May 6, 2025
Looking to enhance your AI search capabilities? In 2025, embedding model selection is key for RAG systems and semantic search. This guide compares OpenAI, AWS, and open-source options to help you build more accurate, context-aware applications.
Text embedding models convert language into numerical representations, enabling powerful semantic search, recommendations, and RAG capabilities. Here’s how to choose the right model for your needs.

Choosing the right text embedding model is vital for NLP systems in 2025. Performance on specific tasks, technical specs, cost, and licensing are key factors to consider. While MTEB provides overall benchmarks, task-specific performance matters most for retrieval and RAG systems. OpenAI, AWS, and open-source options each offer distinct trade-offs.
Text Embedding Models in 2025: A Complete Guide to OpenAI, AWS, and Open Source Options
You have spent weeks perfecting your RAG system architecture. Your chunking strategy is elegant, your vector database is tuned, and your prompt templates are masterpieces. But when you deploy, the results are… disappointing. The system retrieves irrelevant documents, misses obvious connections, and sometimes completely misunderstands user queries.
The culprit? Your embedding model.
“Embedding models are the unsung heroes of modern NLP systems,” says a lead AI engineer at a Fortune 500 company I spoke with recently. “Everyone obsesses over which LLM to use, but the embedding layer is what makes or breaks search quality and RAG performance.”
In 2025, choosing the right embedding model has become increasingly complex.

With competing offerings from OpenAI, AWS, and a flourishing open-source ecosystem, developers face a dizzying array of options with different trade-offs. This guide will help you navigate this landscape and select the optimal model for your specific needs.
Understanding the Embedding Model Landscape
Text embedding models transform text into numerical vectors that capture semantic meaning, enabling machines to understand relationships between words, sentences, and documents. These vectors power crucial applications like:
- Semantic search: Finding documents based on meaning rather than keywords
- RAG systems: Retrieving relevant context to ground LLM outputs
- Clustering: Grouping similar content automatically
- Recommendation engines: Suggesting related items or content
- Classification: Categorizing text based on learned patterns
While all embedding models serve the same fundamental purpose, they vary dramatically in their performance across different tasks, context length limitations, dimensionality, multilingual capabilities, and computational requirements.
The Benchmark That Rules Them All: MTEB
Before diving into specific models, we need to understand how they are measured. The Massive Text Embedding Benchmark (MTEB) has emerged as the industry standard for evaluating embedding models across 8 diverse task categories:
- Classification: Assigning predefined categories to text
- Clustering: Grouping similar documents
- Retrieval: Finding relevant documents for a query
- Semantic Textual Similarity (STS): Measuring how similar two texts are
- Reranking: Sorting retrieved documents by relevance
- Summarization: Evaluating summary quality
- Pair Classification: Determining relationships between text pairs
- Bitext Mining: Identifying translated text pairs

MTEB spans 58 datasets across 112 languages, providing a comprehensive evaluation framework. The benchmark reports task-specific metrics (accuracy, v-measure, nDCG@10, Spearman correlation) and an aggregate average score that is often cited on leaderboards.
However, the MTEB average can be misleading. A model with a high overall score might perform poorly on the specific task you care about. As one researcher noted, “No single embedding method dominates across all tasks.” This is why examining sub-task scores—particularly Retrieval for RAG systems—is crucial.
Proprietary Models: Easy Integration, Cost Considerations
OpenAI Embedding Models
OpenAI offers three main embedding models, with their third-generation options released in 2024 showing significant improvements:text-embedding-ada-002(Legacy)
- Dimensions: 1536
- Max Tokens: 8192
- MTEB Average: 61.0%
- Key Advantage: Still widely used in existing systems
- Key Disadvantage: Outperformed by newer models, higher cost than v3-smalltext-embedding-3-small- Dimensions: 1536 (variable)
- Max Tokens: 8192
- MTEB Average: 62.3%
- Key Advantage: Excellent cost/performance balance at $0.00002/1k tokens
- Key Disadvantage: Lower performance than 3-largetext-embedding-3-large- Dimensions: 3072 (variable)
- Max Tokens: 8192
- MTEB Average: 64.6%
- Key Advantage: Top-tier performance, especially in retrieval and STS
- Key Disadvantage: Higher cost at $0.00013/1k tokens
The most innovative feature of OpenAI’s v3 models is theirvariable dimensionscapability. This allows developers to reduce output dimensions (e.g., from 3072 to 256) while preserving core properties, trading some performance for lower storage costs and vector database compatibility. Remarkably, a text-embedding-3-large embedding shortened to 256 dimensions still outperforms the full text-embedding-ada-002 embedding on MTEB.
AWS Bedrock Embedding Models
Amazon Bedrock serves as a gateway to both Amazon’s own Titan models and partner models like Cohere.Amazon Titan Embed Text v1(Legacy)
-
Dimensions: 1536
-
Max Tokens: 8000
-
MTEB Average: Not reported
-
Key Disadvantage: Higher cost ($0.10/1M tokens) and superseded by v2Amazon Titan Embed Text v2- Dimensions: 1024 (variable: 512, 256)
-
Max Tokens: 8192
-
MTEB Average: 60.4%
-
Key Advantage: Low cost ($0.02/1M tokens), variable dimensions, latency/throughput-optimized endpoints
-
Key Disadvantage: Lower MTEB performance than leading competitorsCohere embed-english-v3(on Bedrock)
-
Dimensions: 1024
-
Recommended Max Tokens: 512
-
MTEB Average: 64.5%
-
Key Advantage: Top-tier performance, task-specific optimization via input_type parameter
-
Key Disadvantage: Shorter recommended context length, higher cost ($0.10/1M tokens)Cohere embed-multilingual-v3(on Bedrock)
-
Dimensions: 1024
-
Recommended Max Tokens: 512
-
MTEB Average: 64.0%
-
Key Advantage: Strong multilingual capabilities across many languages
-
Key Disadvantage: Same limitations as the English version
The Cohere models offer an interesting feature: theinput_type parameter, which allows optimization for specific tasks (search_document, search_query, classification, clustering) by prepending special tokens. They also support variousembedding_types(float, int8, binary) for compression.
Open Source Models: Performance Meets Flexibility
The open-source embedding model landscape has evolved rapidly, with many models now rivaling or surpassing proprietary offerings in performance.NV-Embed-v2(NVIDIA)
-
Dimensions: 4096
-
Max Tokens: 32768
-
MTEB Average: 72.3%
-
Key Advantage: Current state-of-the-art performance, extremely long context
-
Key Disadvantage: Non-commercial license (CC BY-NC 4.0) — cannot be used in for-profit applicationse5-mistral-7b-instruct(Microsoft/intfloat)
-
Dimensions: 4096
-
Max Tokens: 4096
-
MTEB Average: 66.6%
-
Key Advantage: Strong retrieval performance, instruction tuning
-
Key Disadvantage: Requires an instruction prefix for queriesBGE-Large-en-v1.5(BAAI)
-
Dimensions: 1024
-
Max Tokens: 512
-
MTEB Average: 64.2%
-
Key Advantage: Strong overall performance, permissive MIT license
-
Key Disadvantage: Shorter context limit (512 tokens)BGE-M3(BAAI)
-
Dimensions: 1024
-
Max Tokens: 8192
-
Key Advantage: Unique multi-functionality supporting dense, sparse, and multi-vector retrieval simultaneously
-
Key Disadvantage: Requires specialized vector databases for hybrid capabilitiesGTE-Large-en-v1.5(Alibaba/thenlper)
-
Dimensions: 1024
-
Max Tokens: 8192
-
MTEB Average: 65.4%
-
Key Advantage: High overall performance with long context window
-
Key Disadvantage: Standard open-source hosting requirementsNomic-embed-text-v1.5(Nomic AI)
-
Dimensions: 768 (variable)
-
Max Tokens: 8192
-
MTEB Average: 62.3%
-
Key Advantage: Fully open (weights, code, and data), multimodal capabilities
-
Key Disadvantage: Requires task prefix, slightly lower performance than top modelsall-MiniLM-L6-v2(Sentence-Transformers)
-
Dimensions: 384
-
Max Tokens: 256
-
MTEB Average: 56.3%
-
Key Advantage: Extremely fast, lightweight (80MB)
-
Key Disadvantage: Lower performance, very short context window
The Four Critical Dimensions for Model Selection
When choosing an embedding model, consider these four key dimensions:
1. Performance on Relevant Tasks
Look beyond the average MTEB score to specific task performance:
-For RAG and search, prioritize models with high Retrieval scores: - NV-Embed-v2 (62.7%) - SFR-Embedding-Mistral (59.0%) - e5-mistral-7b-instruct (56.9%) - OpenAI 3-Large (55.4%) - Cohere English v3 (55.0%) -For semantic analysis, check STS performance: - BGE-Large-v1.5 (83.1%) - Cohere English v3 (82.6%) - OpenAI 3-Large (81.7%) -For organizational tasks, consider Clustering scores: - OpenAI 3-Large (49.0%) - Cohere English v3 (47.4%) - BGE-Large-v1.5 (46.1%)
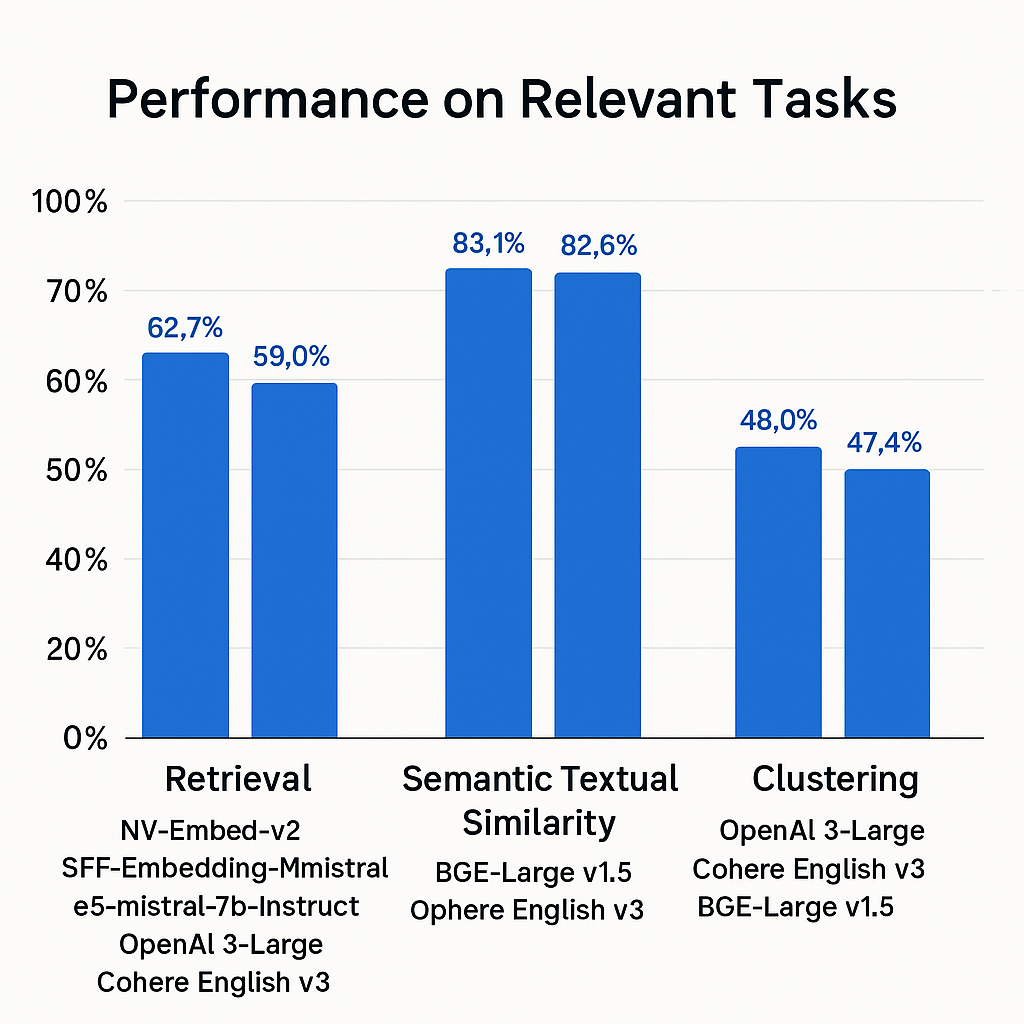
The recent emphasis on retrieval performance reflects the growing popularity of RAG architectures. Even models with similar overall MTEB scores may have dramatically different retrieval capabilities.
2. Technical Specifications
Consider these technical aspects:DimensionsHigher dimensions (1024-4096) often capture richer semantic information, while lower dimensions (384-768) reduce storage and computational requirements. Models with variable dimensions (OpenAI v3, Titan v2, Nomic v1.5) offer valuable flexibility.Context LengthThis ranges dramatically from 256 tokens (MiniLM) to 32,768 (NV-Embed). Longer context models can process entire documents, while shorter ones require effective chunking strategies. Consider your typical document length and chunking approach:
-Very long context(8k+ tokens): NV-Embed-v2, GTE, BGE-M3, OpenAI, Titan -Medium context(1-4k tokens): e5-mistral-7b-instruct -Short context(<1k tokens): Cohere v3, BGE-Large-v1.5, MiniLMMultilingual CapabilitiesFor applications requiring multilingual support, consider:
- Cohere embed-multilingual-v3 (MTEB 64.0%)
- BGE-M3 (strong MIRACL performance)
- GTE-Multilingual
- OpenAI 3-Large (MIRACL 54.9%)
3. Cost and AccessibilityAPI Models:
- Budget option: OpenAI text-embedding-3-small ($0.00002/1k tokens)
- Mid-tier: AWS Titan V2 ($0.00002/1k tokens)
- Premium: OpenAI 3-Large ($0.00013/1k tokens), Cohere v3 ($0.0001/1k tokens)Open Source Models: While eliminating direct API costs, these incur infrastructure expenses (compute resources, hosting, deployment, maintenance). More efficient models like MiniLM significantly reduce these costs compared to large models like NV-Embed or e5-mistral.Licensing: Critical for commercial applications. Check for permissive licenses like MIT (BGE) or Apache 2.0 (E5-Mistral, GTE, Nomic, MiniLM).
Some top performers like NV-Embed-v2 have non-commercial licenses (CC BY-NC 4.0), which is a significant restriction that is easy to overlook.This means the model cannot legally be used in any for-profit business context, including:
- Commercial products or services
- For-profit company internal tools
- Projects that generate revenue, directly or indirectly
- Applications where the embedding model supports a paid service
This restriction makes NV-Embed-v2 suitable only for:
- Academic research
- Personal hobby projects
- Non-profit organizations
- Educational institutions
Always carefully verify licensing terms before deployment. What appears to be the “best” model technically may be completely unusable for your business context.
4. Special Features and Requirements
Consider unique capabilities that might benefit your application:
-Variable dimensions: OpenAI v3, Titan v2, Nomic v1.5 -Task-specific optimization: Cohere v3’s input_type parameter -Embedding compression: Cohere v3’s embedding_types -Multi-modal retrieval: BGE-M3’s dense/sparse/multi-vector capabilities -Latency/throughput optimization: Titan v2’s specialized endpoints -Auditability: Nomic’s fully open approach (code, weights, data)
Matching Models to Use Cases
Based on this analysis, here are recommendations for common scenarios:
High-Performance RAG (English)
Top contenders: NV-Embed-v2 (non-commercial), SFR-Embedding-Mistral, OpenAI 3-Large, e5-mistral-7b-instruct, Cohere English v3, GTE-Large-v1.5
Decision factors:
- If cost is no object and you want API simplicity: OpenAI 3-Large
- If you need the absolute highest performance and are in astrictly non-commercial context(research, education, non-profit): NV-Embed-v2
- If you prefer open-source with commercial license: e5-mistral variants, GTE-Large-v1.5
- If you need specialized task optimization: Cohere English v3 (despite shorter context)
Cost-Sensitive RAG/Search
Top contenders: AWS Titan V2, OpenAI 3-Small, Nomic-Embed, BGE-Large-v1.5
Decision factors:
- For API simplicity with low cost: OpenAI 3-Small or Titan V2
- For open-source deployment with balanced performance: Nomic-Embed or BGE-Large-v1.5
- For extremely resource-constrained environments: all-MiniLM-L6-v2 (with chunking)
Multilingual Applications
Top contenders: Cohere embed-multilingual-v3, BGE-M3, GTE-Multilingual, OpenAI 3-Large
Decision factors:
- For API simplicity: Cohere multilingual-v3 or OpenAI 3-Large
- For open-source with long context: BGE-M3 or GTE-Multilingual
- For specific language pairs: Test performances on relevant languages
Long Document Processing
Top contenders: NV-Embed-v2, GTE-Large, BGE-M3, Nomic-Embed, OpenAI v3, Titan v2
Decision factors:
- For extremely long context: NV-Embed-v2 (32k tokens)
- For balanced performance/context: GTE, BGE-M3, Nomic-Embed, OpenAI v3 (all 8k tokens)
- Consider: Document size distribution, chunking strategy necessity
Implementation Best Practices
Regardless of which model you choose, consider these best practices:
1.Test on domain-specific data: Public benchmarks provide guidance, but performance on your specific data and tasks is what matters. Create a small evaluation set representing your use case. 2.Optimize chunking strategy: Even with long-context models, effective chunking often improves retrieval quality. Experiment with chunk size, overlap, and semantic vs. structural boundaries. 3.Consider hybrid approaches: Combining multiple embedding models (e.g., dense + sparse retrieval with BGE-M3) or multiple embedding dimensions can improve results for complex applications. 4.Evaluate regularly: As the field evolves rapidly, revisit your model choice periodically. What was state-of-the-art six months ago may now be significantly outperformed. 5.Start simple: Begin with well-supported, balanced models like OpenAI 3-Small, Nomic-Embed, or BGE-Large-v1.5 before exploring more specialized options.
The Future of Embedding Models
Several trends are shaping the future of embedding models:
1.Increasing context lengths: The race toward longer context windows continues, enabling more holistic document understanding. 2.Multimodality: Models that can embed text alongside images, code, and structured data are becoming more prevalent. 3.Task specialization: We’re seeing more models optimized specifically for retrieval, particularly for RAG applications. 4.Efficiency innovations: Variable dimensions, compression techniques, and lightweight architectures address practical deployment concerns. 5.Integration with LLMs: The line between embedding models and LLMs continues to blur, with models like e5-mistral leveraging LLM capabilities.
Conclusion: Beyond the Benchmark
The embedding model landscape in 2025 offers unprecedented choice and performance, but requires careful navigation. While MTEB provides a useful yardstick, the “best” model ultimately depends on your specific requirements, constraints, and use cases.
For production applications, the decision often involves balancing multiple factors:
- Task-specific performance (especially retrieval for RAG)
- Context length requirements
- Dimensionality considerations
- Cost structure (API vs. infrastructure)
- Licensing constraints
- Special features and integration needs
The good news? Todays embedding models are remarkably capable, with even “middle-tier” options outperforming the best models available just a year ago. By understanding your specific needs and the strengths and limitations of each option, you can select an embedding model that transforms your application from merely functional to truly exceptional.
Have you implemented any of these embedding models in your projects? What factors influenced your decision? Share your experiences in the comments below.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting