June 3, 2025
The AI landscape is shifting! Discover how open-source models like DeepSeek and Gemma are challenging the dominance of Big Tech’s language giants. Are we witnessing the dawn of a new era in artificial intelligence? Dive into the revolution and find out how these innovative models are reshaping the future! Open-source AI models are now matching proprietary systems through innovations in model architecture and multimodal processing. This democratization of AI technology is increasing competition and expanding the possibilities for real-world applications.

Open-Source AI Models Challenge Big Tech’s Language Systems
Picture this: A Chinese startup releases an AI model that matches OpenAI’s most advanced reasoning system, then makes it completely free for anyone to use. A month later, Google responds by shrinking its powerful models to run on a laptop. Meanwhile, Microsoft proves that with the right training recipe, a model 50 times smaller can outperform giants. Welcome to 2025, where the artificial intelligence landscape is being completely rewritten by open-source alternatives that are giving Big Tech a serious run for their money.
If you have been following the AI space, you have probably noticed something remarkable happening. The gap between proprietary models from OpenAI, Google, and Anthropic and their open-source counterparts is rapidly shrinking. In some cases, it has disappeared entirely. Today, we are diving deep into six game-changing open-source language models that are reshaping what is possible in AI: DeepSeek-R1-0528, Google’s Gemma 3, Microsoft’s Phi-4, Alibaba’s Qwen3-235B-A22B, Mistral AI’s latest offerings, and Meta’s Llama 4 collection.
Understanding the Architecture Revolution
Before we dive into specific models, let us clarify what we mean by “architecture” in the context of language models. Think of a model’s architecture as its blueprint—how the artificial neurons are connected, how information flows through the system, and how the model decides which parts of itself to activate for different tasks.
The Mixture-of-Experts Breakthrough
One of the most significant architectural innovations we are seeing is called Mixture-of-Experts (MoE). Imagine having a team of specialists where each expert handles specific types of problems. Instead of consulting everyone for every question, you only activate the relevant experts. That is essentially how MoE works in AI models.
DeepSeek-R1-0528 exemplifies this approach with its massive 671 billion total parameters—but here is the clever part: it only uses 37 billion parameters at any given time. The model has 128 different “experts,” and for each piece of text it processes, it dynamically chooses which experts to consult. This means you get the capability of a huge model with the computational cost of a much smaller one.
Qwen3-235B-A22B takes a similar approach but with different numbers: 235 billion total parameters with only 22 billion active during use. It is like having a massive library where you only need to open the books relevant to your current question, rather than reading the entire collection every time.
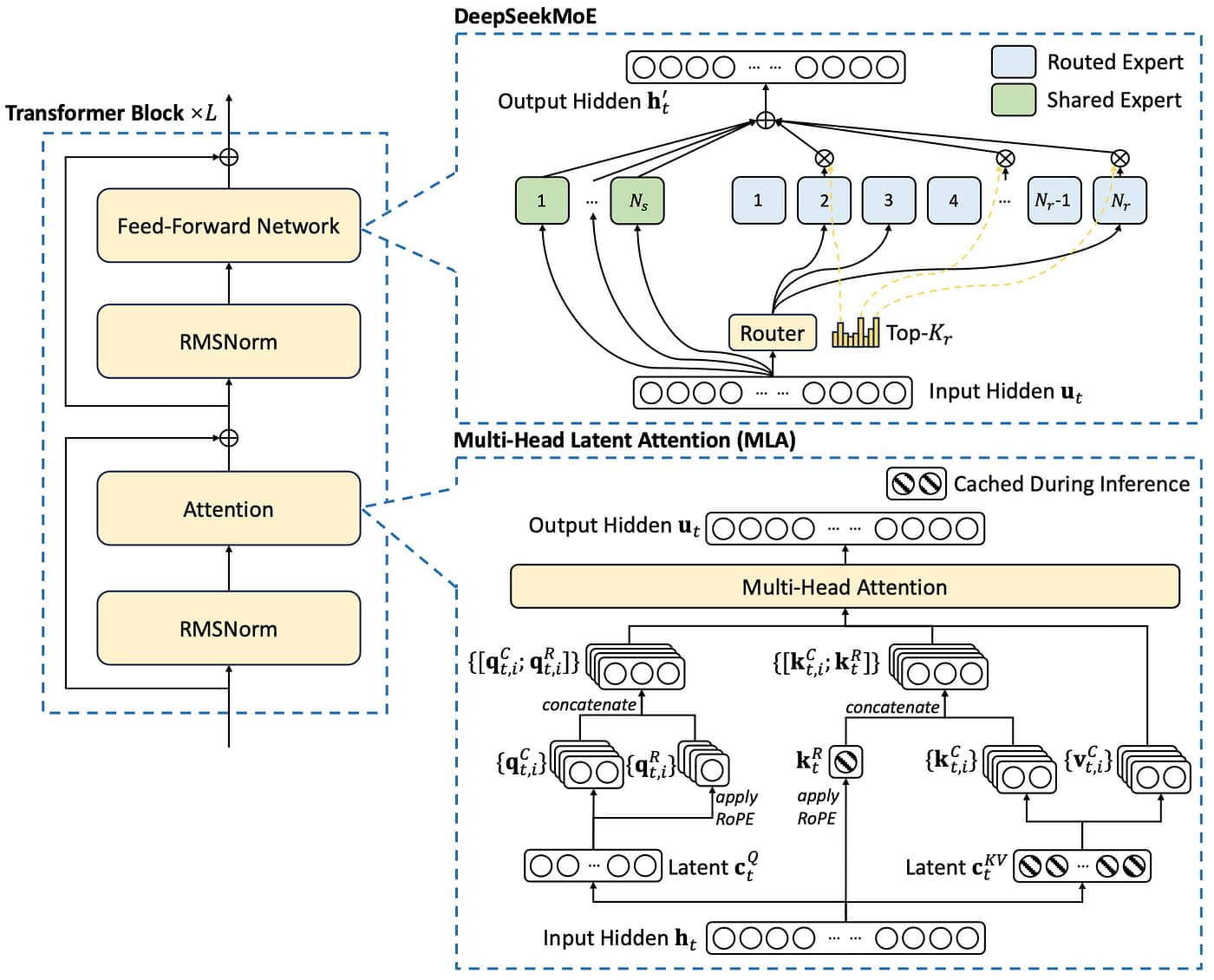
DeepSeek-R1 model architecture diagram showing the mixture of experts and multi-head latent attention towardsai
MoE architectures like DeepSeek-R1-0528 and Qwen3-235B-A22B achieve remarkable parameter efficiency, with DeepSeek activating only 37 billion of its 671 billion total parameters during inference (Hugging Faces). Dense models like Gemma 3-27B and Phi-4 utilize all parameters during computation, potentially offering more consistent performance across diverse tasks but requiring proportionally more computational resources (Microsoft).
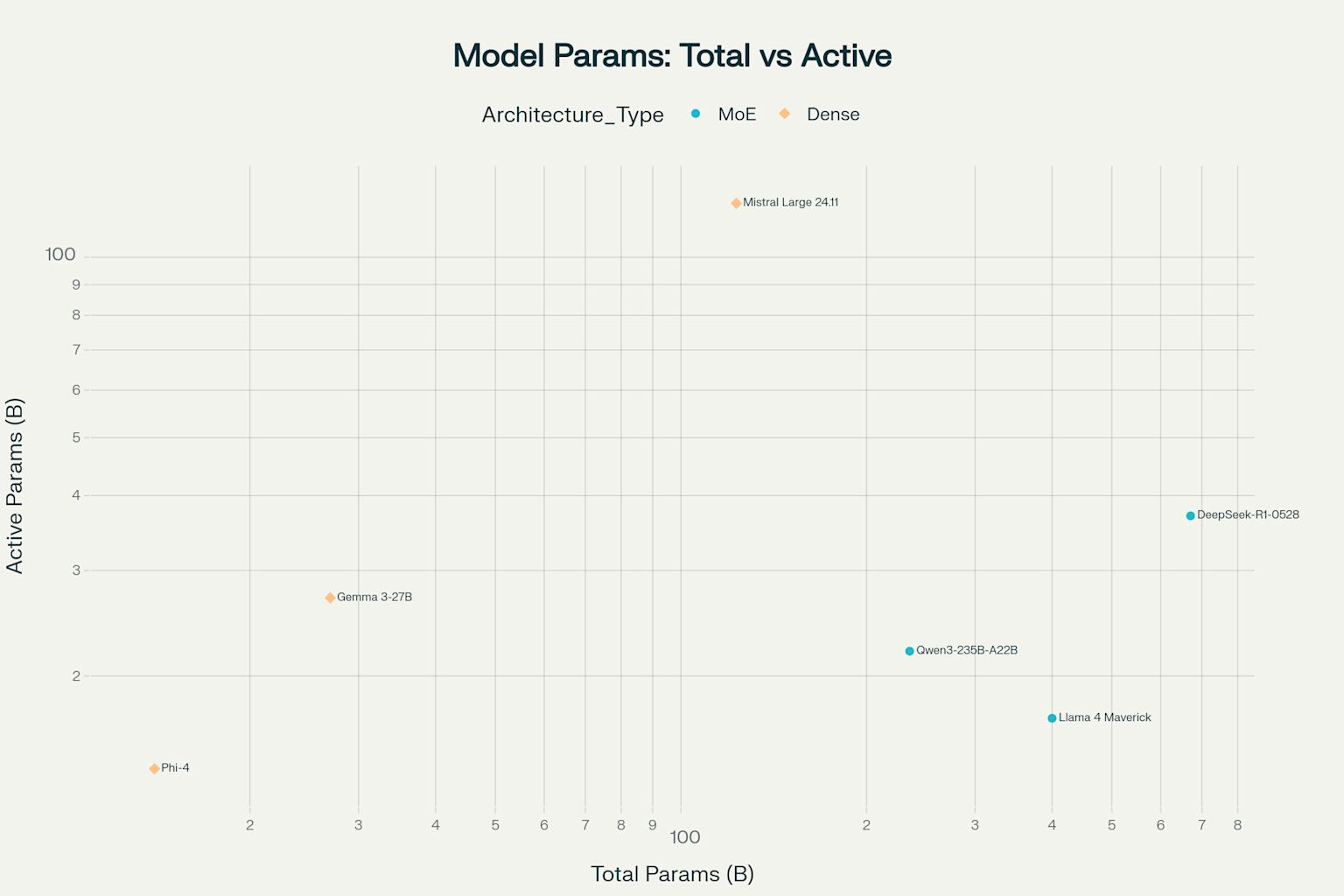
Model Architecture: Total vs Active Parameters Comparison
The key difference between Mixture-of-Experts and dense models shows important trade-offs in how they balance efficiency and consistency. MoE models like DeepSeek-R1-0528 and Qwen3-235B-A22B are highly efficient with their parameters—DeepSeek uses just 37 billion of its 671 billion parameters during operation. In contrast, Gemini’s dense architecture uses all parameters at once, potentially delivering more consistent performance across tasks but requiring substantially more computational power.
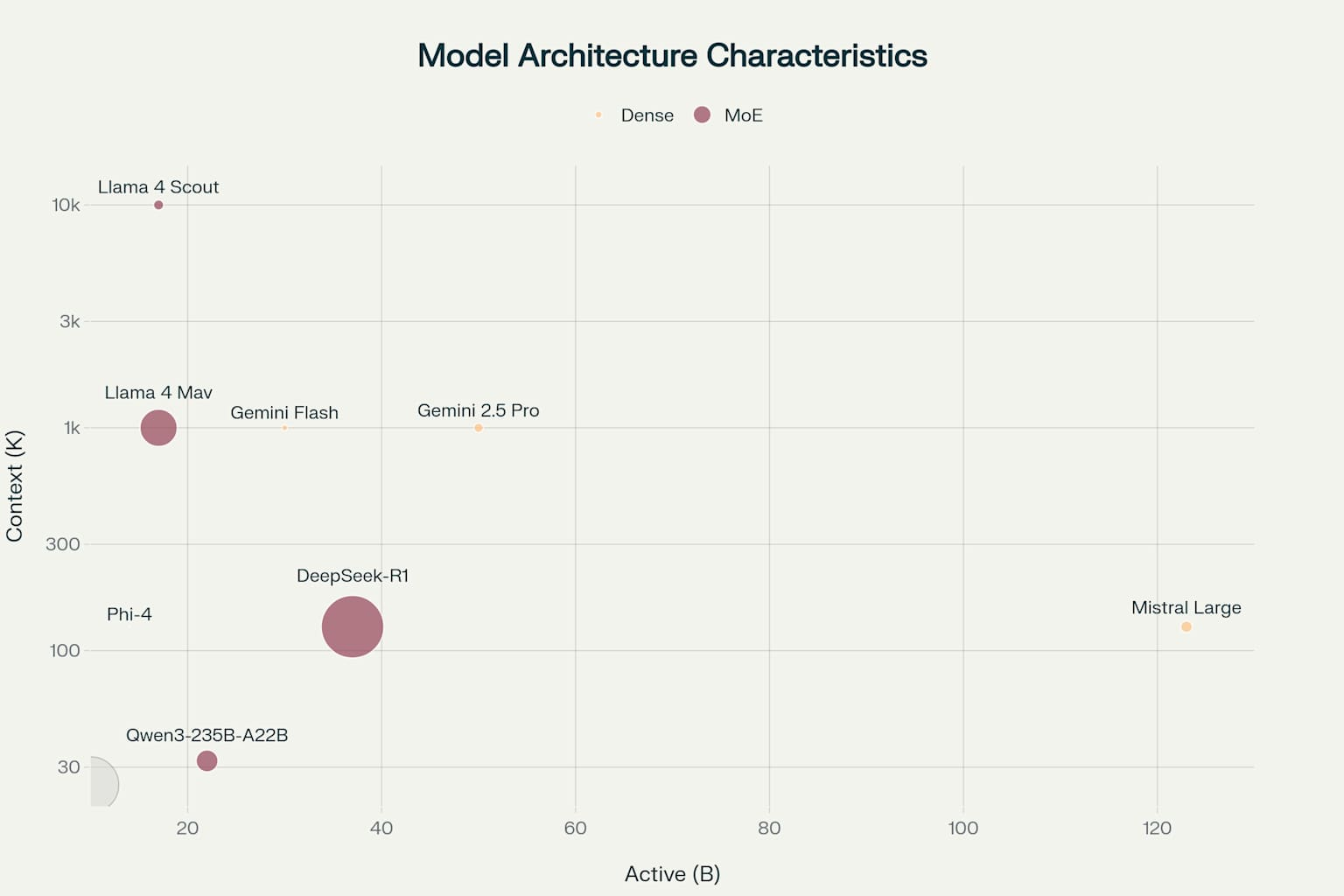
AI Model Architecture Comparison: Active Parameters, Context Windows, and Total Model Size
Dense Models: The Power of Focus
Not everyone is jumping on the MoE bandwagon. Gemma 3 and Mistral Large 24.11 use what is called dense architecture, where all parameters are active all the time. Think of this as having a smaller team of generalists who all work together on every problem.
Gemma 3’s innovation lies in how it handles attention—the mechanism that helps the model understand relationships between different parts of text. It uses a clever 5:1 pattern, alternating between looking at local context (the immediate surrounding words) and global context (the entire document). This reduces memory requirements from 60% to just 15% during operation, making it possible to process documents up to 128,000 tokens long—that is roughly a 300-page book!
Mistral Large 24.11, released in November 2024, represents Mistral AI’s flagship model with 123 billion parameters. It builds upon its predecessor with improved long context understanding, function calling capabilities, and system prompt adherence. While remaining dense, Mistral focuses on balanced performance across reasoning, knowledge, and coding tasks—competing directly with GPT-4 class models while maintaining the French startup’s commitment to efficiency.

Gemma 3 Architecture Analysis, including parameters, training infrastructure, and performance metrics
The Efficiency Champion: Phi-4
Microsoft’s Phi-4 proves that bigger is not always better. With “just” 14 billion parameters (tiny by today’s standards), it achieves performance that rivals models ten times its size. The secret? Instead of scaling up the model, Microsoft focused on scaling up the quality of training data. They used synthetic data—essentially AI-generated training examples—created by more advanced models like OpenAI’s o3-mini.
Llama 4: A New Era of Multimodal Intelligence
Meta’s Llama 4 collection represents a fundamental shift in how we think about language models. Released in April 2025, these models do not just process text—they are natively multimodal, meaning they were designed from the ground up to understand text, images, and video as one unified system.
The Llama 4 family includes three models, all using Mixture-of-Experts architecture:
- Llama 4 Scout: 109 billion total parameters (17 billion active), featuring an unprecedented 10 million token context window—that is enough to process an entire novel series at once
- Llama 4 Maverick: 400 billion total parameters (17 billion active), designed as the flagship model for complex reasoning and multimodal tasks
- Llama 4 Behemoth: Nearly 2 trillion total parameters (288 billion active), serving as a teacher model for the others (not publicly released)
What makes Llama 4 special is its “early fusion” approach. Instead of training on text first and then adapting to images later (like most models), Llama 4 was trained on text, images, and video simultaneously. This creates a deeper understanding of how different types of information relate to each other.
Mistral AI: The European Challenger
Mistral AI, founded in 2023 by former researchers from Google DeepMind and Meta, has quickly established itself as Europe’s leading AI company. Their strategy focuses on efficiency without compromising performance—a philosophy evident in their entire model lineup.
Mistral AI prioritizes practical, real-world performance over benchmark scores. This pragmatic approach appeals to developers and enterprises seeking efficient AI solutions. Their models excel at both general language tasks and specialized functions like coding and document processing.

Beyond Mistral Large 24.11, the company offers:
- Mistral Medium 3: Released in May 2025, priced at just $0.40 per million input tokens, performing at 90% of Claude Sonnet 3.7’s level
- Mistral Small 3.1: Can run on a single RTX 4090 GPU or Mac with 32GB RAM, processing 150 tokens per second
- Codestral: Specialized for code generation, with the latest version (25.01) generating code 2.5x faster than its predecessor
- Mistral OCR: Converts PDFs to Markdown for easier processing by language models
- Pixtral Large: A 124-billion parameter multimodal model for vision and text understanding
The Art and Science of Training
Creating these models is not just about designing the architecture; it is about how you train them. Two techniques dominate the landscape: distillation and reinforcement learning (RL).
Knowledge Distillation: Teaching Smaller Models to Think Big
Distillation is like having a master chef teach an apprentice. The master (a large, powerful model) demonstrates how to solve problems, and the apprentice (a smaller model) learns to replicate that behavior.
DeepSeek showcases this beautifully with their DeepSeek-R1-0528-Qwen3-8B variant. They took their massive 671-billion parameter model and distilled its reasoning capabilities into a model with just 8 billion parameters. The result? A model that can run on a high-end gaming PC while maintaining much of the reasoning power of its massive teacher.

Reinforcement Learning: Learning from Feedback
Reinforcement Learning is how these models learn to align with human preferences. Think of it as a continuous improvement process where the model tries different approaches, gets feedback on what works, and adjusts accordingly.
DeepSeek uses a sophisticated multi-stage RL process:
- First, they train on high-quality examples of step-by-step reasoning
- Then, they use Group Relative Policy Optimization (GRPO)—a technique that helps the model learn which reasoning patterns work best
- Finally, they apply broader alignment training to ensure the model is helpful and harmless
Gemma 3 takes a multi-faceted approach, using different types of feedback for different capabilities:
- Human feedback for general helpfulness
- Mathematical ground truth for accuracy in calculations
- Code execution results for programming tasks
Llama 4’s Training Innovation: Co-Distillation
Meta’s approach with Llama 4 introduces a novel “co-distillation” technique. Instead of training the smaller models after the large one is complete, they trained all three models together. Behemoth (the 2-trillion parameter teacher) guides Scout and Maverick during their training, using a dynamic loss function that balances learning from both the teacher model and the actual training data.
The training also employed Meta’s new “MetaP” technique—a method for setting hyperparameters that transfer well across different model sizes. This means the optimal settings discovered for one model can be applied to others, dramatically speeding up the development process.
Mistral’s Efficiency-First Training
Mistral AI takes a different approach, focusing on extracting maximum performance from smaller architectures. While specific training details for Mistral Large 24.11 remain proprietary, the company has emphasized their use of:
- Direct Preference Optimization (DPO) for aligning with human preferences
- Sophisticated data curation to ensure quality over quantity
- Continuous refinement based on real-world usage patterns from their Le Chat platform
Mistral Small 3.1’s remarkable efficiency—running on consumer hardware while maintaining competitive performance—showcases their commitment to algorithmic improvements over brute-force scaling.
Performance Showdown: How Do They Stack Up?
Now for the part everyone’s been waiting for: how do these open-source models actually perform compared to the big names like GPT-4, Claude, and Gemini?
Mathematical Reasoning: The AIME Test
The AIME (American Invitational Mathematics Examination) has become a gold standard for testing AI reasoning capabilities. Here’s how our contenders performed on AIME 2025:
- Grok 3 (xAI): 93.3%
- OpenAI o4-mini: 92.7% (corrected from earlier reports of 93.4%)
- OpenAI o3: 88.9% (not 91.6% as sometimes reported)
- DeepSeek-R1-0528: 87.5%
- Gemini 2.5 Pro: 86.7%
- Qwen3-235B-A22B: 81.5%
- Phi-4-reasoning-plus: 78.0%
What is remarkable here is that DeepSeek, a fully open-source model, is within 5 percentage points of OpenAI’s most advanced offerings. That is like a community-built race car keeping pace with Formula 1 vehicles.
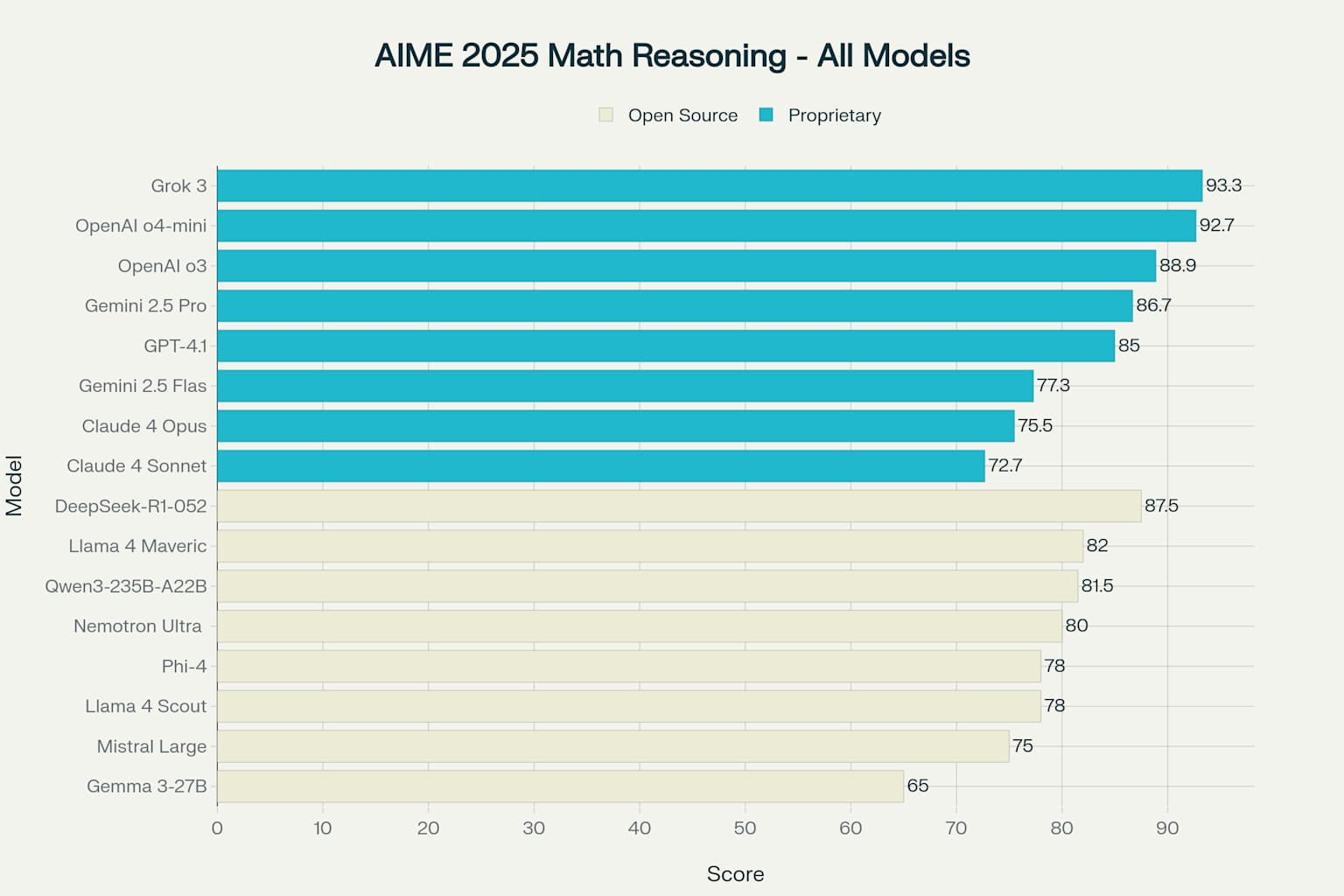
AIME 2025 Mathematical Reasoning Performance Comparison Across All Models
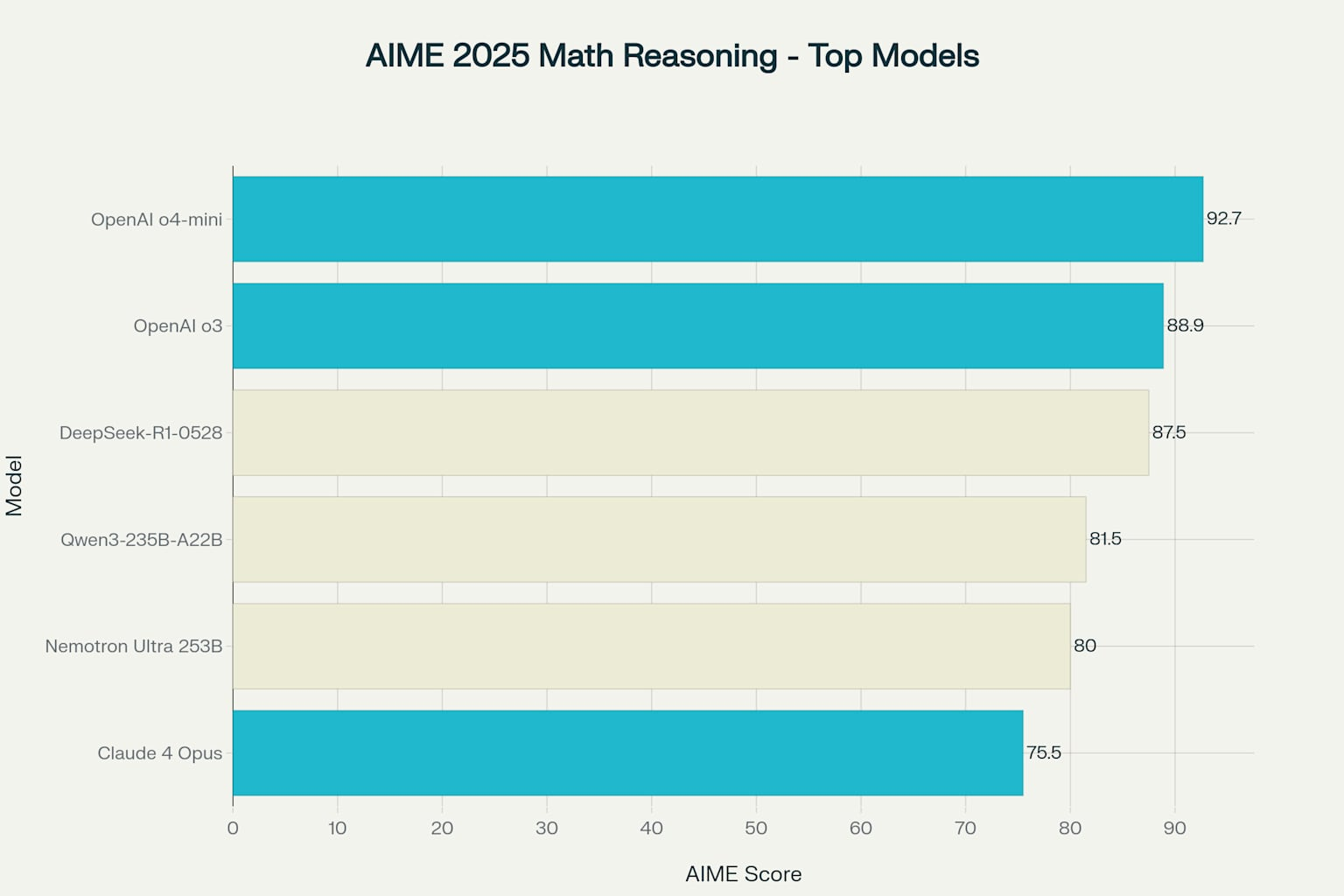
AIME 2025 Mathematical Reasoning - Top 3 Proprietary vs Top 3 Open Source Models
Elementary Mathematics and Specialized Performance
In elementary mathematics benchmarks like GSM8K, open-source models have achieved remarkable results. Gemma 3-27B leads with an impressive 95.9% accuracy, while Qwen3-235B-A22B follows closely at 95.0%. These scores demonstrate how open-source models can excel in specialized domains through careful optimization and focused training.
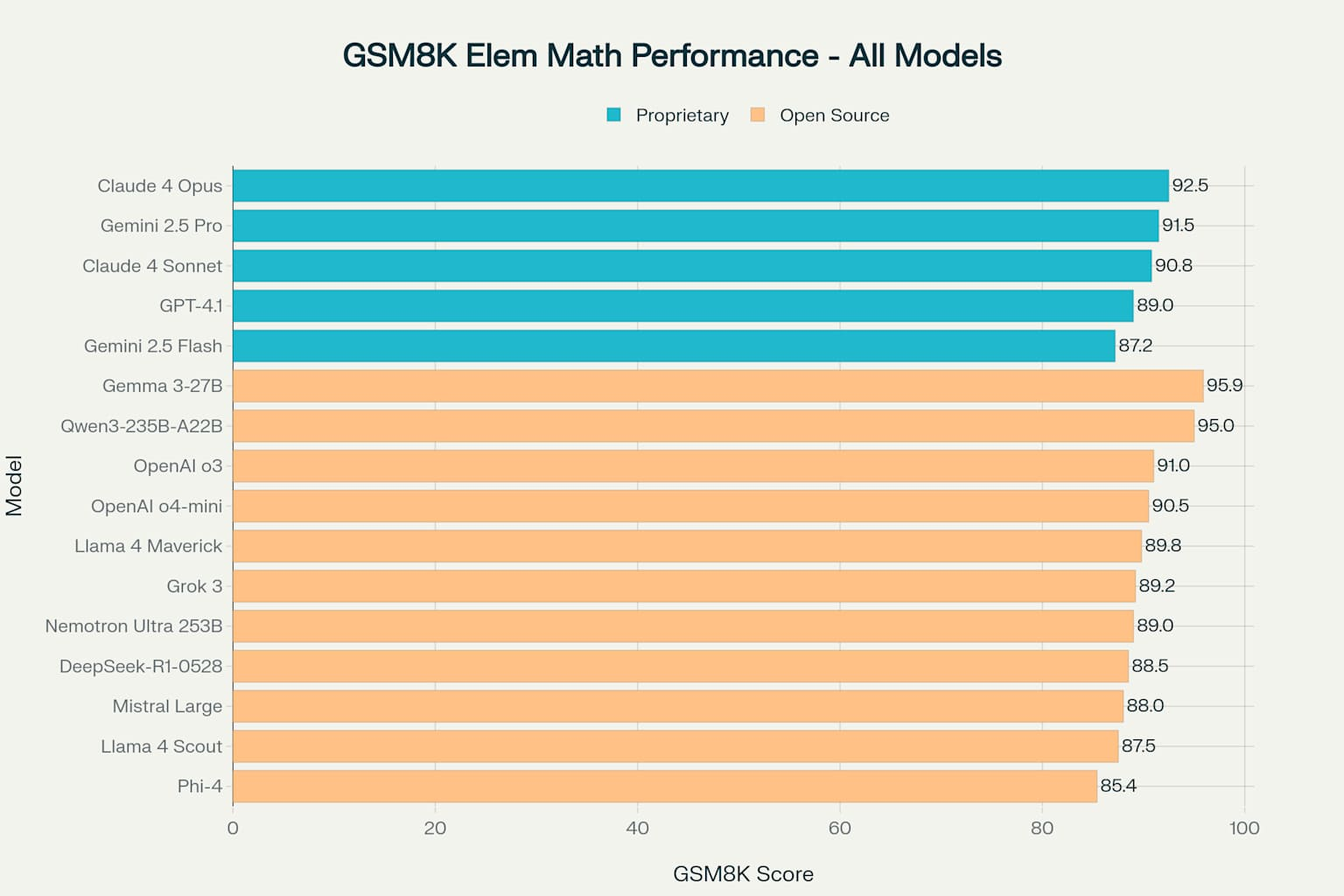
GSM8K Elementary Math Performance Comparison Across All Language Models
Coding Capabilities: Building the Future
On coding benchmarks, the competition is equally fierce:
- LiveCodeBench results show DeepSeek-R1-0528 achieving 73.3%, outperforming many proprietary models
- Phi-4 scores 82.6% on HumanEval, proving that its small size does not limit its coding abilities
- Qwen3-235B-A22B achieves 70.7% on LiveCodeBench, demonstrating strong performance across programming tasks
- Llama 4 Maverick achieves 86.4% on HumanEval, showing Meta’s focus on practical coding capabilities
- Mistral’s Codestral 25.01 generates code 2.5x faster than its predecessor, supporting over 80 programming languages
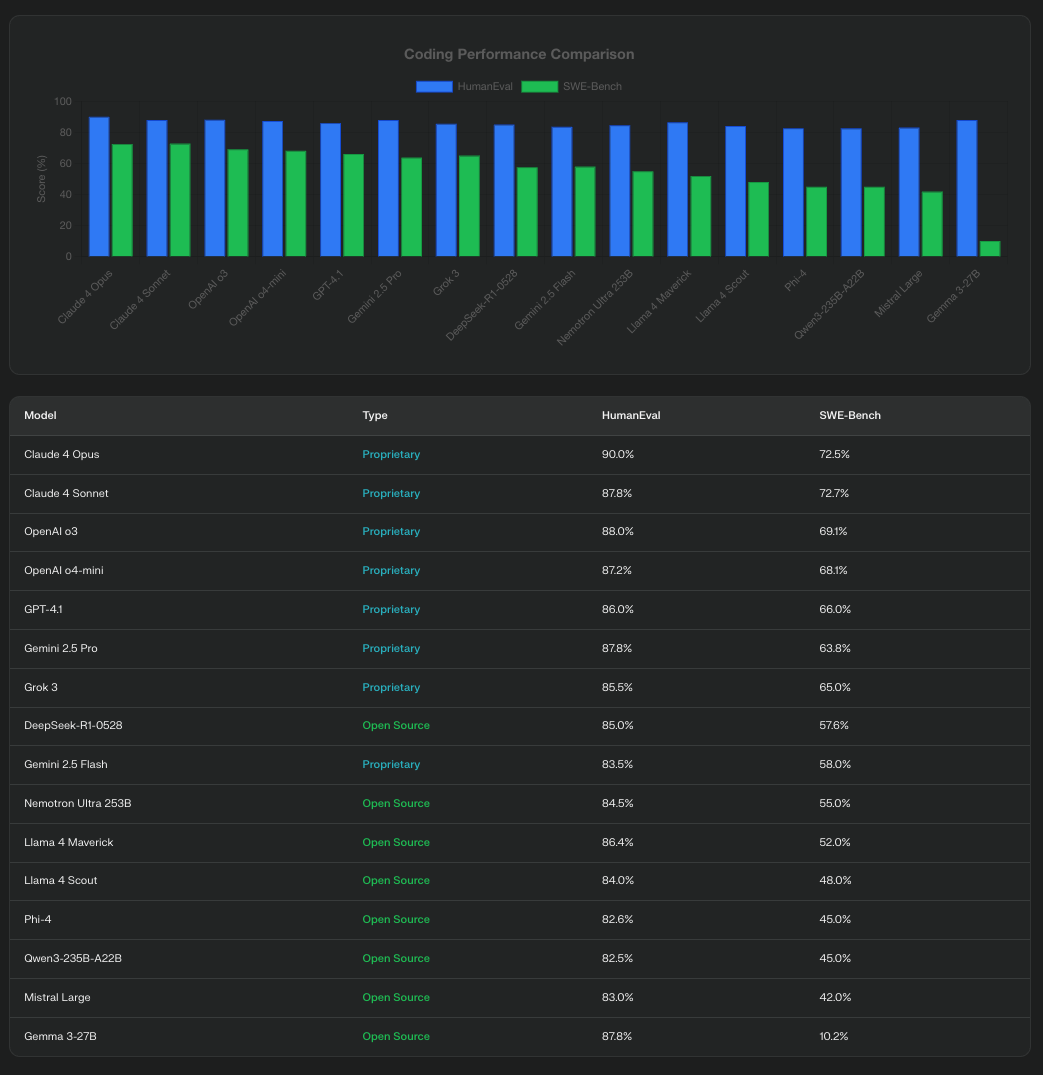
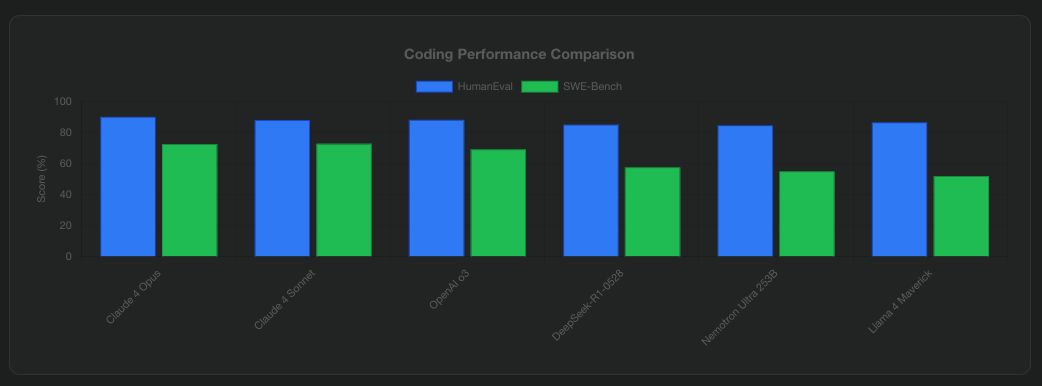
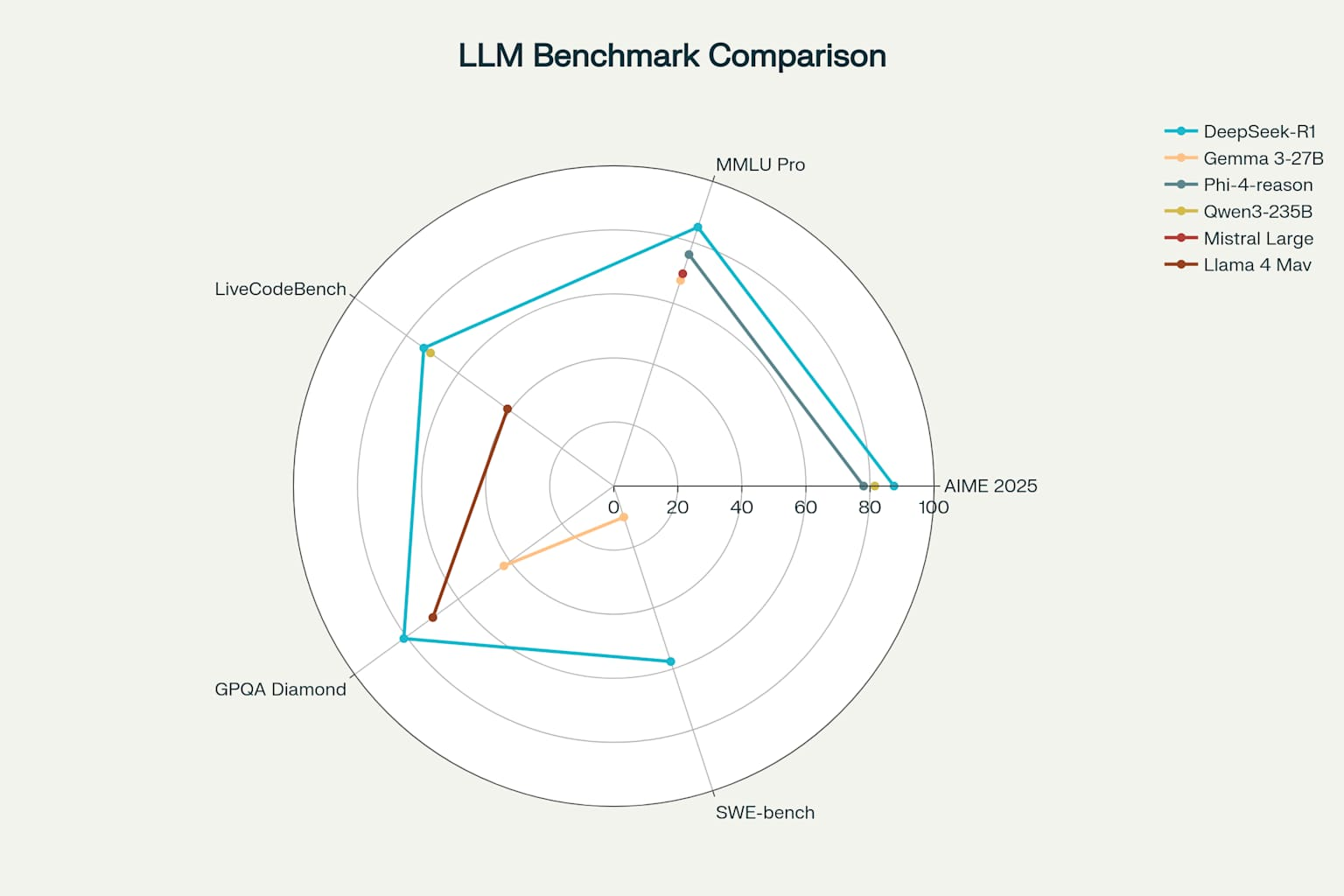
Multi-Benchmark Performance Comparison: Top Open-Source Models
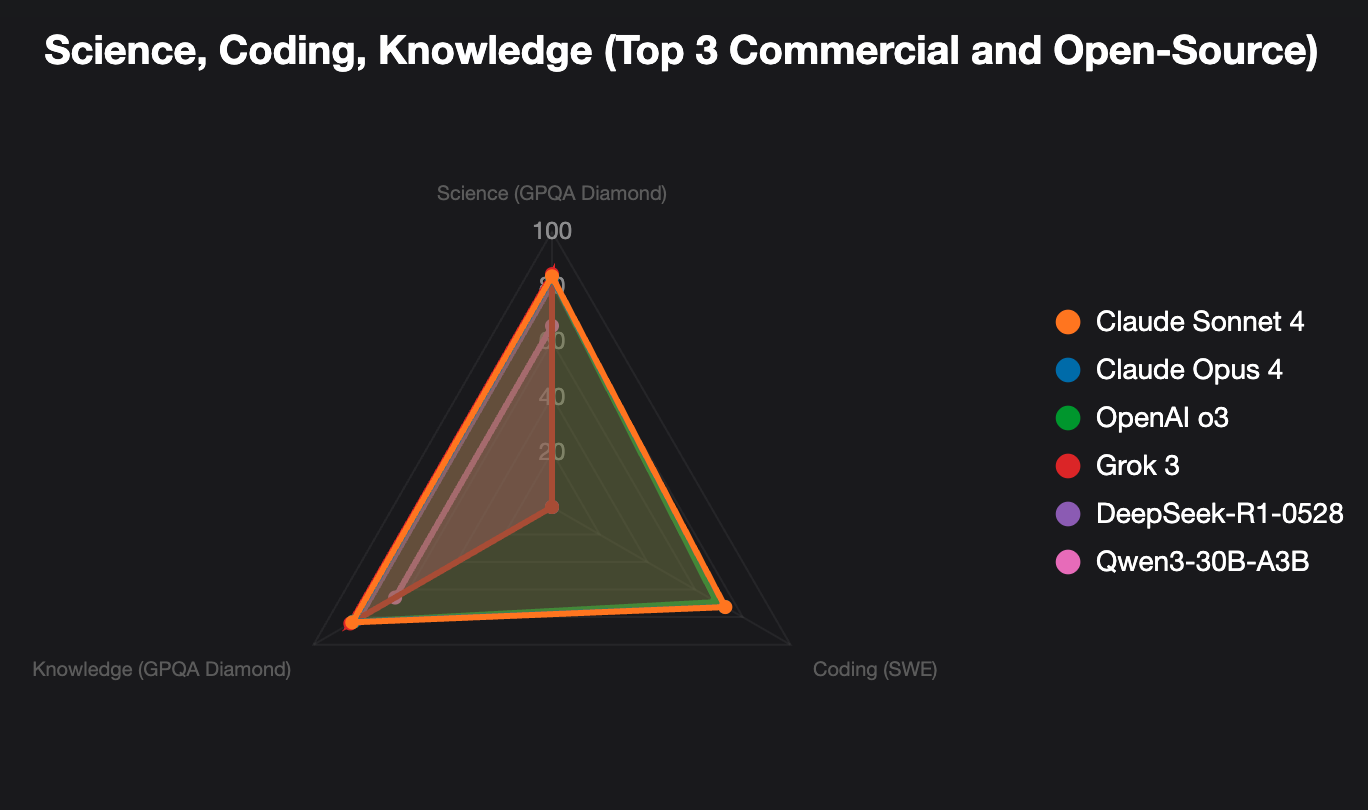
Get very close between the commerical and open source models
On the GPQA Diamond scientific reasoning benchmark, proprietary models maintain their lead, with Grok 3 (84.6%), Gemini 2.5 Pro (84.0%), and OpenAI o3 (83.3%) topping the rankings. Yet DeepSeek-R1-0528’s strong showing at 81.0% demonstrates that open-source models are closing the gap in advanced scientific reasoning.
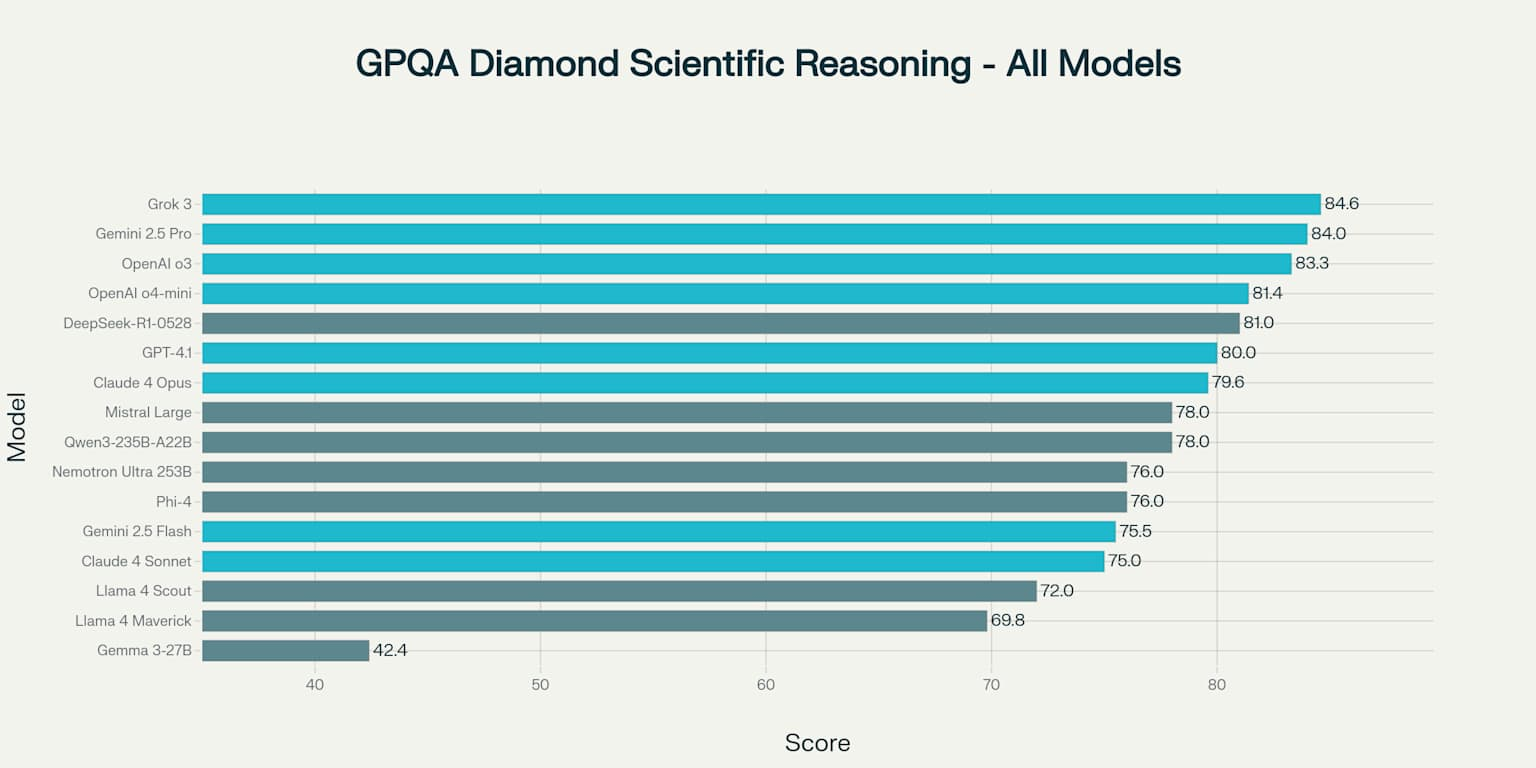
GPQA Diamond Scientific Reasoning Performance Across All Language Models
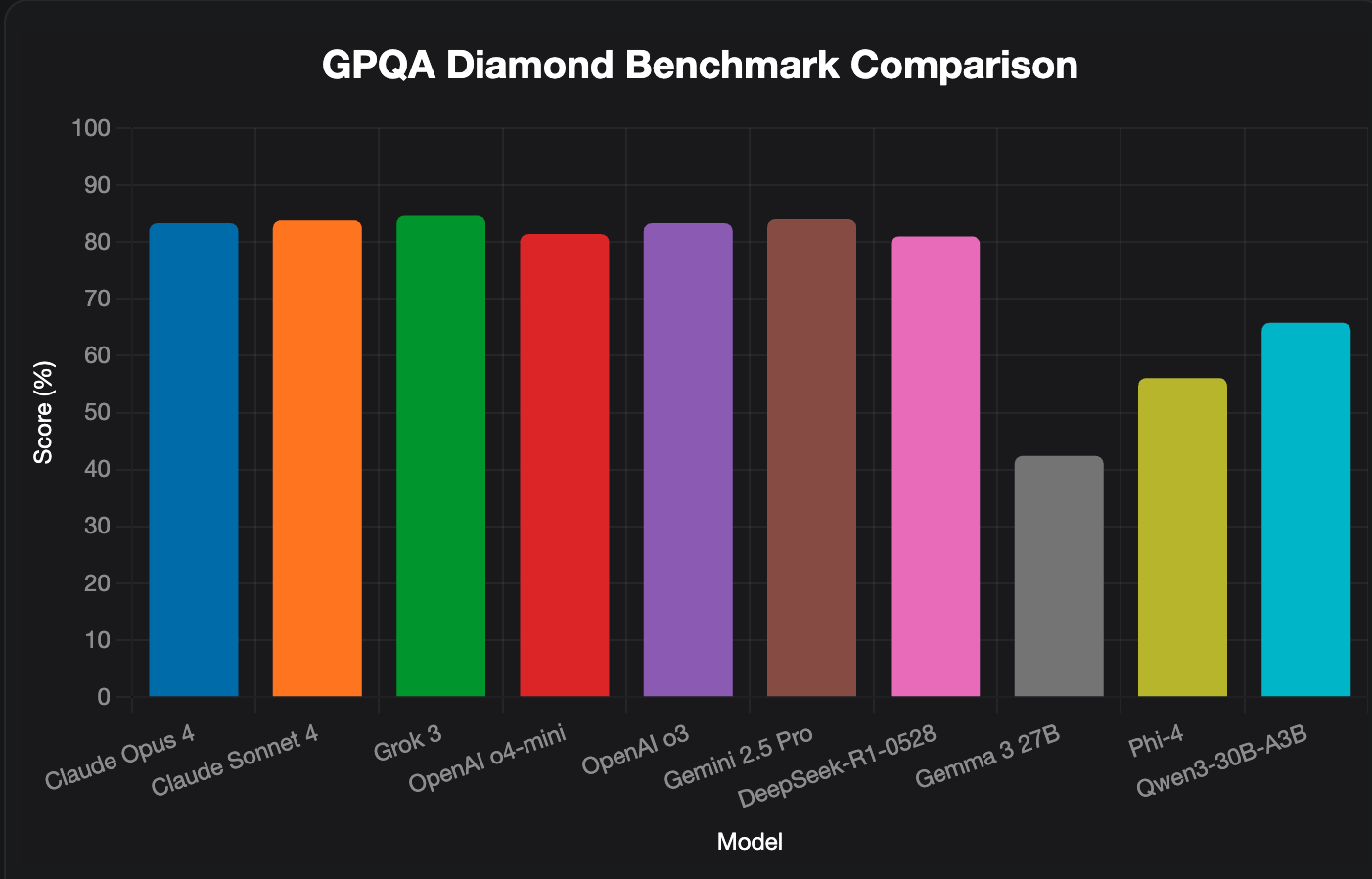
GPQA Diamond Scientific Reasoning Performance Across Top Models
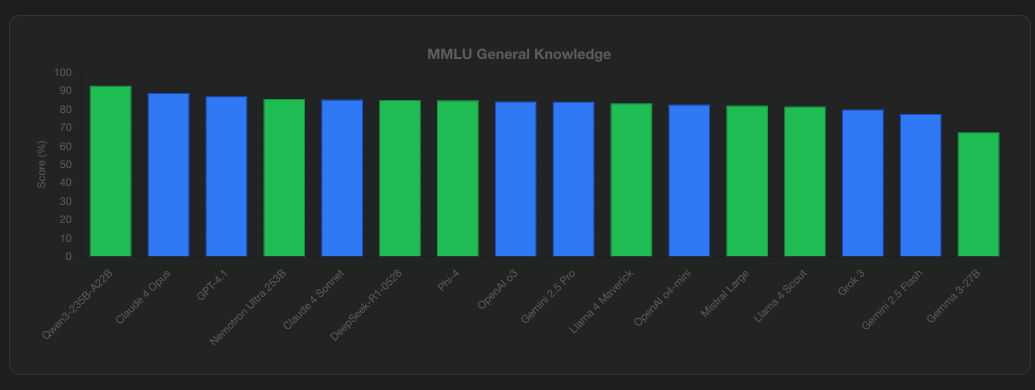
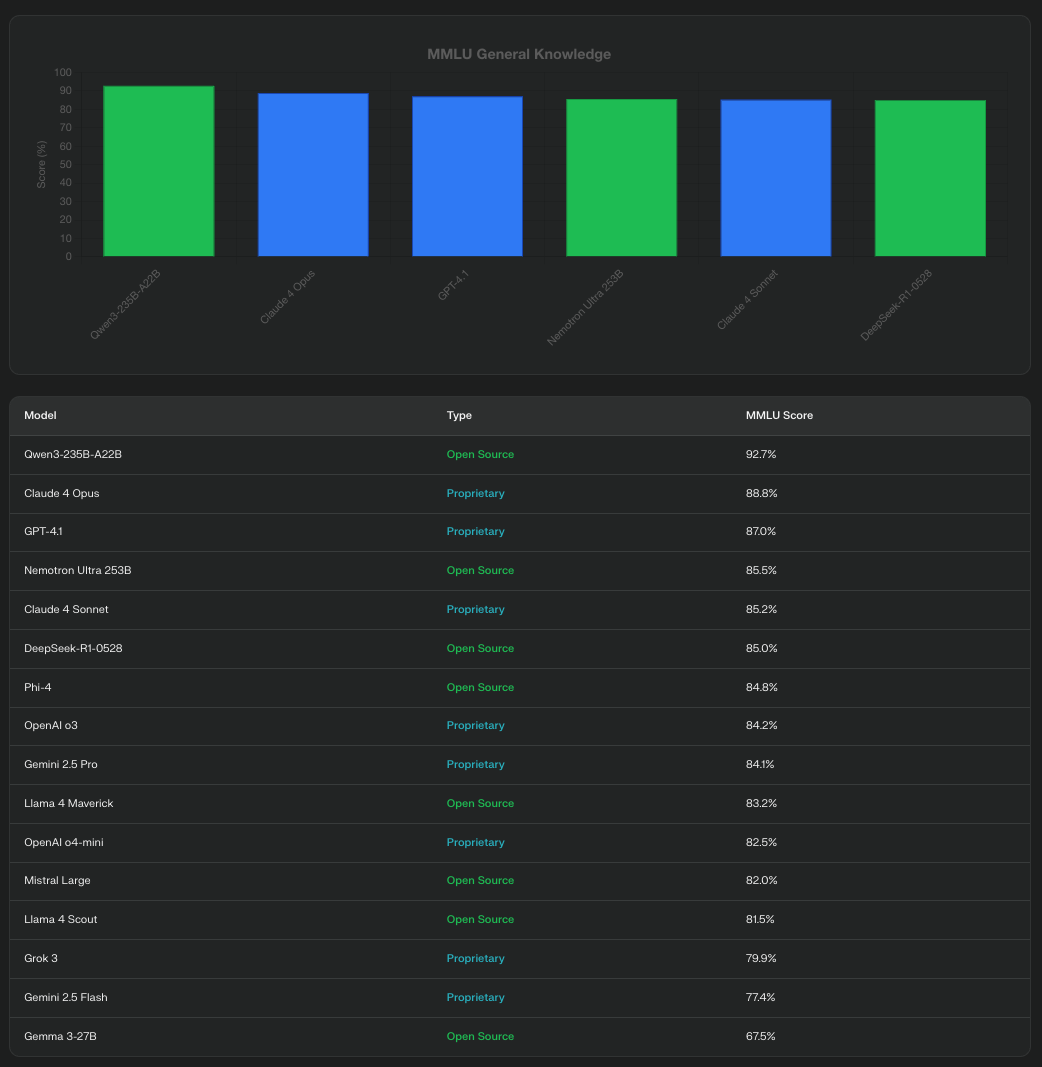
General Knowledge: The MMLU Test
The Massive Multitask Language Understanding (MMLU) benchmark tests models across diverse subjects from history to quantum physics:
- Qwen3-235B-A22B leads with an impressive 92.7% on MMLU-Redux
- DeepSeek-R1-0528 achieves 85.0% on MMLU-Pro
- Gemini 2.5 Pro scores 84.1%
- Phi-4 manages 84.8% on standard MMLU despite its smaller size
- Llama 4 Maverick scores 80.5% on MMLU Pro, demonstrating strong general knowledge
- Llama 4 Scout achieves 74.3%, impressive given its focus on efficiency
Visual Understanding: The New Frontier
The multimodal capabilities of these models represent a crucial advancement:
- Llama 4 Scout scores 88.8 on ChartQA and 94.4 on DocVQA, outperforming many specialized vision models
- Llama 4 Maverick excels at complex visual reasoning tasks, processing up to 8 images in a single prompt
- Mistral’s Pixtral Large offers 124 billion parameters dedicated to vision-language tasks
- Gemma 3’s multimodal variants use SigLIP encoding for efficient image processing
Getting Your Hands on These Models
So you are convinced these models are worth trying—how do you actually use them?
Official Channels
DeepSeek offers multiple access options:
- Their official API supports up to 64,000 tokens of generation (including reasoning steps)
- Models are available on Hugging Face for download
- Quantized versions can run locally through Ollama
Gemma 3 is available through:
- Google AI Studio
- Hugging Face with full integration into the Transformers library
- Direct download for local deployment
Microsoft Phi-4 can be accessed via:
- Azure AI Foundry (with both free and paid tiers)
- Hugging Face under MIT license
- NVIDIA NIM APIs for the multimodal variant
Mistral AI offers access through:
- La Plateforme (Mistral’s official API platform)
- Microsoft Azure AI Foundry
- Google Cloud Vertex AI
- Amazon SageMaker and Bedrock
Meta’s Llama 4 is available via:
- Hugging Face with full transformers integration
- Amazon Bedrock (supporting up to 3.5M tokens for Scout)
- IBM watsonx.ai
- NVIDIA NIM microservices
- Meta’s own apps (WhatsApp, Instagram) through Meta AI
Third-Party Platforms
Perplexity AI Pro has emerged as a popular option, offering a $20/month subscription that includes access to:
- GPT-4.1
- Claude 4.0 Sonnet
- Gemini 2.5 Pro
- Grok 3 Beta
- Their own Sonar Large model (based on Llama 3.1)
- DeepSeek-powered reasoning capabilities through their advanced search features
What is particularly interesting about Perplexity is how they have integrated DeepSeek’s reasoning capabilities into their platform. When you use Perplexity’s Pro Search feature, it can leverage DeepSeek’s step-by-step reasoning approach to break down complex queries, research multiple angles, and synthesize comprehensive answers. This means you get the power of DeepSeek’s advanced reasoning without needing to manage the infrastructure yourself.
OpenRouter provides a unified API to access over 300 models from 50+ providers, including all major DeepSeek variants. They offer competitive pricing and detailed performance metrics to help you choose the right model.
Local Deployment: Running AI on Your Own Hardware
One of the biggest advantages of open-source models is the ability to run them locally. Here is what you need:
For DeepSeek-R1-0528:
- Full model: 715GB disk space, suitable for data centers
- Quantized version: 162GB disk space, needs 192GB RAM
- Distilled 8B version: Just 20GB RAM—runs on high-end consumer hardware
For smaller models like Phi-4:
- Can run on a single NVIDIA RTX 4090 or similar
- Quantized versions work on Apple M1/M2 Macs with 16GB+ RAM
For Llama 4 Scout:
- Optimized to run on a single H100 GPU with 4-bit or 8-bit quantization
- BF16 and FP8 formats available for different hardware configurations
- Available under Llama 4 Community License Agreement
For Mistral Small 3.1:
- Runs on a single RTX 4090 GPU
- Works on Mac laptops with 32GB RAM
- Processes at 150 tokens per second on consumer hardware
The Implications: What This Means for AI’s Future
The rapid advancement of open-source models signals a fundamental shift in AI development. We are moving from a world where cutting-edge AI was the exclusive domain of tech giants to one where innovation can come from anywhere.
Consider the cost implications:
- Gemini 2.5 Flash delivers 77.3% performance on AIME 2025 at just $0.26 per million tokens
- Mistral Medium 3 offers 90% of Claude Sonnet 3.7’s performance at $0.40 per million input tokens
- Compare that to OpenAI’s o3 at $17.50 per million tokens for 88.9% performance
- For many applications, these cost-effective alternatives provide more than enough capability
The democratization extends beyond cost. Researchers worldwide can now examine, modify, and improve these models. Companies can deploy them on-premise for sensitive applications. Developers can fine-tune them for specific use cases without sending data to third parties.
The emergence of natively multimodal models like Llama 4 represents another crucial shift. Instead of retrofitting text models to handle images, we now have AI systems that understand different types of information as a unified whole. This opens doors to applications we are only beginning to imagine—from advanced robotics to immersive educational experiences.
Cost and Performance, the engineering tradeoff
Let us put this all into perspective. Each model comes with its own costs, and you will need to evaluate what works best for your project. In my experience, a model’s benchmark performance does not always match its real-world effectiveness. When choosing a model, carefully weigh both the costs and your specific use case. Remember that you can also optimize LLMs for particular applications through fine-tuning.

Cost vs Performance Analysis: Finding the Sweet Spot in AI Model Selection
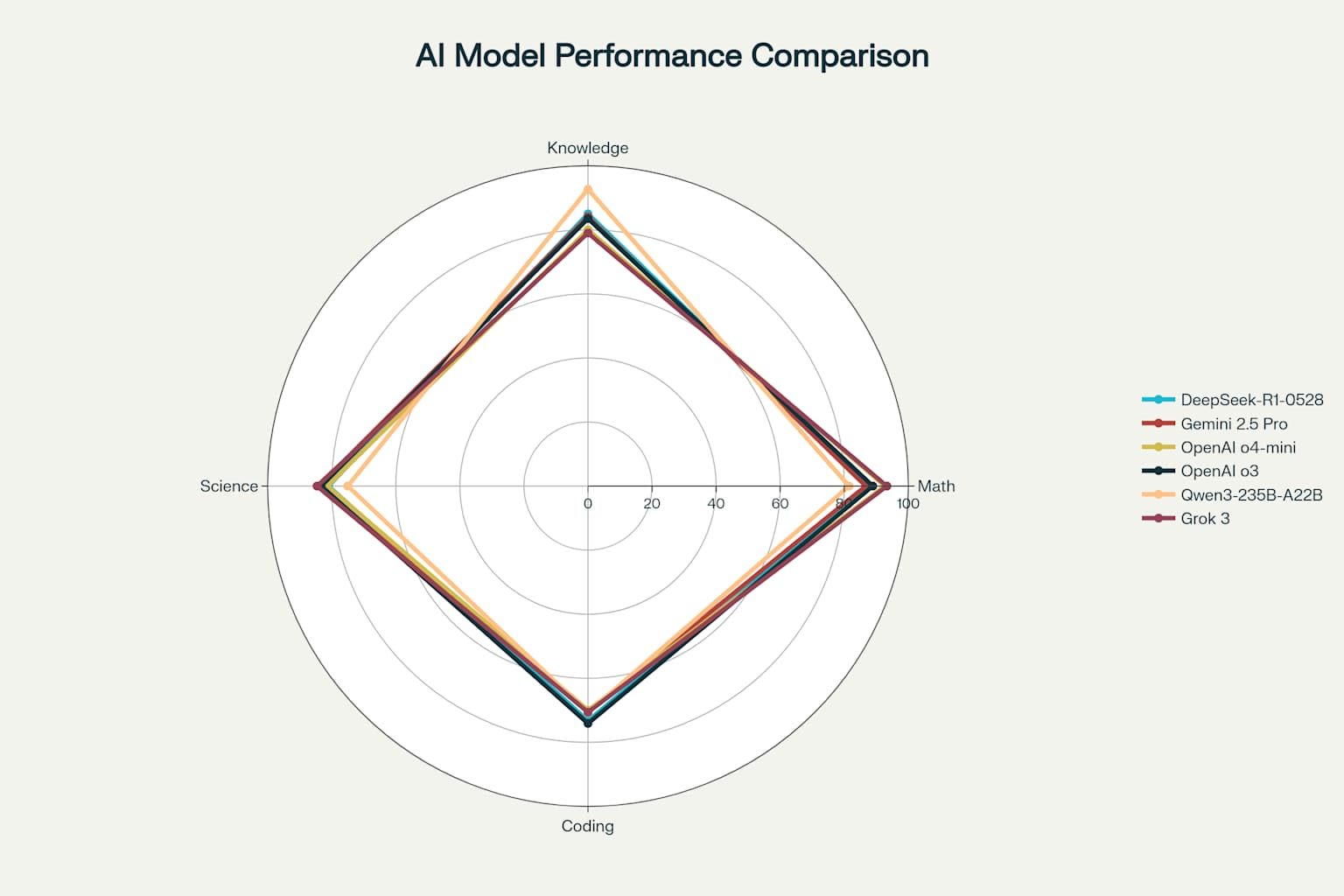
Performance is narrowing
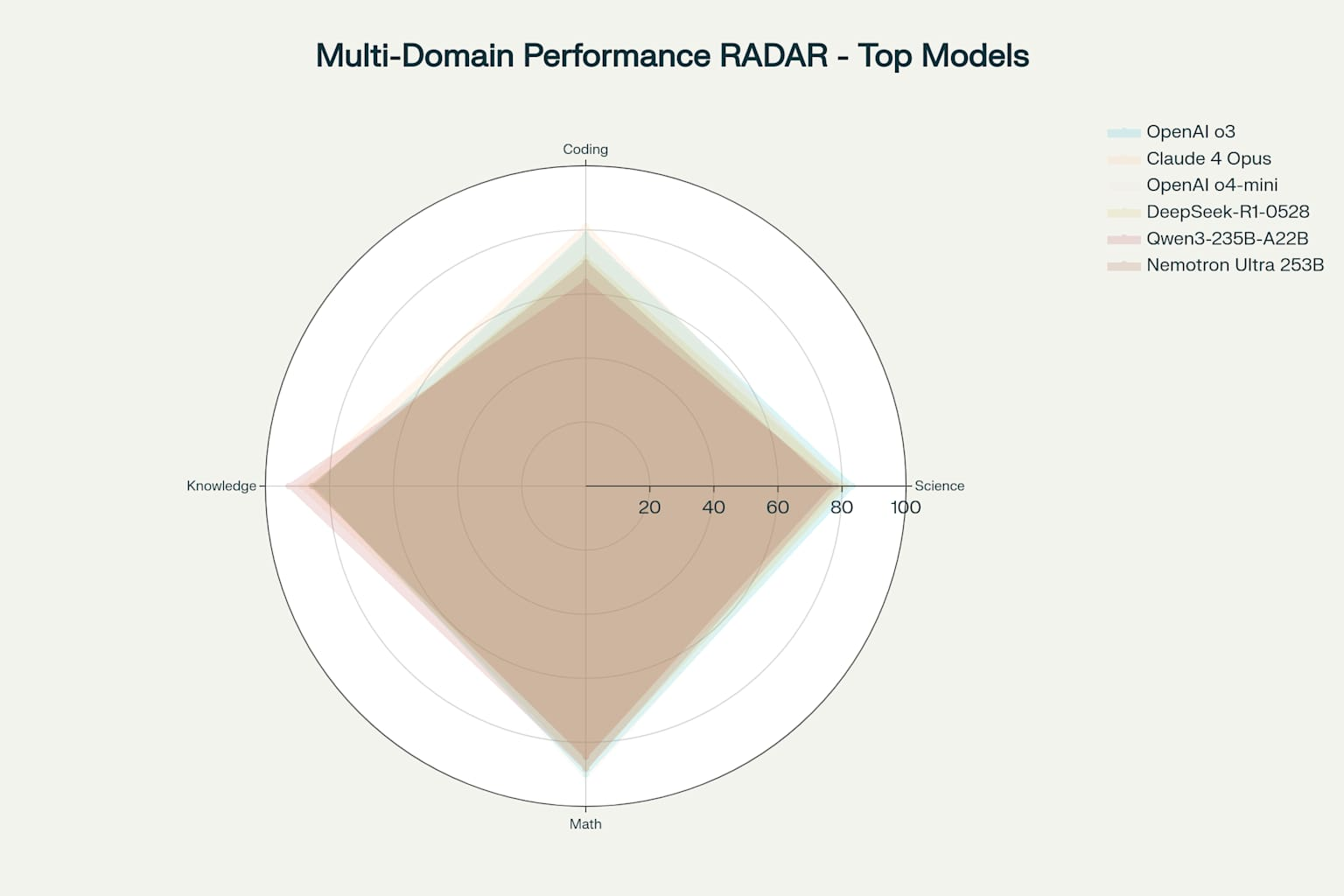
Let’s look at the overall performance of each of these models.
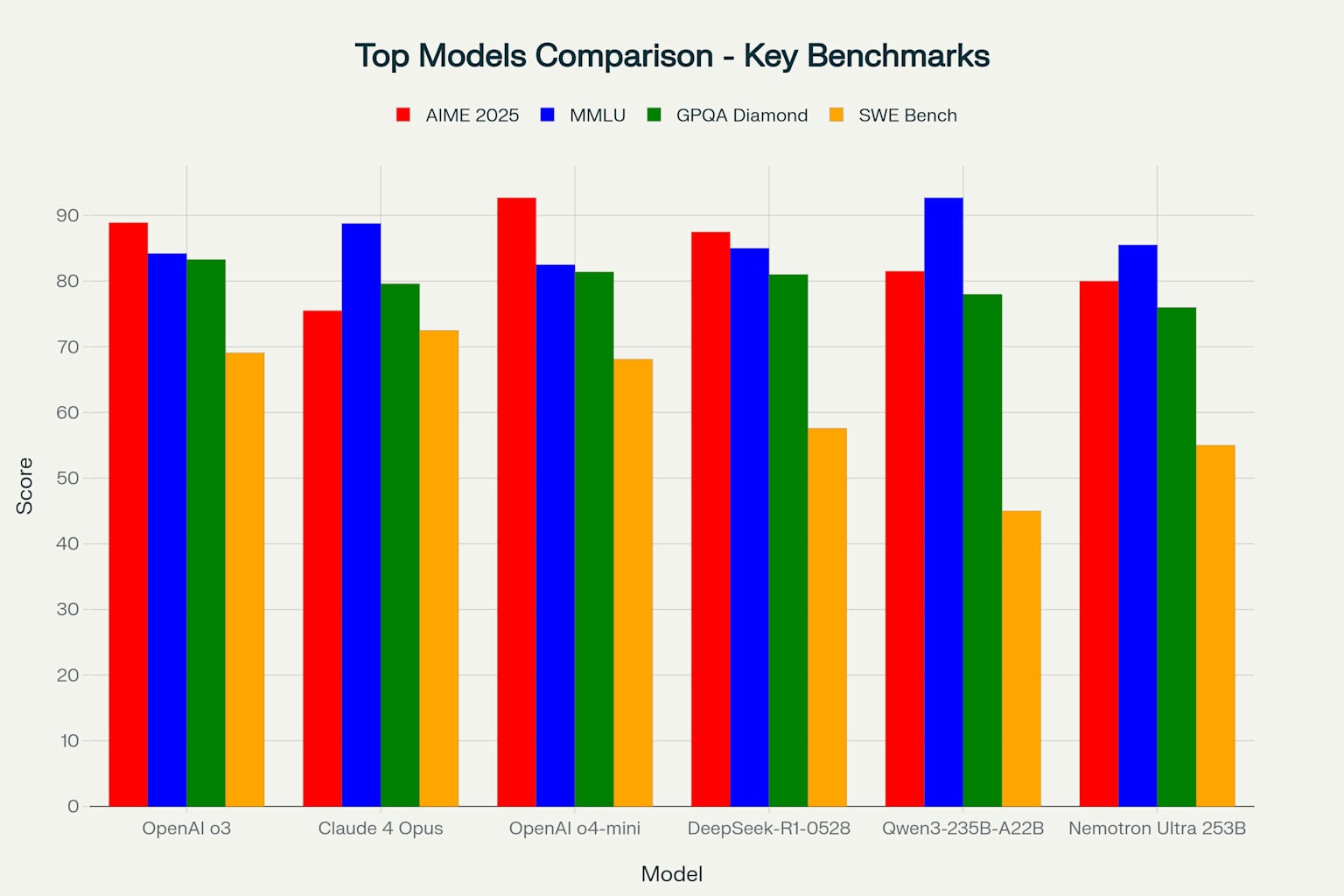
Top Models Performance Comparison Across Key Benchmarks
If we average out the performance, we can see the performance between the top commercial model and the top open source model is 3.4%.
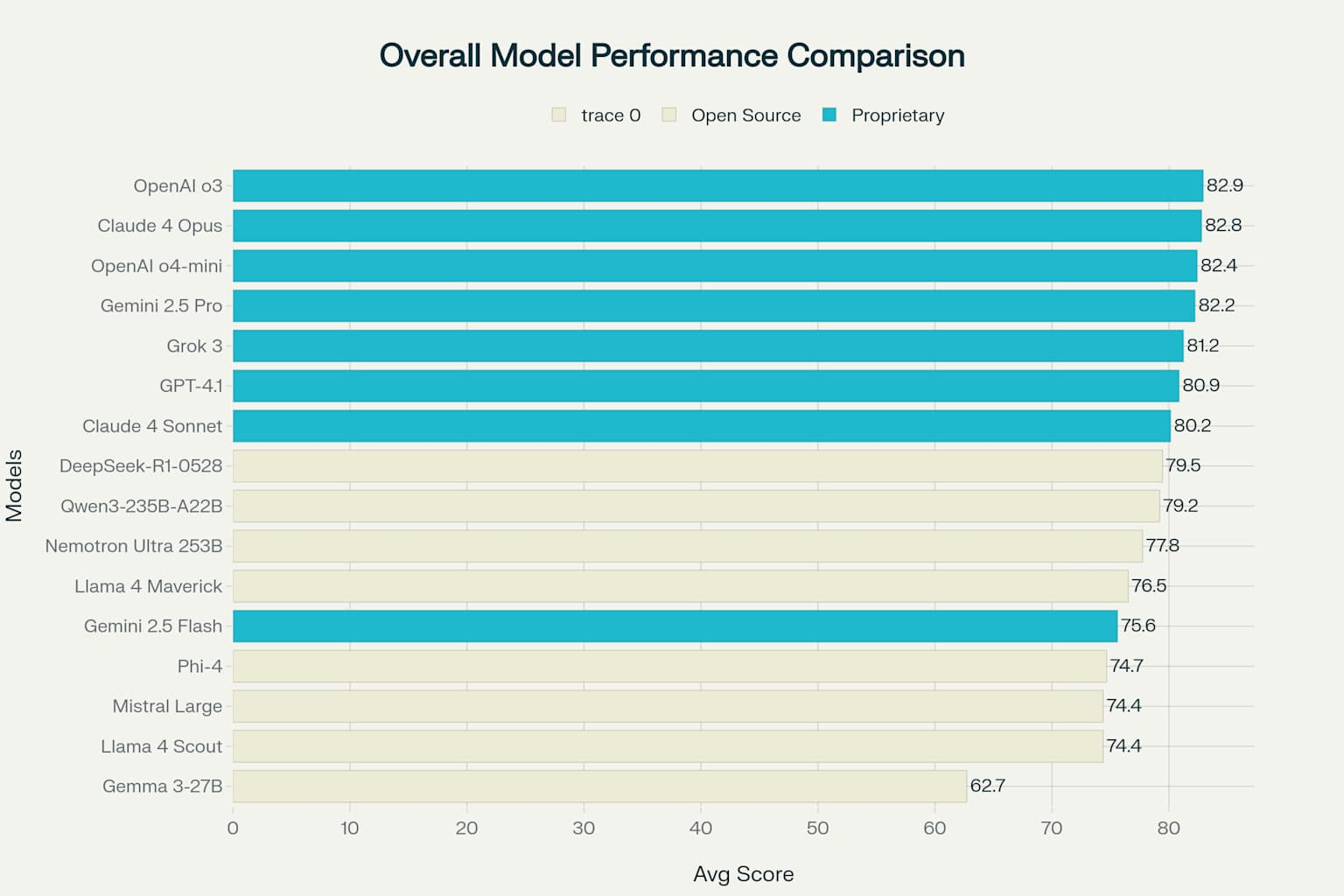
Overall Language Model Performance - Average Across All Benchmarks
When choosing between these models, organizations should carefully assess their specific needs. Consider not just raw performance metrics, but also practical factors like budget limitations, deployment requirements, and unique use cases. The rich ecosystem of options means you can find the right balance for your situation.
This shift toward accessible, high-quality open-source AI is revolutionary. It is democratizing advanced language capabilities, spurring healthy competition, and accelerating innovation across the entire field. Both proprietary and open-source models are pushing each other to new heights, ultimately benefiting everyone in the AI community.
Looking Ahead: The Next Chapter
As we stand in mid-2025, the trajectory is clear: open-source models are not just catching up to proprietary systems—they are innovating in ways that push the entire field forward. DeepSeek’s reasoning approach, Gemma’s efficient attention mechanisms, Phi-4’s data-centric training philosophy, Qwen’s flexible thinking modes, Llama 4’s native multimodality, and Mistral’s efficiency-first design all represent different paths toward more capable AI.
The integration of these models into platforms like Perplexity shows another crucial trend: the rise of AI aggregators that make it easy to access and compare different models. This creates a competitive marketplace where models compete on merit rather than marketing budgets.
What’s particularly exciting is the diversity of approaches. While DeepSeek pushes the boundaries of reasoning through computational depth, Mistral proves that algorithmic efficiency can deliver similar results with far fewer resources. Llama 4’s 10-million token context window opens possibilities for processing entire codebases or document libraries, while Phi-4 shows that careful data curation can outweigh raw parameter count.
The real winners in this revolution? All of us. Competition drives innovation, transparency builds trust, and accessibility enables creativity. Whether you are a developer building the next breakthrough app, a researcher pushing the boundaries of what is possible, or a business leader looking to leverage AI responsibly, the open-source AI revolution has something to offer you.
The question is not whether open-source models will match proprietary ones—they already have in many areas. The question is: what will you build with this unprecedented access to advanced AI?
Ready to explore these models yourself? Start with the free tiers on platforms like Perplexity or OpenRouter, or dive into local deployment with smaller models like Phi-4, Mistral Small, or Gemma 3. The future of AI is open, and it is waiting for you to join in.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting