May 31, 2025
Dive into the AI architecture wars! From multimodal marvels to efficiency champions, discover how tech giants are building radically different AI brains that will shape our future. Which approach will win? Read on to find out!
Tech giants are competing in AI architecture, with distinct approaches: AI21 Labs focuses on efficiency with large vocabularies, OpenAI emphasizes scale with massive resources, Google integrates multimodality, Anthropic prioritizes safety, and Amazon targets cost-effective cloud solutions. Each strategy shapes the future of AI deployment and capabilities.
.jpg)
The Architecture Wars: How Tech Giants Are Building Radically Different AI Brains
Imagine if Ford, Tesla, Toyota, and Ferrari all claimed to make “cars,” but under the hood, one used a jet engine, another ran on hydrogen fuel cells, the third pioneered a hybrid electric-combustion system, and the last one optimized a traditional engine to absurd efficiency. That is essentially what is happening in the AI industry today.
While ChatGPT, Claude, Gemini, and other AI assistants might seem similar on the surface—they all chat, answer questions, and write code—their underlying architectures are as different as a smartphone is from a supercomputer. These architectural choices are not just technical curiosities; they determine everything from how much these models cost to run, how well they understand different languages, whether they can process videos, and even how “safe” they are in their responses.
Welcome to the architecture wars of artificial intelligence, where the world’s most powerful tech companies are betting billions on fundamentally different approaches to building AI brains. The winners will shape how AI integrates into our daily lives, from the apps on our phones to the enterprise systems running global businesses.
In this article, we will just focus on hosted services where companies create their own LLM vs open source so commercial and hosted. And, take it all with a grain of salt. I am a fellow traveler and would love feedback even if that is some correction.
The Transformer Revolution: A Shared Foundation
Before diving into what makes each AI model unique, let us establish the common ground. Nearly all modern large language models (LLMs) share a foundation in the transformer architecture, a breakthrough that revolutionized AI in 2017. Think of transformers as a universal translator that can understand relationships between words, pixels, or even musical notes, regardless of their position in a sequence.
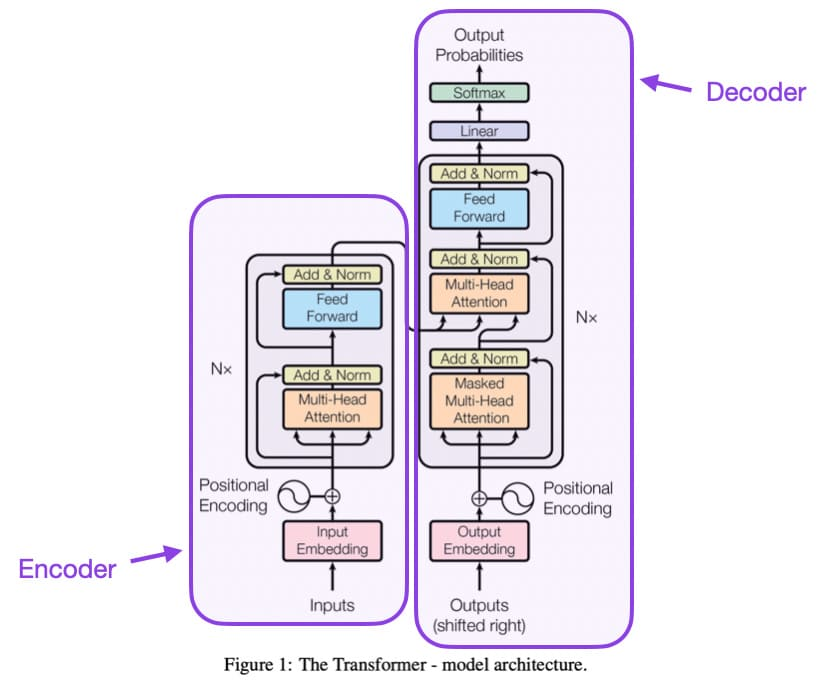
The magic lies in something called theattention mechanism. Unlike older AI models that processed information sequentially (like reading a book word by word), transformers can look at an entire paragraph at once and understand how each word relates to every other word. It’s the difference between reading with tunnel vision versus taking in the whole page at a glance.
This shared foundation makes the architectural divergences even more fascinating. It’s as if everyone agreed on the basic laws of physics but then built radically different machines to harness them.
The Efficiency Crusader: AI21 Labs’ Vocabulary Innovation
While most tech giants chase raw power, AI21 Labs took a contrarian approach: what if we could make AI more efficient rather than just bigger? Their Jurassic models employ a clever trick that sounds simple but has profound implications—they use a massive 250,000-token vocabulary, about five times larger than competitors.
I was thinking about this. I remember reading somewhere that there are about 50,000 words in the English vernacular that get used fairly regularly. Webster’s dictionary has around 470,000 entries, but some words are sort of in there twice or more (think “drive” vs. “drove”). The Oxford English Dictionary has 600,000 words in it, but the second edition has 171,476 with about 50K listed as obsolete. Then if you include jargon and slang, and whatever GenZ is saying, there could be over a million words or more—no cap. Still, 250K is a lot, and I am sure there is a long tail of common use vs. infrequently used words.
To understand why this matters, imagine trying to write “artificial intelligence” but having to spell it out letter by letter versus writing it as a single symbol. AI21’s approach is like having more symbols at your disposal, reducing the computational steps needed to process text. This seemingly small optimization cascades into significant benefits: faster processing, lower costs, and reduced energy consumption.
Their latest innovation, the Jamba 1.6 family, pushes efficiency even further by combining traditional transformers with something calledMamba architecture—a hybrid approach that processes long documents up to 2.5x faster than conventional models. This is like adding a turbocharger to an already efficient engine.
But here’s where it gets really interesting: AI21 didn’t stop at building efficient models. In March 2025, they introduced Maestro, described as the “world’s first AI Planning and Orchestration System.” Rather than just making their own models better, Maestro can enhance other companies’ AI models (including GPT-4 and Claude) by up to 50% on complex tasks. It’s a bold strategy—becoming the performance optimizer for the entire AI ecosystem.
I don’t have any direct experience with AI21. It sounds interesting.
The Scale Maximalist: OpenAI and Grok Mixture of Experts and Massive Training
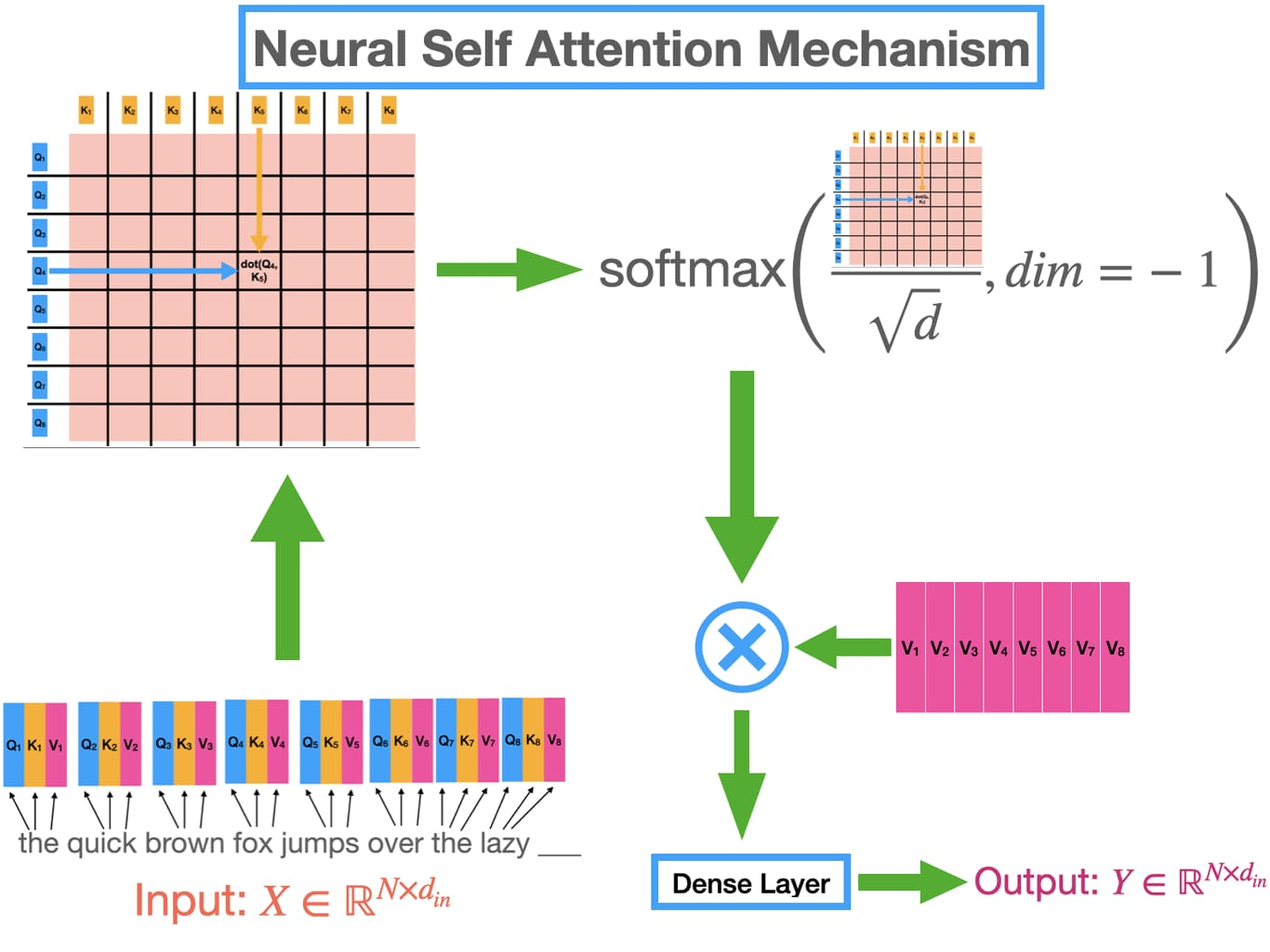
OpenAI represents the opposite philosophy: throw unprecedented computational resources at the problem and see what emerges. Their GPT-4 architecture employs a**Mixture of Experts (MoE)**approach with approximately 1.76 trillion parameters distributed across 16 expert networks.
Picture a hospital with 16 world-class specialists. When a patient arrives, only the relevant specialists are consulted—the cardiologist for heart issues, the neurologist for brain concerns. Similarly, GPT-4’s expert networks activate selectively based on the input, allowing the model to be massive without being computationally prohibitive for every query.
The numbers are staggering: training GPT-4 required about 25,000 NVIDIA A100 GPUs running for 90-100 days at an estimated cost of $63 million. The latest o3 models push even further into chain-of-thought reasoning, where the AI essentially “thinks out loud” before responding, achieving breakthrough performance on mathematical and reasoning tasks.
And this is trend continues as do other ways to train models. Grok 3: Trained on xAI’s Colossus supercomputer, initially utilizing 100,000 NVIDIA H100 GPUs, expanding to 200,000 H100s. The H100, successor to the A100, offers significantly higher performance—roughly 3-5x more throughput for AI workloads (e.g., ~1 PFLOP/s for FP8 precision vs. ~312 TFLOPS for A100 FP16). This implies Grok 3’s training compute was potentially 40x greater than GPT-4’s, assuming similar training durations, due to the H100’s superior performance and higher GPU count.
Crazy right. That is melt the icebergs, build a rocket ship and escape Earth level compute power.
Note: Grok 3: Exact duration isn’t publicly disclosed, but xAI set up the Colossus cluster in just 19 days and claims Grok 3 was trained in a “very short period” compared to industry norms. Specific details on o3’s training hardware are sparse, but OpenAI has reported a two-order-of-magnitude cost reduction for reasoning models, suggesting optimizations in compute efficiency. It’s likely o3 used a mix of A100s and possibly H100s, but on a smaller scale than Grok 3, given OpenAI’s focus on efficiency. FWIW Grok also uses MOE.
This approach has proven remarkably successful, with OpenAI’s models consistently ranking at or near the top of performance benchmarks. However, it comes with trade-offs: these models are expensive to run, require significant infrastructure, and can be overkill for simple tasks.
The Multimodal Pioneer: Google’s Native Integration
Google’s Gemini represents perhaps the most ambitious architectural philosophy: native multimodality. While competitors typically start with text and bolt on image or video capabilities later, Google trained Gemini from day one to understand text, images, audio, and video as interconnected forms of information.
This is like raising a child to be multilingual from birth versus teaching them additional languages as an adult—the native speaker will always have more intuitive, fluid command of all languages. Gemini’s architecture enables it to seamlessly reason across modalities, understanding not just what’s in an image but how it relates to accompanying text or audio.
The technical achievement is remarkable. Gemini Pro sports a 2-million-token context window—enough to process entire novels, feature-length movies, or massive codebases in a single query. Imagine being able to ask questions about a entire book series or analyze hours of video footage in one go.
Google’s approach also includes Gemini Nano, designed specifically for on-device deployment on smartphones. Using 4-bit quantization (a technique that compresses the model while maintaining performance), Google brings powerful AI capabilities directly to mobile devices without relying on cloud processing.
The Safety-First Architect: Anthropic’s Constitutional AI
Anthropic, founded by former OpenAI researchers, took a fundamentally different approach with their Claude models. Instead of optimizing for raw performance or efficiency, they prioritized safety and alignment through a novel training methodology calledConstitutional AI (CAI).
Traditional AI training relies heavily on human feedback—humans rate AI responses, and the model learns to maximize those ratings. But this approach has limitations: human reviewers can be inconsistent, biased, or simply overwhelmed by the volume of training data. Constitutional AI flips the script by having AI models critique and improve themselves based on a predefined set of principles—a “constitution” for AI behavior.
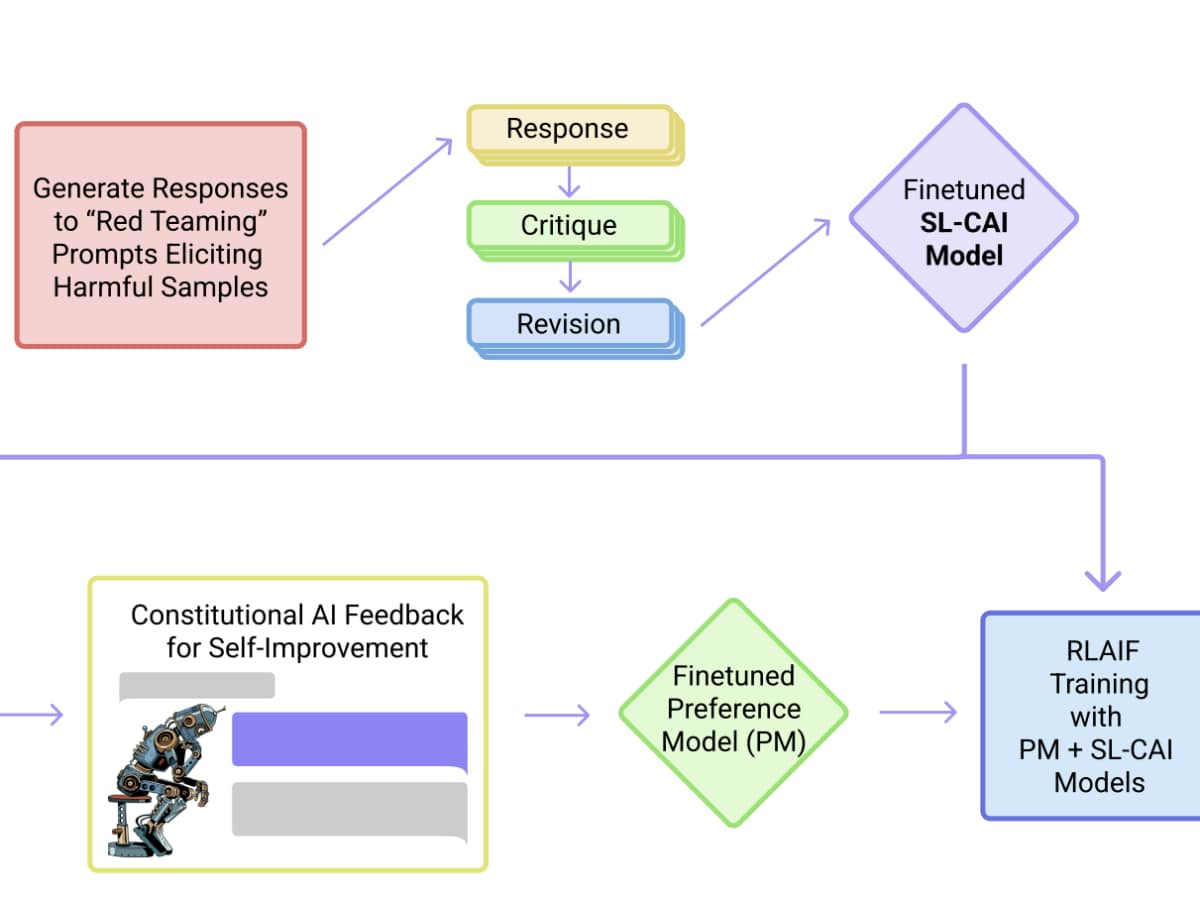
This self-improvement loop works like this: Claude generates a response, then critiques it against constitutional principles (“Is this helpful? Is it harmless? Is it honest?”), revises the response based on its self-critique, and iterates until the output meets all principles. It’s like having an AI with a built-in conscience.
The results speak for themselves. Claude 4 Sonnet achieves the highest coding benchmark scores among all evaluated models, while Claude Opus 4 can work autonomously for up to seven hours on complex tasks. Users often report that Claude feels more thoughtful and nuanced in its responses—a direct result of the Constitutional AI approach.
I frequently go back and forth using different models and often compare results. Although on model may pull forward here or there, I find that I consistently come back to using Claude the most. At times, I will use other models to do research and if I like what it says, I use Claude to refine it. I prefer Claude’s writing style and explanation. This goes for code as well. I use Grok, Gemini, ChatGPT and Perplexity daily as well. Some days all of them, some days at least three of them. Claude is my favorite and has been for a while. Even from time to time, when Claude is not at the top of the leader board for performance, I still question the benchmarks themselves because often times, I much prefer its output. Don’t get me wrong, I love Gemini and Grok and ChatGPT too. Not to mention Perplexity. I digress. Claude is my favorite for writing and coding. Grok for current events. Perplexity and Gemini for search and research (it used to be Perplexity and Grok before the last release of Gemini). I am also a big fan of Google AI labs and now Perplexity labs.
The Cloud-Native Strategist: Amazon’s Integrated Ecosystem
Amazon’s entry into the AI model race reflects its DNA as a cloud infrastructure giant. The Nova and Titan families aren’t designed to win benchmark competitions but to integrate seamlessly with AWS services while offering compelling price-performance ratios.
Nova Pro, with 500 billion parameters, achieves respectable benchmark scores while claiming 75% cost savings compared to similar models on the AWS Bedrock platform. It’s the Costco approach to AI—solid quality at bulk prices. The Nova family also includes specialized models for creative tasks: Nova Canvas for image generation and Nova Reel for video creation, all tightly integrated with Amazon’s cloud ecosystem.
The Titan models focus on enterprise fundamentals. Titan Text Embeddings V2 offers a clever feature: configurable vector dimensions. Users can choose between 256, 512, or 1024 dimensions, trading off between accuracy and storage costs. For many applications, the 256-dimensional vectors maintain 97% accuracy while dramatically reducing storage requirements—a perfect example of Amazon’s practical, cost-conscious approach.
I don’t have a lot of direct experience with Amazon’s models and what little experience I do have was underwhelming this is not to say that they are not amazing. Show me one of these AI models back in let’s say 2015, and I would they were some sort of black magic. But the bar is so high now and expectations are so high. But if you had an application that could get by using one of these models, they are cost effective.
The Enterprise Specialist: Cohere’s Business Focus
While consumer-facing AI grabs headlines, Cohere quietly built a formidable business serving enterprise customers. Their Command-A model achieves an impressive feat: 104 billion parameters running on just 2 GPUs, compared to the 32 GPUs required by comparable models.
This efficiency translates directly to the bottom line. Cohere claims 50% reduced deployment costs for private enterprise setups—crucial for industries like finance and healthcare that can’t send sensitive data to cloud services. Command-A also excels at multilingual support, covering 23 languages including Arabic dialects, Ukrainian, and Persian, reaching 80% of the global population.
But Cohere’s real innovation might be in recognizing what enterprises actually need: not benchmark-topping performance, but reliable, efficient, deployable AI that works within existing security and compliance frameworks. It’s the difference between a Formula 1 race car and a Toyota Camry—both are vehicles, but only one makes sense for your daily commute.
A while back, I took some GenAI courses that were using Cohere and this was after using Claude and OpenAI for a while. I was a bit underwhelmed. This was a while ago before Grok was even a thing. When using BedRock, I do use their text embedding models because it is the best text embedding as a service offering from Amazon.
The Benchmark Reality: Convergence and Specialization
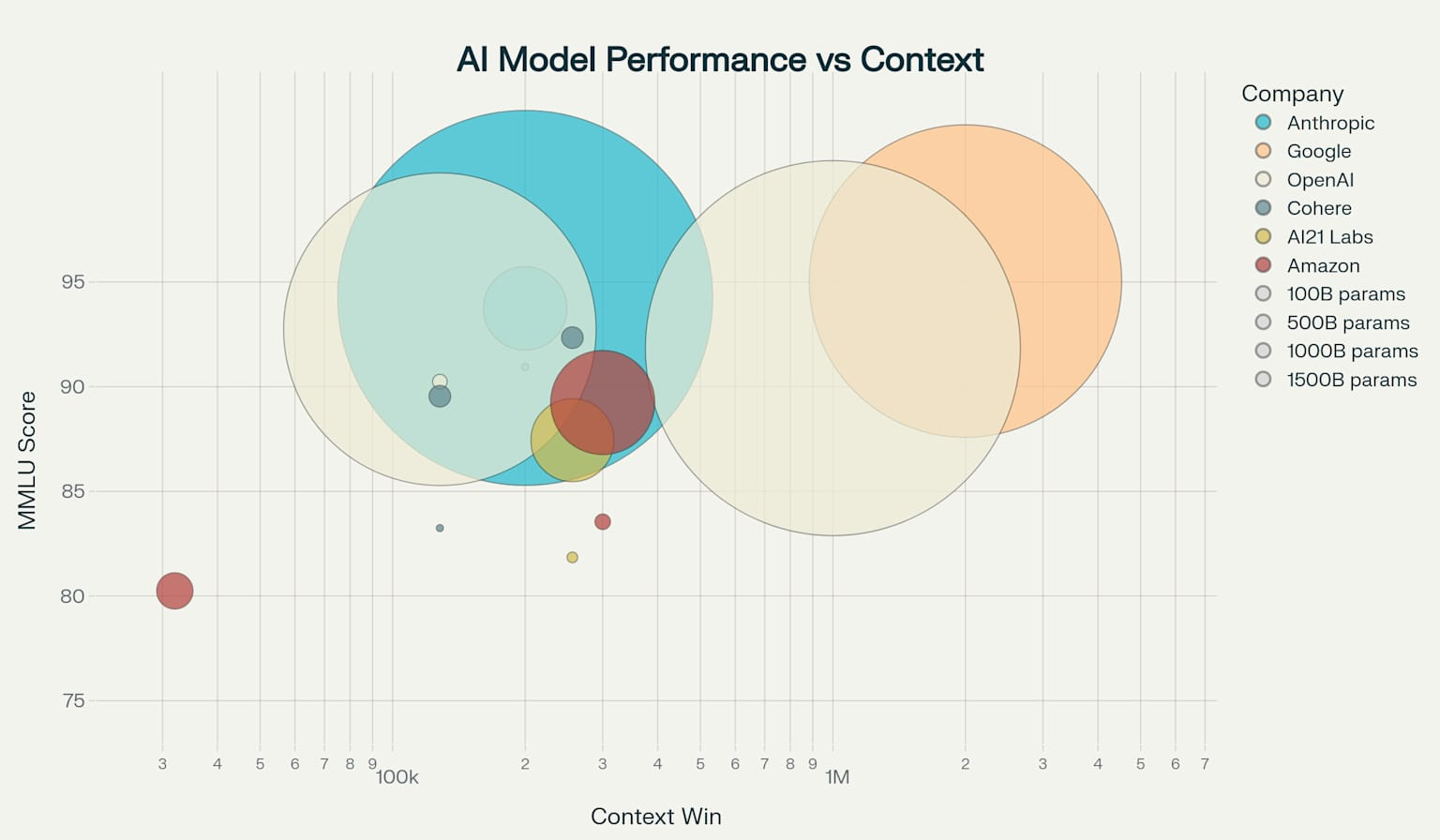
As we survey this architectural landscape, a striking pattern emerges: while benchmark scores are converging at the top, specialized capabilities are diverging dramatically. The difference between the best and tenth-best model on general benchmarks has shrunk to just 5.4%, but the gap in specialized tasks—video understanding, multilingual support, coding, mathematical reasoning—continues to widen. And again, I don’t always trust the winner. I think models can be tuned to win a benchmarks that are not actually as good when it comes to using them. And when the margin gets that tight, the benchmark differences are probably pretty subjective.
This convergence-divergence paradox suggests we’re entering a new phase of AI development. The “bigger is better” era is giving way to an “architecture matters” era. Just as smartphones plateaued in raw specs but diverged in specialized features (camera quality, battery life, ecosystem integration), AI models are finding their niches.
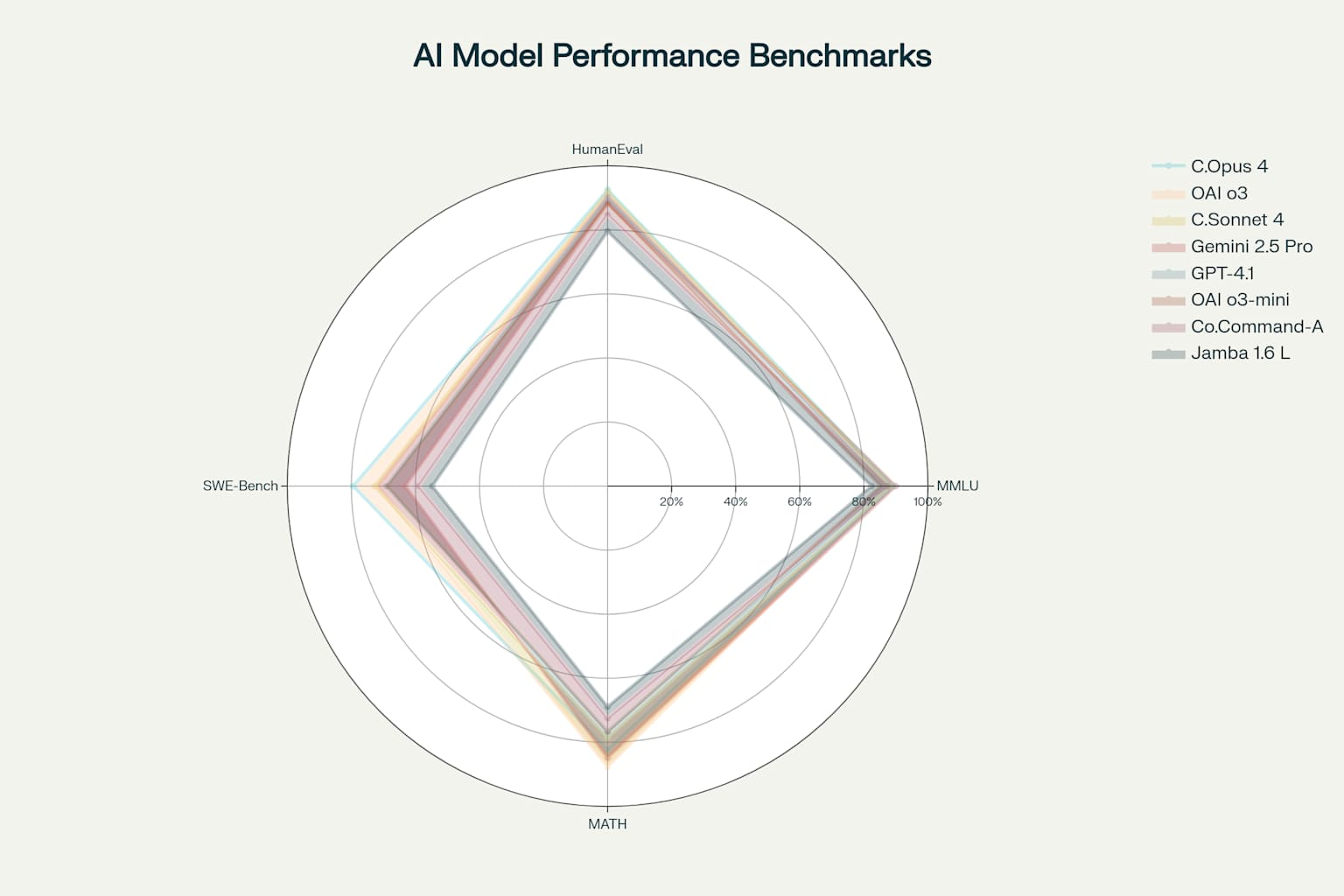
Comprehensive benchmark evaluation reveals distinct performance patterns across the four model families, with each excelling in different areas aligned with their architectural priorities.
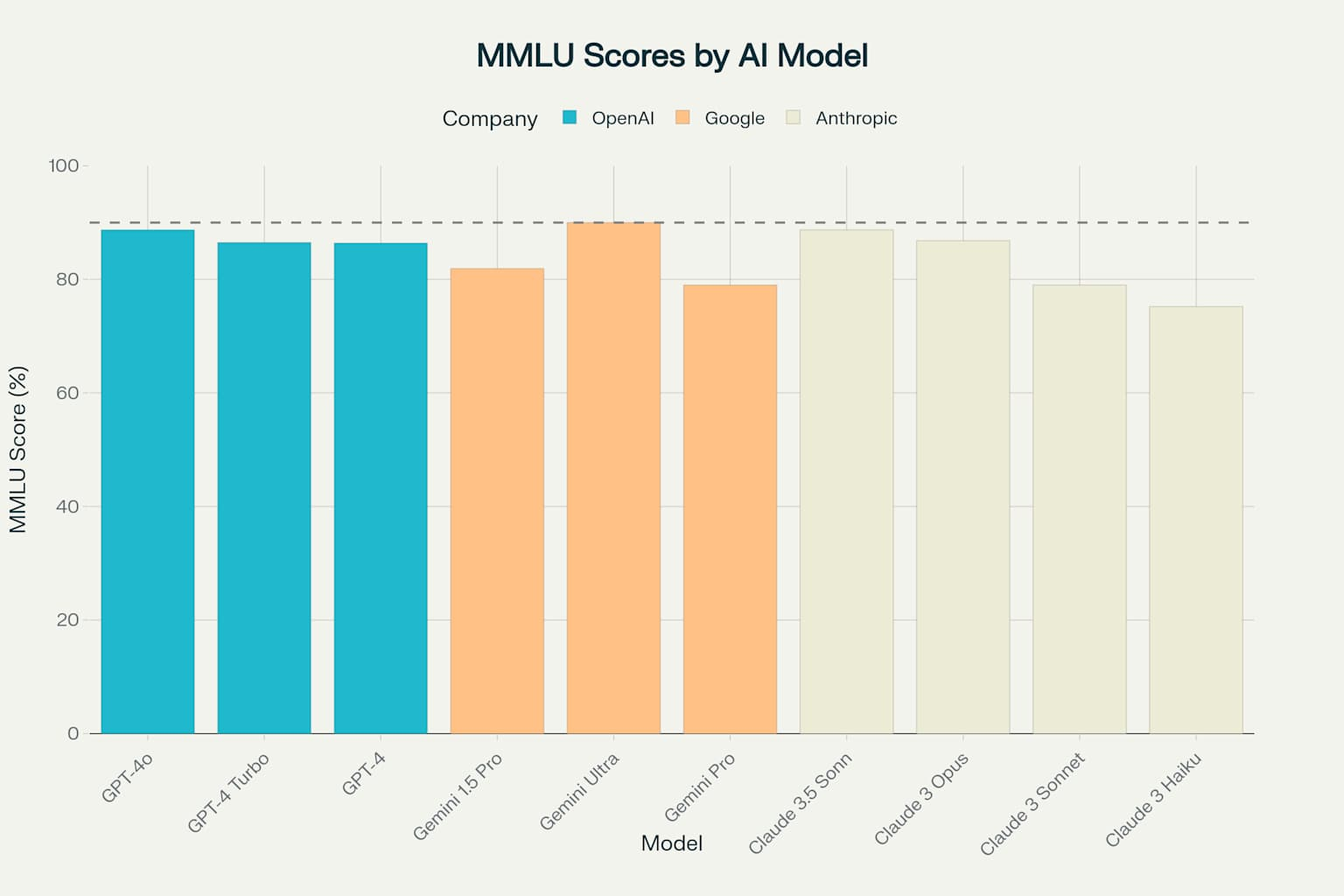
The MMLU (Massive Multitask Language Understanding) benchmark, testing knowledge across 57 academic subjects, shows Gemini Ultra achieving the first superhuman performance at 90.0%, surpassing human expert levels 2134. GPT-4o and Claude 3.5 Sonnet both achieve 88.7%, while other models range from 75.2% to 86.8% 3339. This benchmark particularly highlights the effectiveness of different training approaches, with Google’s multimodal training and OpenAI’s massive scale both proving successful.
Coding performance measured by HumanEval reveals Claude 3.5 Sonnet’s dominance at 92.0%, followed closely by OpenAI’s GPT-4o and GPT-4 Turbo at 90.2%.
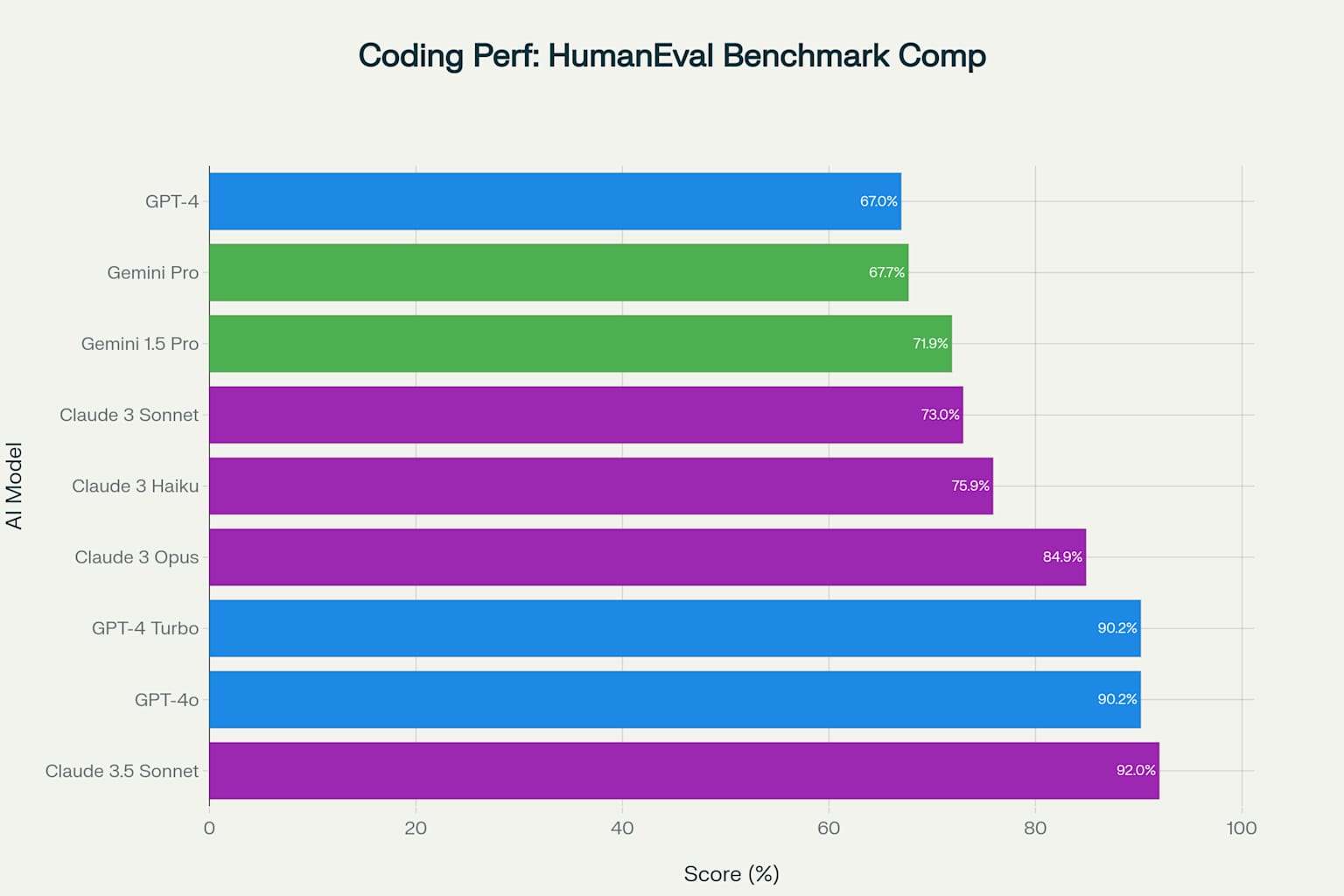
You can see how things are progressing.
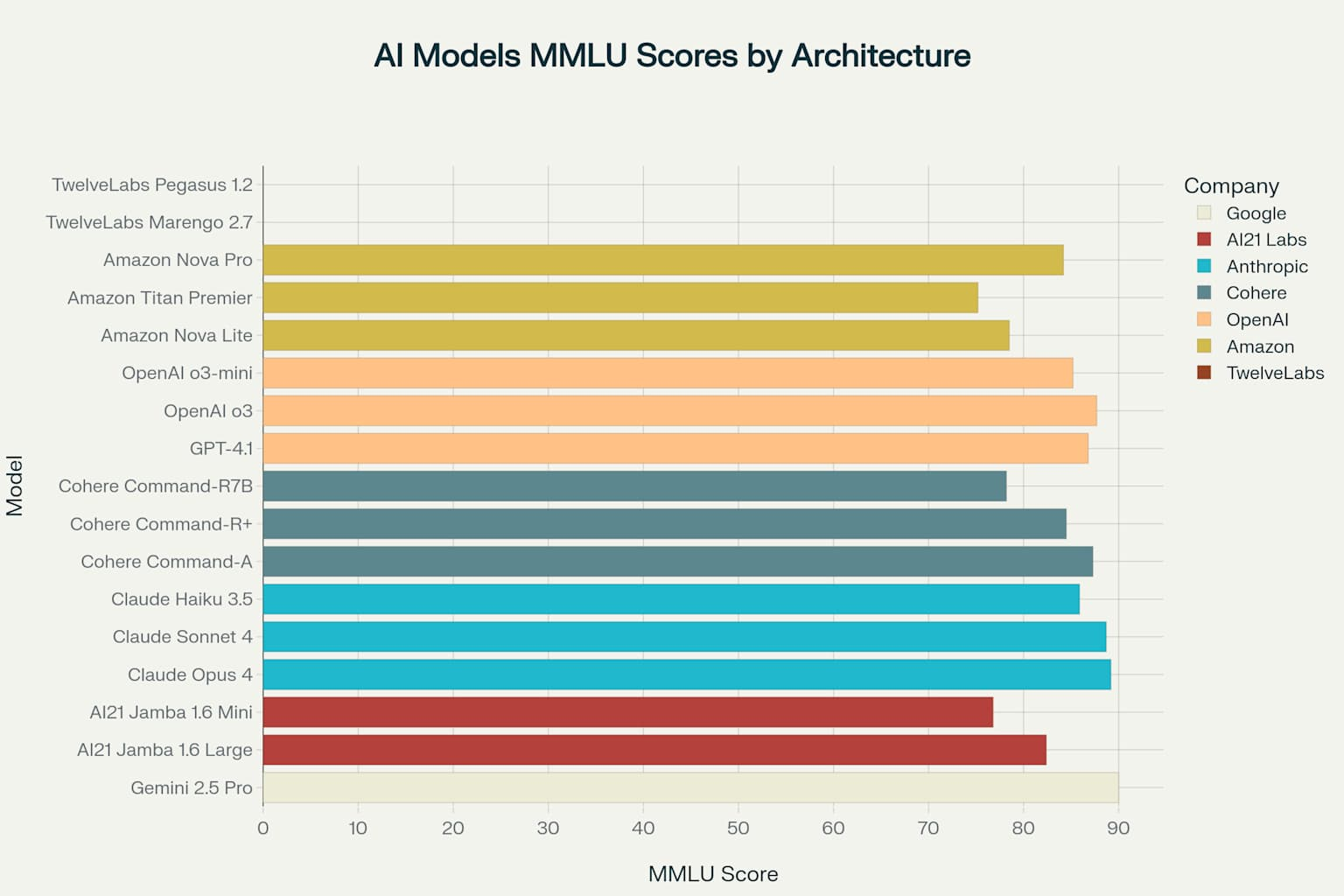
Performance analysis across the expanded model landscape reveals increasing specialization and the emergence of distinct capability clusters.
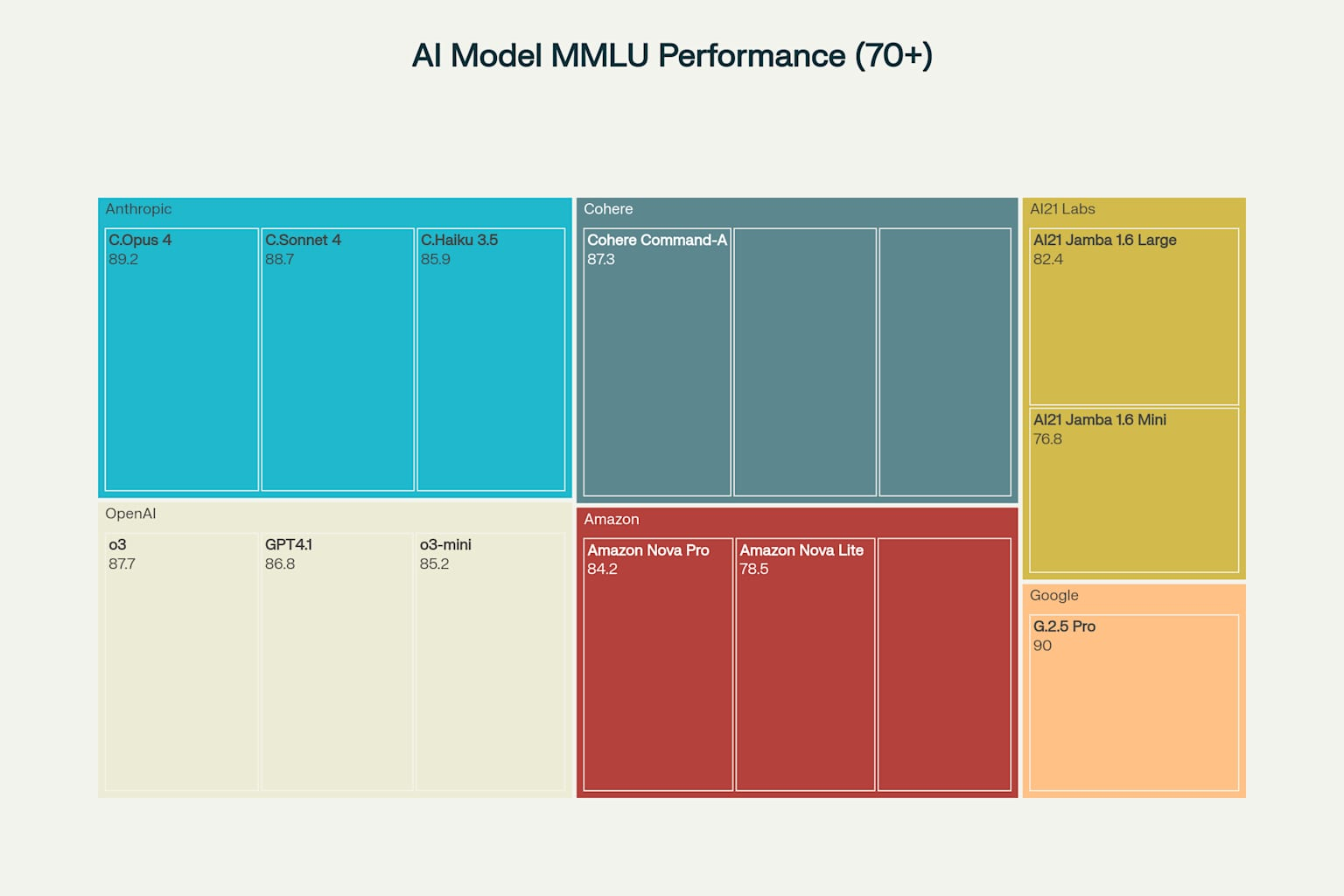
The comprehensive architectural capabilities comparison reveals each company’s strategic focus: Google leads in context window size and multimodal support, Anthropic emphasizes safety features, OpenAI balances innovation with performance, and AI21 Labs prioritizes efficiency 40. These differences reflect fundamental philosophical approaches to AI development rather than mere technical limitations.
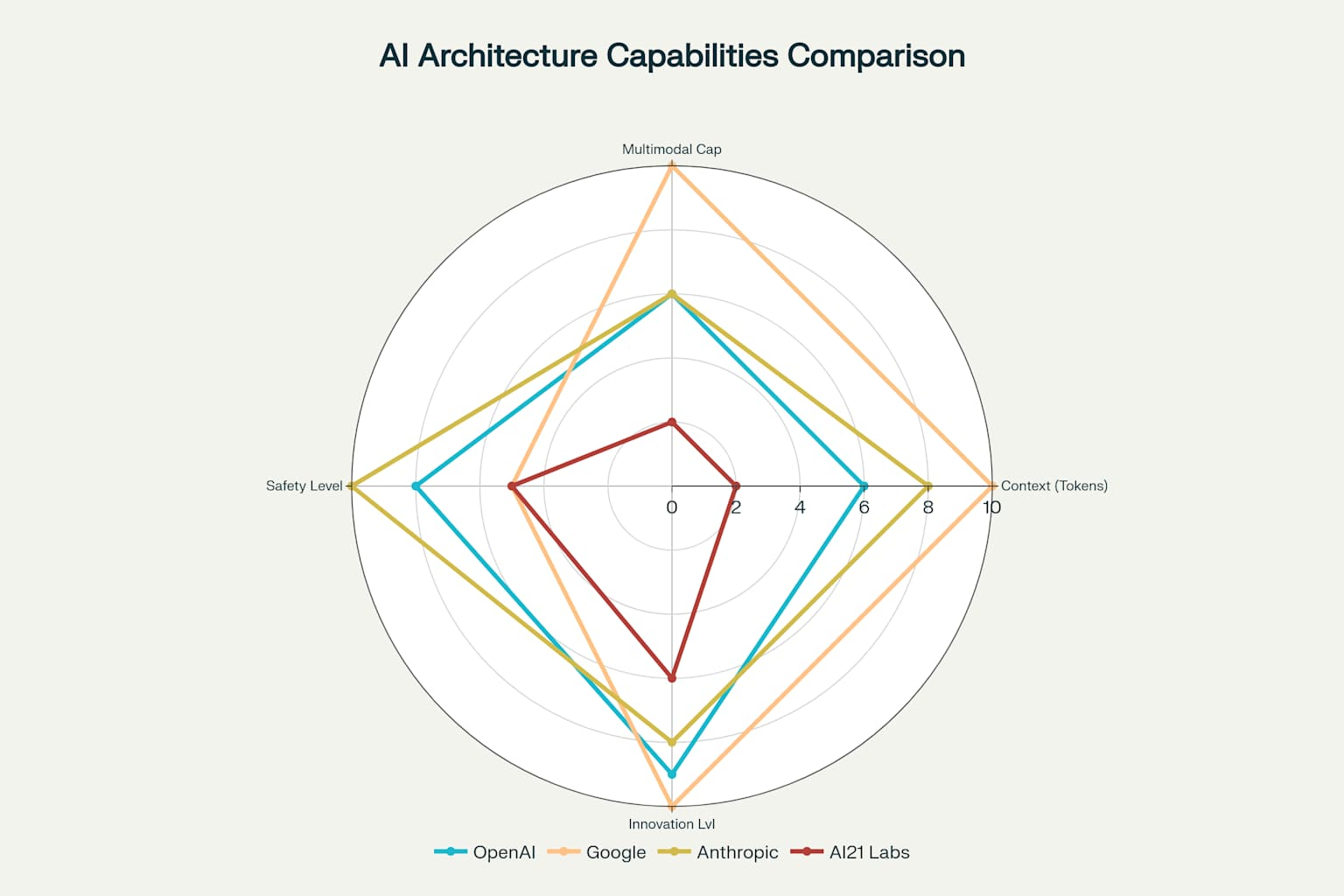
Context Window Evolution and Strategic Implications
The progression of context window sizes reveals each company’s strategic priorities and technical capabilities.
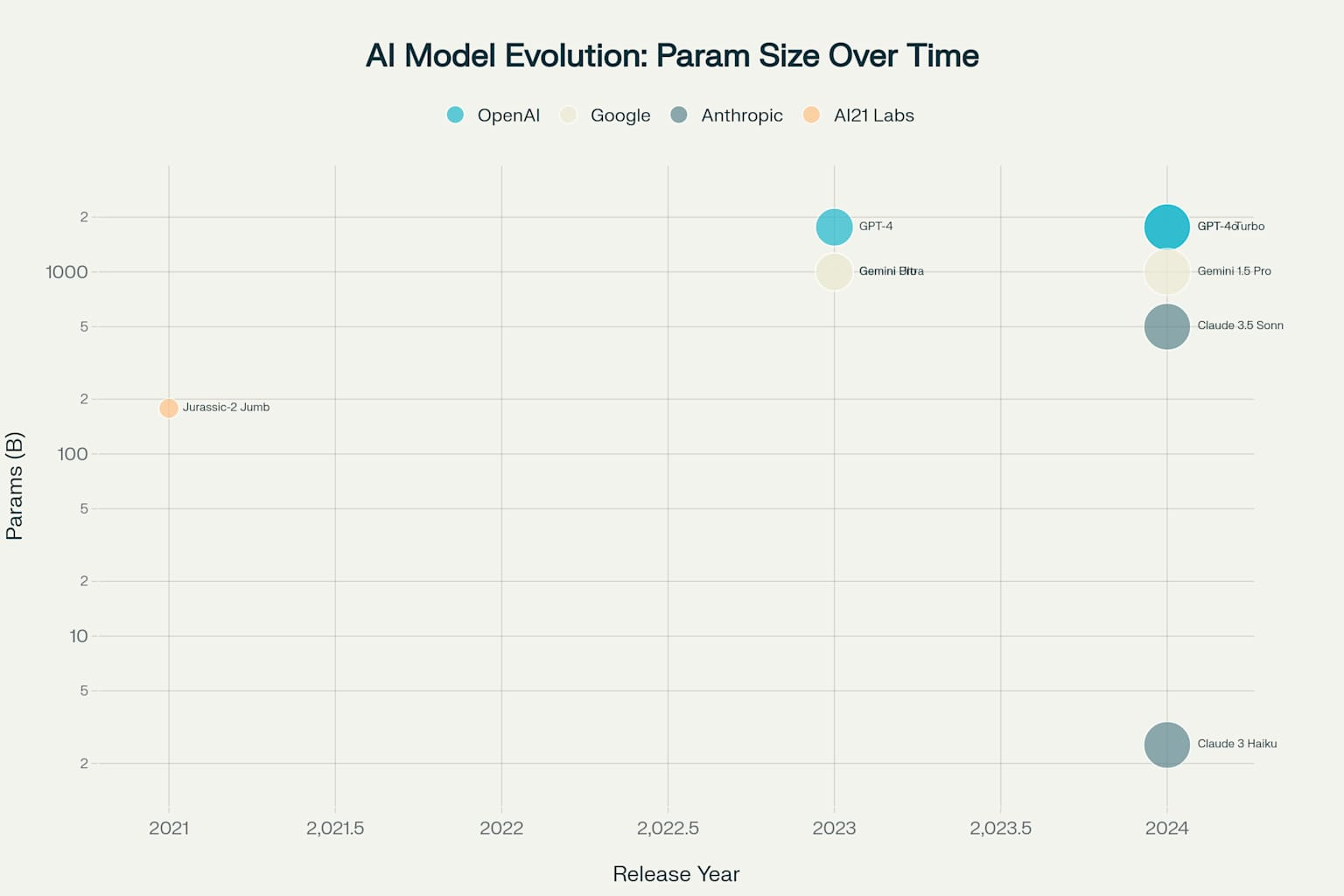
Implications for the Future
These architectural differences aren’t just academic curiosities—they’re shaping the future of AI deployment and adoption:Hybrid Architectures Are Coming: AI21’s success with Mamba-Transformer hybrids and the efficiency gains they provide suggest future models will mix and match architectural components like Lego blocks, optimizing different parts for different tasks.Deployment Drives Design: The shift from “can we build it?” to “can we deploy it?” is forcing architectural innovations. Expect more models designed with specific deployment constraints—edge devices, private clouds, real-time applications—as primary considerations.Safety by Design: Anthropic’s Constitutional AI demonstrates that safety doesn’t have to be bolted on after training. Future architectures will likely incorporate safety, alignment, and verification as core components rather than afterthoughts.The Rise of AI Orchestrators: AI21’s Maestro points to a future where AI systems don’t just respond to prompts but plan, execute, and verify complex workflows. The architecture wars may evolve into orchestration wars.Specialized > Generalized: TwelveLabs’ video-native approach may be a preview of coming attractions. As AI matures, we might see architectures specialized for robotics, scientific research, creative arts, or other domains that require fundamentally different approaches to intelligence.
The Bottom Line
We’re witnessing a Cambrian explosion in AI architectures. Unlike the early days of computing, where architectures converged on a few standard designs, AI is diverging into a rich ecosystem of specialized approaches. Each architecture represents a different bet on what matters most: efficiency, scale, safety, specialization, or integration.
For users and businesses, this diversity is a gift. Need to process millions of customer service queries cheaply? AI21’s efficient models might be your answer. Building the next breakthrough AI application? OpenAI’s powerful models could provide the edge. Analyzing vast video libraries? TwelveLabs has you covered. Requiring on-premise deployment with multilingual support? Cohere’s your partner.
The architecture wars aren’t about finding one winner—they’re about expanding the possibility space of artificial intelligence. As these different approaches cross-pollinate and inspire new innovations, we’re not just getting better AI; we’re getting different kinds of AI, each suited to different aspects of the vast challenge of augmenting human intelligence.
The next time you interact with an AI—whether it’s ChatGPT, Claude, Gemini, or any other model—remember that beneath the conversational interface lies a architectural marvel, shaped by fundamental choices about how to create, deploy, and align artificial intelligence. These choices will ultimately determine not just what AI can do, but what it should do, and how it fits into our world.
The architecture wars are far from over. In fact, they’re just beginning.
About the Author:
Rick Hightower is a seasoned GenAI enthusiast and technology leader who has been deeply immersed in Generative AI projects for nearly three years. As an early adopter and practitioner, Rick actively leverages multiple AI models including Claude, GPT-4, Gemini, and Grok for task automation and innovative solutions. His hands-on experience spans from exploring AI architectures to implementing practical applications.
With over two decades of experience in software development and architecture, Rick brings a unique perspective to the intersection of traditional software engineering and emerging AI technologies. He has worked extensively with Java, cloud technologies, and distributed systems, contributing to numerous open-source projects and technical publications throughout his career.
Rick is particularly passionate about exploring and documenting the practical applications of GenAI in software development, focusing on how these tools can enhance productivity and innovation in real-world scenarios. He regularly shares his insights through detailed articles and technical analyses, helping others navigate the rapidly evolving landscape of AI technology.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting