_recent))` |
|**Cross-encoder rerank**| After top-k, ask a tiny transformer to score `{query, doc}` pairs. | Sentence-Transformers `ms-marco-MiniLM-L-6-v2` in 20 ms |
|**Adaptive chunking**| Code snippets want smaller chunks than prose. | At ingest time: `if is_code: chunk=20 lines else chunk=200 words` |
Mix-and-match; each layer is orthogonal and incremental.
---
## 6. Why Postgres as the single store?
-**Operational simplicity**: one connection pool, one backup story.
-**Transactional ingest**: embed and index in the same `INSERT` statement.
-**Extensions galore**: `pg_trgm` for fuzzy match, `unaccent` for diacritics, `hnsw` for faster vector ANN—all sitting beside your tables.
-**Cost**: if you’re already paying for a managed Postgres (RDS, Cloud SQL, Timescale), pgvector is literally `CREATE EXTENSION pgvector;` away.
Elasticsearch is fantastic for planet-scale log analytics, but many engineering orgs don’t need a second cluster just to serve 20 ms autocomplete suggestions.
If you got this far, congratulations. Smoke if you got ‘em, but don’t smoke. You know take a break. Get some coffee. Chill by the water cooler. Breathe. Ok… Let’s dive further.
### Hands-On Part 2: Text Embedding-Rerank (a.k.a. “Let the HyDE judge”)
The first snippet blended**vector scores**and**BM25 ranks**with a weighted sum.
Sometimes you’d rather let the *embedding of the [HyDE](https://www.linkedin.com/pulse/using-chatgpt-embeddings-hyde-improve-search-results-rick-hightower/?trackingId=%2Fhdzp4ZNT3aCh9Bg5mQoEA%3D%3D) draft itself* decide which passages are closest—regardless of whether they arrived via vector search or keyword search.
Or perhaps you have multiple ways to search. Let’s say you are trying to match a resume against job postings. You can match against the job posting itself. You can match it against hypothetical resumes that you already generated from job postings. You can extract the skills section of the resume to the required skills of the job posting, but at some point you need a final judge or at least a semi-final judge. This is where rerank comes into. Pull the data back using many techniques but then prioritize the snippet for content based on your rerank.
Below is a *drop-in* extension that:
1.**Runs BM25 twice**-**Mode A – Question only**(what the user actually typed)
-**Mode B – HyDE draft**(the LLM’s hypothetical answer)
2.**Pulls the three candidate pools**- Vector top-*k* (semantic)
- BM25-Q top-*k* (lexical)
- BM25-HyDE top-*k* (lexical, paraphrased)
3.**Embeds every candidate passage**(once—memoize in production)
4.**Reranks all candidates**purely by *cosine similarity to the HyDE embedding*
– drop-in flag lets you *blend* similarity with the earlier hybrid score if you prefer.
> Cost note: Embedding every passage is cheap at small k (e.g., 30 items × Ada ≈ $0.0006). For large corpora, cache passage embeddings at ingest time. You can also get embedding models libraries that are free and that are quite good, but let’s save that for another because I don’t get paid by the word or at all.
>
```python
# ─── Imports & config (same as before) ─────────────────────────────────────────
import os, psycopg2, openai, numpy as np
openai.api_key = os.getenv("OPENAI_API_KEY")
DB_DSN = os.getenv("DATABASE_URL")
EMBED_MODEL = "text-embedding-ada-002"
TOP_K_VEC = 10 # vector pool
TOP_K_BM25 = 10 # each BM25 pool
# ─── Utility: embed & cosine sim ──────────────────────────────────────────────
def embed(text: str) -> np.ndarray:
em = openai.Embedding.create(model=EMBED_MODEL, input=text)["data"][0]["embedding"]
return np.asarray(em, dtype=np.float32)
def cos_sim(a: np.ndarray, b: np.ndarray) -> float:
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b) + 1e-9))
# ─── Retrieval helpers (vector + generic BM25) ────────────────────────────────
def vec_hits(conn, q_emb, k=TOP_K_VEC):
cur = conn.cursor()
cur.execute("""
SELECT id, content, 1 - (embedding <=> %s) AS vec_sim
FROM docs ORDER BY vec_sim DESC LIMIT %s
""", (q_emb.tolist(), k))
return cur.fetchall() # (id, passage, vec_sim)
def bm25_hits(conn, query_text:str, k=TOP_K_BM25):
cur = conn.cursor()
cur.execute("""
SELECT id, content,
ts_rank_cd(body_tsv, plainto_tsquery('english', %s)) AS bm25
FROM docs
WHERE body_tsv @@ plainto_tsquery('english', %s)
ORDER BY bm25 DESC LIMIT %s
""", (query_text, query_text, k))
return cur.fetchall() # (id, passage, bm25_rank)
# ─── Master routine: embed-based rerank across all pools ──────────────────────
def retrieve_and_embed_rerank(user_question:str):
# Step-1 Generate HyDE draft (pretend; swap in your own LLM call)
hyde_draft = f"A concise answer: {user_question}" # <-- placeholder
hyde_emb = embed(hyde_draft)
# Step-2 Pull pools
conn = psycopg2.connect(DB_DSN)
vec_pool = vec_hits(conn, hyde_emb)
bm25_q = bm25_hits(conn, user_question)
bm25_h = bm25_hits(conn, hyde_draft)
conn.close()
# Step-3 Merge pools into {id: passage}
merged = {}
for pool in (vec_pool, bm25_q, bm25_h):
for pid, passage, _ in pool:
merged.setdefault(pid, passage)
# Step-4 Embed every candidate passage (cache in prod)
cand_embs = {pid: embed(txt) for pid, txt in merged.items()}
# Step-5 Rerank by cosine(query_emb, passage_emb)
scored = [(cos_sim(hyde_emb, emb), txt) for txt, emb in cand_embs.values()]
scored.sort(reverse=True) # highest similarity first
return scored[:10] # top-10 passages
# ─── Demo ─────────────────────────────────────────────────────────────────────
if __name__ == "__main__":
q = "How do I combine BM25 and vector search in Postgres?"
for sim, passage in retrieve_and_embed_rerank(q):
print(f"{sim:.3f} → {passage[:120]}…")
What changed vs. example #1?
| Step | Old hybrid | New embedding-rerank |
|---|---|---|
| Candidate pools | Vector + BM25(HyDE) | Vector + BM25(Q) + BM25(HyDE) |
| Normalisation | Min–max + α-blend | Optional—we ignore it here |
| Final rank signal | α·vec + (1-α)·bm25 | Pure cosine(HyDE, passage) |
| Cost per query | 1 embedding call | 1 + #candidates embedding calls |
You can easilytoggle modes:
-Replacethe old normalisation by discarding those scores and ranking solely on cosine similarity (as shown).
-Composethe signals by multiplying or summing—e.g. final = 0.6·hybrid_score + 0.4·cosine_sim.
If you embeddings in the DB are different, you can easily pull back embeddings from the Open AI API in one batch or several batches. It is still inexpensive compared to our next rerank in the final lap of this journey. I actually have a full rerank HyDE example that does just this—it does the whole cosine similarity in memory.
Why dual-BM25?
1.User-question BM25catches exact tokens the LLM may drop in the HyDE draft. 2.HyDE-BM25surfaces passages that share paraphrased language or synonyms.
Tip: Keep TOP_K_BM25 smaller for the question query if it tends to be short (fewer distinct terms), and larger for the HyDE query.
Production pointers
| Concern | Mitigation |
|---|---|
| Embedding cost | Pre-embed your entire corpus at ingest. Only the HyDE draft is “live.” |
| Latency | Batch passage embeddings in a single OpenAI call (Embedding.create(input=[...])). |
| Dedupes | Store passage hashes; merge pools on that hash to avoid near-identical text. |
| Evaluation | Measure recall@k and MRR with a labeled set; tune pool sizes accordingly. |
Now your retriever can yell, “Hold my beer—I found the paragraph!” before the generator writes a single word.
🏆 Stage 3: LLM-Driven “Super Rerank”—when 1-of-N really matters
Now lets cover reranking using an LLM. In this version, we start with 1,000 resumes ranked by text embedding after collecting with vector search, full text search, multiple ways. We select the top 100 and use a custom LLM prompt to score them against a specific rubric. The rubric evaluates how well the years of job experience match the posting (1-10), whether the candidate lives in the area (1-10), and how closely their skills align (1-10), etc. After weighting these scores, we sort the top candidates based on the LLM rubric and return them to the user—while continuing to rank the remaining candidates in the background. This LLM-based reranking approach works equally well for RAG content. The process is quick: perform the initial retrieval, sort and rerank rapidly, then take the top results and apply the LLM-based rubric for refined, precise results.
So far we’ve:
1.Gatheredpassages (vector + dual-BM25) 2.Narrowedthem by cosine similarity to the HyDE draft
…but there are still dozens—or thousands—of “pretty good” hits.
That’s fine for RAG snippets, but**hiring managers, legal reviewers, and analysts want the single best match.**Enter the LLM Judgment Pass. If we want the best snippets for the most precise answer, we can refine things even further. Just got to let AI do it.
Analogy: Your search index is the front-desk clerk who finds every resume mentioning “Kubernetes.”
The LLM becomes the expert recruiter who scans the pile and says, “These five candidates actually fit our rubric.”
📄 Use-Case Walk-Through: Resumes vs. Job Postings
| Phase | What happens | Size |
|---|---|---|
| Recall | Embed the job posting (or its HyDE explainer) → vector search returns1 000resumes | 1 000 |
| First filter | Quick cosine sort (or hybrid score) keeps top-N =100 | 100 |
| LLM rerank | Custom prompt scores each resume on: • Years of required experience (1-10) • Location proximity (1-10) • Skill overlap (1-10) → weighted sum → final score | 100 |
| Serve | Return top10immediately; continue reranking remaining 90 async | 10 |
Skeleton Code: “LLM Judge” in < 90 lines
import os, openai, psycopg2, json
from typing import List, Tuple
openai.api_key = os.getenv("OPENAI_API_KEY")
DB_DSN = os.getenv("DATABASE_URL")
EMBED = "text-embedding-ada-002"
MODEL = "gpt-4o-mini-2025-01-31" # or o3-mini etc.
# ── STEP 1: recall & first-pass rank (reuse previous helpers) ─────────────
def top_candidates(job_posting:str, K1=1000, K2=100) -> List[Tuple[int,str]]:
vec = embed(job_posting) # HyDE or posting itself
conn = psycopg2.connect(DB_DSN)
cur = conn.cursor()
cur.execute("""
SELECT id, resume_text,
1 - (embedding <=> %s) AS score
FROM resumes ORDER BY score DESC LIMIT %s
""", (vec.tolist(), K1))
hits = cur.fetchall()[:K2] # keep best 100
conn.close()
return hits # [(id, text, score)]
# ── STEP 2: LLM rubric scorer ────────────────────────────────────────────
RUBRIC = """
You are an expert technical recruiter.
Rate this RESUME against the JOB DESCRIPTION on three axes:
1. Required years of devops/cloud experience (score 1-10)
2. Location proximity to "{city}" (1-10)
3. Skill overlap with these keywords: {skills} (1-10)
Respond strictly as JSON:
{{
"years": <int>,
"location": <int>,
"skills": <int>,
"explanation": "<optional 1-sentence reason>"
}}
"""
def judge(job_desc:str, resume:str, city:str, skills:str)->dict:
prompt = RUBRIC.format(city=city, skills=", ".join(skills))
messages = [
{"role":"system", "content":prompt},
{"role":"user", "content":f"JOB DESCRIPTION:\n{job_desc}"},
{"role":"assistant","content":"Understood."},
{"role":"user", "content":f"RESUME:\n{resume[:4000]}"} # trim token risk
]
resp = openai.ChatCompletion.create(model=MODEL,
messages=messages,
temperature=0)
return json.loads(resp["choices"][0]["message"]["content"])
# ── STEP 3: Combine scores & serve ────────────────────────────────────────
WEIGHTS = {"years":0.4, "location":0.2, "skills":0.4}
def rerank_llm(job_posting:str, city="Austin, TX", skills=("kafka","aws","k8s")):
cand = top_candidates(job_posting)
judged = []
for pid, text, _ in cand:
j = judge(job_posting, text, city, skills)
final = sum(j[k]*w for k,w in WEIGHTS.items())
judged.append((final, pid, text, j))
judged.sort(reverse=True) # highest composite first
return judged[:10] # top 10 to caller, rest async
# ── Demo ─────────────────────────────────────────────────────────────────
if __name__ == "__main__":
JD = "Senior DevOps Engineer – 5+ yrs AWS, Kafka, Kubernetes. Must be in Austin."
for score, pid, _, detail in rerank_llm(JD):
print(f"{pid} → {score:.1f} pts | rubric: {detail}")
What to notice
-Streaming friendly– call openai.ChatCompletion.create(stream=True) inside the loop to render scores as they arrive.
-Cost control– you’ll embed only once, then pay100 chat completions(~$0.06 with o3-mini).
-Async ranking– push remaining 900 resumes onto a queue; background workers generate rubric scores and refresh the dashboard in real time.
-Auditability– JSON rubric scores + short explanation give hiring teams a transparent “why.”
Applying the Same Trick to RAG Snippets
- Replace “resumes” with “doc chunks.”
- Swap rubric dimensions—e.g., freshness, authority, coverage of API call.
- Feed thetop-kLLM-ranked snippets into your answer‐generation prompt for high-precision grounding.
TL;DR: Search broadly ➜ filter quickly ➜ let an LLM make the final call with domain-specific rules.
That last mile—from “good enough” to bullseye—is where users feel the magic.
Remember to establish baselines and testing methods as you improve your system. “Improvements” can fix certain use cases while breaking others.
Also, not every query needs these advanced techniques. You can use AI to determine if a question is simple, verify if the system answered it adequately, and only trigger the more sophisticated search or reranking approach described above when responses fall below a certain quality threshold (the user never knows per se).
7. Wrapping up
Pure vector search is magical, but it’s not omniscient.
Exact tokens, rare identifiers, and repetitive boilerplate still benefit from old-school lexical ranking. By layeringHyDE-generated queries,BM25/FTS, and asimple weighted rerankinside Postgres, you can slash hallucinations and missed citations with minimal infra overhead. Add some rerank using a higher resolution text embedding or better yet add an AI prompt rubric and your finding that needed in the haystack and improving the results of your RAG system.
Next time your LLM answers invents a function that never existed, look first at the retriever. Chances are your perfect passage lives in the database—you just need a hybrid searchlight to find it.
Further reading & tinkering
- pgvector project — install and index cheatsheet
- PostgreSQL FTS docs — custom dictionaries & ranking functions
- Lucene BM25 similarity — deep dive into the math
- Sentence-Transformers cross-encoders — drop-in rerankers that fit in 200 MB of RAM
Happy retrieving!
About the Author
Rick Hightower is a Senior Software Architect and AI Systems Engineer with extensive experience in building enterprise-scale applications and AI/ML systems. He specializes in retrieval-augmented generation (RAG), vector databases, and large language model integration. As a technical leader and educator, Rick has helped numerous organizations implement effective AI solutions while maintaining high standards of accuracy and reliability.
Rick frequently writes about AI engineering best practices, system architecture, and practical approaches to reducing LLM hallucinations. He also speaks at conferences. His work focuses on bridging the gap between theoretical AI concepts and real-world implementation challenges.
Connect with Rick on LinkedIn or follow his technical blog for more insights on AI engineering and system architecture.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting