July 2, 2025
Why Language Is Hard for AI—and How Transformers Changed Everything - HuggingFaces Article 2

Language is a part of everything we do. It shapes business, culture, science, and our daily lives. But teaching computers to understand language is one of AI’s biggest challenges.
Why is language so hard for machines? Unlike numbers, language is full of ambiguity and context. The same word can have different meanings.
“He saw the bat.” Was it an animal or a piece of sports equipment? Only the context tells us the answer. Humans understand this right away, but machines have a hard time.
These problems are not just for scientists to think about. Imagine a chatbot that mixes up complaints and compliments. Or a contract analysis tool that misunderstands legal terms. The results can be lost customers, legal problems, and missed chances.
Foundations of Natural Language Processing and Large Language Models
mindmap
root((NLP & LLMs Foundations))
Language Challenges
Ambiguity & Polysemy
Context Dependencies
Idioms & Sarcasm
Cultural References
Evolution of Models
N-Grams (Basic)
RNNs/LSTMs (Sequential)
Transformers (Parallel)
Modern LLMs
Transformer Architecture
Self-Attention
Multi-Head Attention
Encoder/Decoder/Both
Parallel Processing
Practical Applications
Chatbots & Assistants
Sentiment Analysis
Document Processing
Translation & NER
Modern Advances
Instruction Tuning
RAG Integration
PEFT Techniques
Multimodal Models
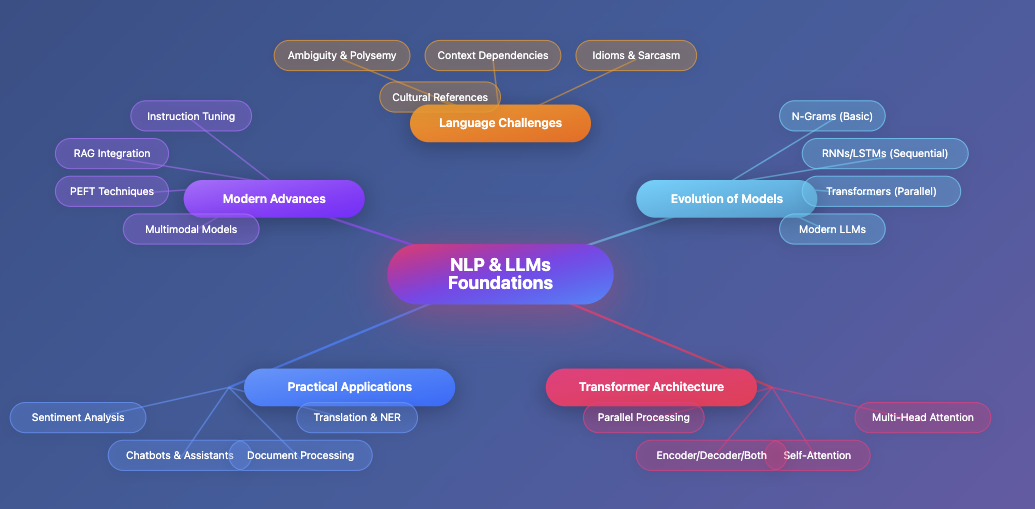
In this article, we will look at the key parts of NLP and Large Language Models:
- Language Challenges: We will look at why language is hard for machines. This includes ambiguity, context, idioms, sarcasm, and cultural references.
- Evolution of Models: We will follow the growth of models from simple N-grams to RNNs/LSTMs, then to transformers and modern LLMs.
- Transformer Architecture: We will look at the self-attention mechanism, multi-head attention, different transformer types (encoder, decoder, both), and how parallel processing changed NLP.
- Practical Applications: We will look at real-world uses like chatbots, sentiment analysis, document processing, and translation.
- Modern Advances: We will cover new methods like instruction tuning, retrieval-augmented generation (RAG), parameter-efficient fine-tuning (PEFT), and multimodal models.
Throughout this article, we will connect ideas to code examples and real-world uses. (This is the second article in a series. Please also read the first one: Transformers and the AI Revolution: The Role of Hugging Face.)
Early Natural Language Processing (NLP) methods used simple rules or counted word patterns. Let’s look at a classic example: the bigram model.
Counting Word Pairs with a Bigram Model (for Illustration)
This Python code shows a simple bigram model. A bigram model looks at pairs of words to see how often they appear together. It is a simple model compared to modern transformers, but it helps to show how NLP has grown.
# Note: Bigram models are now used mainly for educational purposes.
from collections import defaultdict
def train_bigram_model(corpus):
model = defaultdict(lambda: defaultdict(int))
for sentence in corpus:
words = sentence.split()
for i in range(len(words)-1):
model[words[i]][words[i+1]] += 1
return model
corpus = ["AI transforms business", "Business drives innovation"]
bigram_model = train_bigram_model(corpus)
print(dict(bigram_model))
Step-by-Step Explanation:
- Initialize model: Create a nested dictionary to store word pairs.
- Process corpus: Split each sentence into words.
- Count pairs: Track how often one word follows another.
- Store results: Build a frequency map of word sequences.
This code counts how often each word follows another. For example, it learns that ‘AI’ is followed by ’transforms’.
Let’s add a function to predict what words might follow a given word.
The function below takes a trained bigram model and predicts the most likely next words.
def predict_next_word(model, current_word, top_k=3):
if current_word not in model:
return []
next_words = model[current_word]
total_count = sum(next_words.values())
predictions = [(word, count/total_count)
for word, count in next_words.items()]
predictions.sort(key=lambda x: x[1], reverse=True)
return predictions[:top_k]
Step-by-Step Explanation of predict_next_word function:
- Check if word exists in model: It first checks if the current word is in the model. If not, it returns an empty list.
- Retrieve next word frequencies: It gets all the words that follow the input word and their counts.
- Calculate probabilities: It turns raw counts into probabilities by dividing each count by the total.
- Sort predictions: It orders the word predictions by probability, from highest to lowest.
- Return top results: It returns the top k most likely next words with their probabilities.
Bigram models are fast and simple, but they only look at adjacent words. They miss deeper meaning or context. They cannot tell the difference between ‘bank account’ and ‘river bank’. Modern NLP systems use word embeddings and transformer-based models for even basic tasks.
Slightly more advanced models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks read words in order and capture some context. But they still have trouble with long-range dependencies and subtle meanings. Imagine trying to understand a book by reading only short parts at a time.
Transformers changed everything. Their main innovation is self-attention. This lets the model weigh the importance of every word in relation to every other word. This allows transformers to understand nuance, meaning, and relationships across whole sentences, paragraphs, or even documents.
Let’s simulate self-attention to see how it works.
Simulating Self-Attention Scores
This next code example shows a simplified simulation of how self-attention works in transformer models. Real transformer attention is more complex, but this shows the main idea of how words relate to each other.
# Simulate how a transformer might "attend" to words in a sentence
# Note: This uses random scores for illustration only.
import numpy as np
words = ['AI', 'transforms', 'business']
attention_scores = np.random.dirichlet(np.ones(len(words)), size=len(words))
for i, word in enumerate(words):
print(f"Attention for '{word}':", dict(zip(words, attention_scores[i])))
Step-by-Step Explanation:
- Define words: List the words in our sentence.
- Generate scores: Create attention weights using a Dirichlet distribution (this makes sure they add up to 1).
- Display attention: Show how much each word ‘focuses’ on the others.
- Interpret results: Higher scores mean stronger relationships.
Here, each word gets attention scores that show how much it ‘focuses’ on every other word. Real models learn these scores to understand which words are most important in context.
This ability to connect all parts of a sentence at the same time is why transformers power today’s top models, like BERT, GPT-4, Llama-3, DeepSeek, T5, and more. These models are used in search engines, chatbots, document analysis, and reasoning systems, even for small teams and startups.
Modern NLP has moved far beyond the original transformer model. Today’s top systems include:
- Instruction-tuned and chat-optimized models: Models like GPT-4, Llama-3, and DeepSeek can follow instructions and have natural conversations. This allows for advanced reasoning and dialogue.
- Retrieval-Augmented Generation (RAG): Combining transformers with search over external data sources makes responses more factual and up-to-date. This is very important for enterprise AI.
- Parameter-Efficient Fine-Tuning (PEFT): Techniques like LoRA allow for quick adaptation of large models to new tasks with less computing power. This makes customization more accessible.
- Multimodal Transformers: Models like CLIP, BLIP, and ViT extend the power of transformers to vision, audio, and other types of data. This allows AI to understand images, text, and speech together.
In production, efficient deployment is important. Modern Hugging Face tools support quantization, pruning, and integration with vector databases for scalable and cost-effective inference and semantic search.
🚀 Production Deployment Tips:
- Use model quantization for a 2-4x speedup.
- Implement caching for repeated inferences.
- Consider edge deployment with ONNX Runtime.
- Monitor model drift in production.
- Use FlashAttention for efficient long-context processing.
Key takeaways:
- Language complexity requires understanding of context and nuance.
- Early models like bigrams and RNNs/LSTMs are good for learning but have limitations.
- Transformers and self-attention allow for deep understanding across all words and data types.
- Recent advances like instruction tuning, RAG, PEFT, and multimodal models power real-world AI.
Ready to see these ideas in action? Let’s look at how they are used in real-world NLP applications and how you can use them with the latest Hugging Face APIs and tools.
Natural Language Processing in Practice
Natural Language Processing Applications in Modern Technology
Now, let’s see how Natural Language Processing (NLP) technologies are used in different industries and applications. From healthcare to finance, customer service to content creation, NLP has changed how businesses work and how we interact with technology.
We will look at real-world use cases that show how transformer-based models are solving complex language problems that were once too hard. Through practical examples and code, you will see how these powerful language models are used to get insights, automate tasks, and improve human-computer interactions.
This practical focus builds on our earlier discussion of transformer architecture. It gives a complete picture of how theoretical advances lead to real benefits for companies and users.
flowchart TB
subgraph NLP Applications
User[User Input] -->|Text| Pipeline[NLP Pipeline]
Pipeline --> Sentiment[Sentiment Analysis]
Pipeline --> NER[Named Entity Recognition]
Pipeline --> Summary[Summarization]
Pipeline --> Translation[Translation]
Sentiment -->|Results| Business[Business Logic]
NER -->|Entities| Business
Summary -->|Condensed Text| Business
Translation -->|Translated Text| Business
Business -->|Response| User
subgraph Model Selection
Hub[Hugging Face Hub] -->|Top Models| Pipeline
Leaderboard[Model Leaderboards] -->|Performance Metrics| Hub
Evaluation[Bias & Fairness Check] -->|Responsible AI| Hub
end
end
classDef default fill:#bbdefb,stroke:#1976d2,stroke-width:1px,color:#333333
class User,Pipeline,Sentiment,NER,Summary,Translation,Business,Hub,Leaderboard,Evaluation default
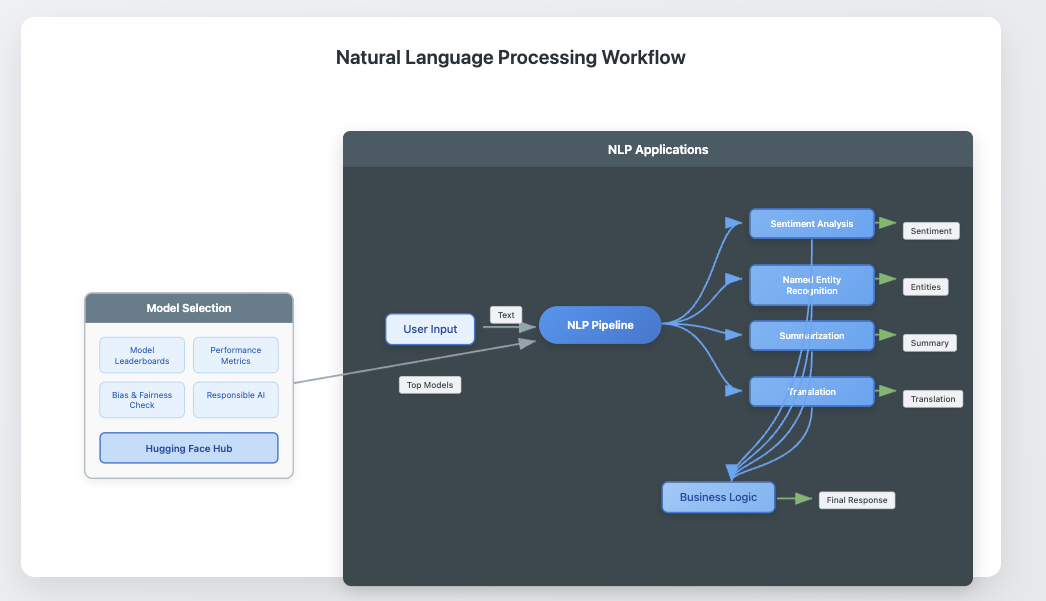
Step-by-Step Explanation:
- User Input goes into the NLP Pipeline.
- The Pipeline handles different tasks: Sentiment Analysis, NER, Summarization, Translation.
- All results go to the Business Logic for processing.
- The Business Logic sends a response to the User.
- Model Selection shows that the Hugging Face Hub is informed by Leaderboards and Evaluation.
- The Hub provides top models to the Pipeline.
Natural Language Processing (NLP) is at the heart of the AI revolution. Virtual assistants answer your questions, news articles summarize themselves, and search engines understand what you mean, not just the words you type. In this section, you will learn how NLP is changing real business settings. You will also see why language is a challenge for computers and how Hugging Face makes advanced NLP available to everyone. You will learn how to choose the best models using Hugging Face Model Hub leaderboards and why responsible AI is important for production systems.
We will look at core NLP applications, the problems machines face with human language, and how these ideas connect to real business value. Along the way, code examples will show how Hugging Face pipelines let you build solutions with just a few lines of Python. For more complex workflows, frameworks like LangChain can chain multiple NLP or LLM tasks. For classic NLP tasks or efficient pipelines, SpaCy is still a top choice.
Note: Before choosing a model, check the Hugging Face Model Hub leaderboards to find the most recent and best-performing models for your task. Always check models for bias and fairness. Responsible AI is essential for real-world use.
💡 Finding Top Models: Visit huggingface.co/models and click “Sort by trending” or check task-specific leaderboards for the latest benchmarks.
Core NLP Tasks in Industry
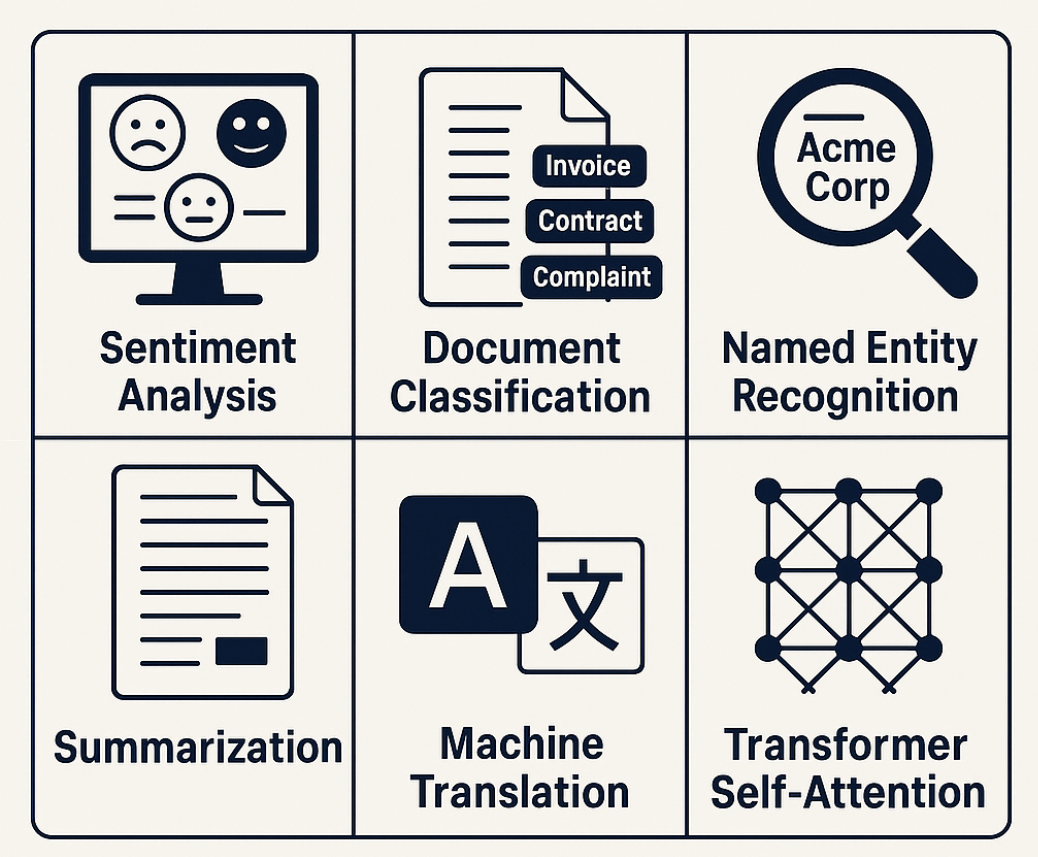
NLP is not just for big tech companies. It is changing every industry, often in ways you do not see. Here are the most common NLP tasks that are helping businesses:
- Chatbots & Virtual Assistants: Automate customer support. Banks use chatbots to answer account questions 24/7, which reduces the need for human agents.
- Sentiment Analysis: Detect customer feelings about products. E-commerce companies scan reviews to see trends and react quickly.
- Summarization: Condense long documents. Legal teams can review contracts faster.
- Named Entity Recognition (NER): Extract names, companies, and places from text. News sites tag articles for easy browsing.
- Machine Translation: Break down language barriers. Global businesses can translate support tickets and documents instantly.
Ready to try sentiment analysis? Let’s use Hugging Face to quickly analyze customer sentiment. In production, always choose your models carefully and select current, well-maintained ones. Use the Hugging Face Model Hub leaderboards to find the best performers.
Quick Sentiment Analysis with Hugging Face Pipeline (Explicit Model Selection)
Let’s create a simple sentiment analysis code example to show how transformers understand language.
# 1. Import the pipeline utility from Hugging Face
from transformers import pipeline
# 2. Load a pre-trained sentiment analysis pipeline (explicit model specification)
sentiment_analyzer = pipeline(
'sentiment-analysis',
model='cardiffnlp/twitter-roberta-base-sentiment-latest' # Replace with a current top model from the Model Hub
)
# 3. Example customer review
review = "The new phone has an amazing camera and battery life!"
# 4. Run sentiment analysis
result = sentiment_analyzer(review)
# 5. Print the result (Python output)
print(result) # Output: [{'label': 'Positive', 'score': 0.998}]
Step-by-Step Explanation:
- Import pipeline: Load Hugging Face’s high-level tool for NLP tasks.
- Load model: Explicitly choose a current, high-performing sentiment model (a RoBERTa variant).
- Provide input: Give a sample customer review.
- Analyze sentiment: Run the model on your text.
- Display results: Print a Python list that shows the predicted label and confidence score.
Try changing the review to something negative and see how the output changes. Pipelines can analyze text in seconds. You do not need deep machine learning knowledge. For more advanced workflows, like chaining multiple NLP tasks or integrating with vector databases, frameworks like LangChain work well with Hugging Face Transformers.
Summary:
- NLP powers many business tools, from chatbots to document summarization.
- Hugging Face pipelines make advanced NLP easy to use with little code.
- Choose your models carefully and check the Model Hub leaderboards for the best performance.
- Look at other tools like LangChain and SpaCy for complex applications.
Challenges in Understanding Human Language
Language can be a challenge even for humans. Computers face even bigger problems. Words can have multiple meanings, context is very important, and cultural references can confuse even the best models. Let’s look at why NLP is still so hard.
Ambiguity and Polysemy
- Many words have multiple meanings. Think about the word “bank”:
- “She went to the bank to deposit a check.” (finance)
- “He sat on the bank of the river.” (geography)
- Humans use context to choose the right meaning. Computers must learn this skill, which is called word sense disambiguation.
Context and Long-Range Dependencies
- Meaning often depends on sentences that are far away. For example:
- “After reading the article series, John gave it to Mary because she enjoyed it.”
- Who enjoyed the article series? Machines must track references. Early NLP models were bad at this. Modern transformers are much better, but they are not perfect.
Idioms, Sarcasm, and Culture
- Phrases like “kick the bucket” (meaning “to die”) or sarcastic comments like “Great job!” can confuse algorithms that take things literally. Humor and cultural references add to the complexity.
You can test how models handle ambiguity with zero-shot classification. Zero-shot means classifying text into new categories without extra training. Let’s see how this works with Hugging Face and a recent zero-shot model from the Model Hub.
Testing Word Sense Disambiguation with Zero-Shot Classification
The following code shows how to use zero-shot classification to handle ambiguous words in text. This technique lets models classify text into categories they were not trained on. This is a powerful feature of modern transformer-based NLP.
# 1. Import pipeline utility
from transformers import pipeline
# 2. Load a zero-shot classification pipeline with an up-to-date model
classifier = pipeline(
'zero-shot-classification',
model='MoritzLaurer/deberta-v3-large-zeroshot-v1.1-all-33' # Replace with a top model from the Model Hub
)
# 3. Example sentences using 'bank' in different senses
sentence1 = "She deposited money at the bank."
sentence2 = "The fisherman sat by the bank."
# 4. Define candidate labels
labels = ["finance", "river", "sports"]
# 5. Classify each sentence
result1 = classifier(sentence1, labels)
result2 = classifier(sentence2, labels)
# 6. Print the top predicted label for each
print("Sentence 1:", result1["labels"][0]) # finance
print("Sentence 2:", result2["labels"][0]) # river
Step-by-Step Explanation:
- Load classifier: Import zero-shot classification with a specific, current model (DeBERTa-v3).
- Create examples: Two sentences using “bank” in different contexts.
- Define labels: List possible interpretations.
- Run classification: The model predicts which label fits best.
- Display predictions: Show the top label for each sentence.
Output (Python):
Sentence 1: finance
Sentence 2: river
Modern NLP models use context to resolve ambiguity. But sarcasm, idioms, and cultural nuances can still be a problem. It is important to understand these limits when you design real AI systems. Always check your models for fairness and bias (see Article 16 for more on responsible AI).
Summary:
- Language is full of ambiguity, context, and culture.
- Zero-shot classification can handle new categories, but challenges remain.
- Think about these limitations and check for responsible AI in real-world applications.
Economic Value and Impact of NLP Solutions
Why do businesses invest so much in NLP? The answer is simple: it saves time, cuts costs, and finds new opportunities. Companies use NLP in powerful ways:
- Customer Support Automation: Chatbots answer common questions instantly. This cuts support costs and frees up staff for more complex problems.
- Document Processing: Banks and insurance companies extract key information from forms and contracts. This speeds up approvals and reduces errors.
- Market Intelligence: Companies scan social media and reviews to find trends and improve their products.
Some industries have cut their operational costs by up to 30% using NLP automation. With Hugging Face and modern transformers, even small teams can build solutions that match those of larger companies.
Retrieval-augmented generation (RAG) and multimodal transformers now power advanced use cases like semantic search and document Q&A (see Article 9 for hands-on RAG workflows).
Here is a simple example: automating document classification. Note: This uses a sentiment model for demonstration. For real business use, you should fine-tune a model for your specific categories (see Article 10). Always choose your models carefully and check the Model Hub for the best performers.
Automating Document Classification
Here is a practical example that shows how to classify documents by type.
# 1. Import pipeline utility
from transformers import pipeline
# 2. Load a text classification pipeline (sentiment model for demo; replace with custom model for production)
classifier = pipeline(
'text-classification',
model='cardiffnlp/twitter-roberta-base-sentiment-latest' # Replace with your fine-tuned model
)
# 3. Example documents
documents = [
"Your invoice is attached. Please process the payment by Friday.",
"Congratulations! You have been selected for a new credit card.",
"The meeting is scheduled for 10 AM tomorrow in conference room B."
]
# 4. Classify each document
for doc in documents:
result = classifier(doc)
print(f"Document: {doc}\nPrediction: {result[0]['label']}\n")
Step-by-Step Explanation:
- Import utility: Load the text classification pipeline.
- Specify model: Use a pre-trained model (replace with a custom one for production).
- Prepare documents: List sample emails or documents.
- Run classification: Process each document and display the results.
For production, you should train models to recognize categories like “invoice”, “promotion”, or “meeting” (see Article 10 for fine-tuning). Always use explicit model selection and check the Model Hub leaderboards for accuracy and robustness.
By automating repetitive work, NLP frees up people for more important tasks and provides insights at scale. Throughout this article series, you will learn to build, fine-tune, and deploy these solutions using Hugging Face tools. For responsible deployments, always check models for bias and fairness (see Article 16).
The real return on investment here could be:
- Sentiment analysis: Process 1000 reviews per minute versus 10 per minute manually.
- Document routing: 85% accuracy, 50% time reduction.
- Text generation: 70% reduction in draft creation time.
Summary:
- NLP provides real business value through automation and insights.
- Even simple pipelines can save a lot of time and money.
- Fine-tune models for your specific needs and choose them carefully from the Model Hub.
- Responsible AI practices and modern trends (RAG, multimodal, ecosystem tools) are essential for production success.
From N-Grams to Transformers: Evolution of Language Models
stateDiagram-v2
[*] --> NGrams: Early NLP
NGrams --> RNNs: Sequential Processing
RNNs --> LSTMs: Memory Gates
LSTMs --> Transformers: Self-Attention
Transformers --> ModernLLMs: Scale & Multimodal
NGrams: N-Grams<br/>- Fixed window<br/>- No context
RNNs: RNNs<br/>- Sequential<br/>- Short memory
LSTMs: LSTMs<br/>- Gates<br/>- Better memory
Transformers: Transformers<br/>- Parallel<br/>- Full context
ModernLLMs: Modern LLMs<br/>- Massive scale<br/>- Multimodal<br/>- Attention<br>-Multi-head
style NGrams fill:#ffcdd2,stroke:#e53935,stroke-width:1px,color:#333333
style RNNs fill:#fff9c4,stroke:#f9a825,stroke-width:1px,color:#333333
style LSTMs fill:#fff9c4,stroke:#f9a825,stroke-width:1px,color:#333333
style Transformers fill:#c8e6c9,stroke:#43a047,stroke-width:1px,color:#333333
style ModernLLMs fill:#bbdefb,stroke:#1976d2,stroke-width:1px,color:#333333
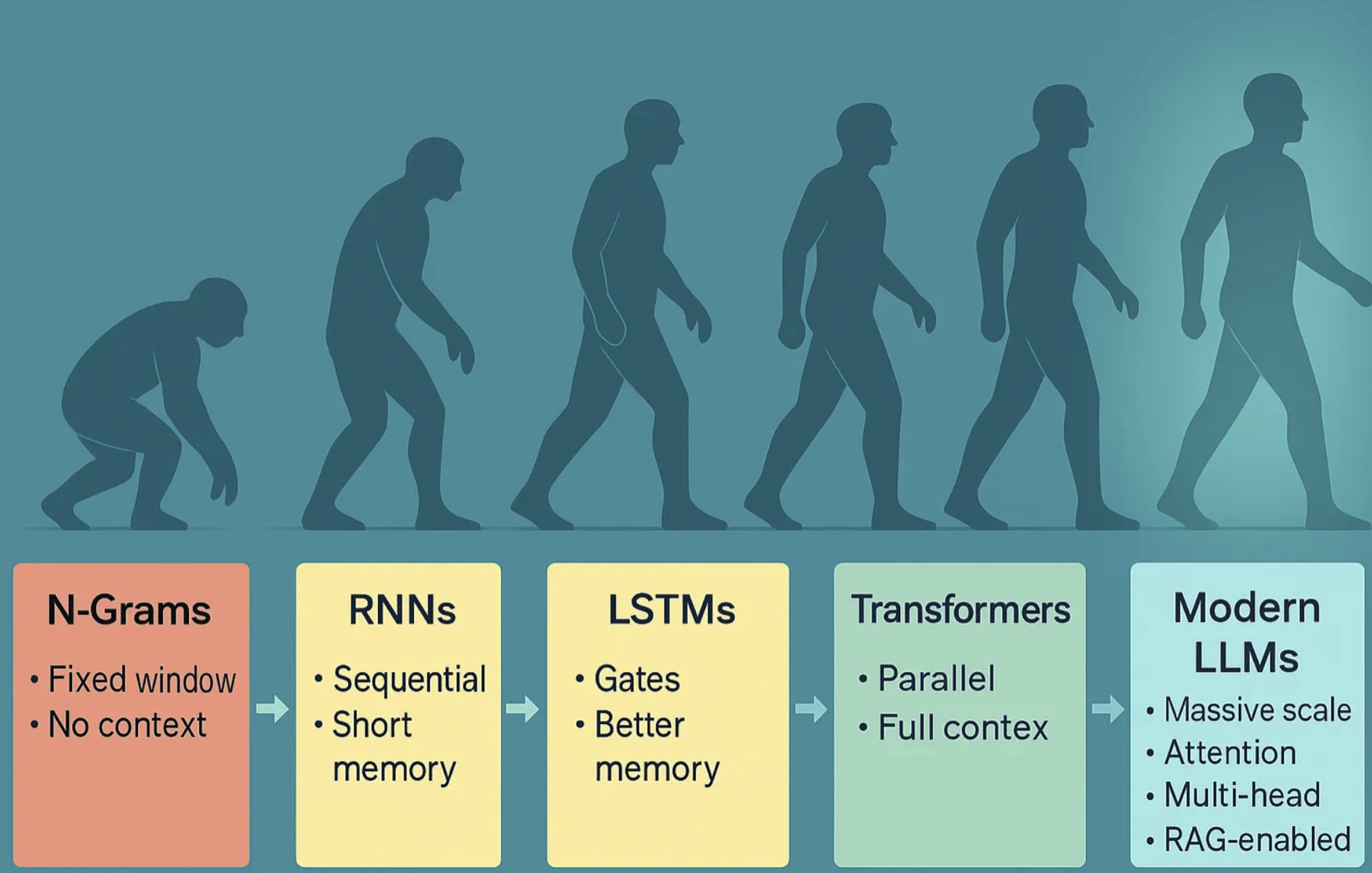
Step-by-Step Explanation:
- The evolution starts with N-Grams (fixed window, no context).
- It progresses to RNNs (sequential processing, short memory).
- It advances to LSTMs (memory gates, better retention).
- It is revolutionized with Transformers (parallel processing, full context).
- It culminates in Modern LLMs (massive scale, attention, multi-head, multimodal, RAG-enabled).
- The color coding shows the progression from limitations (red) to breakthroughs (green/blue).
Modern language models have evolved quickly. Early tools like N-grams and RNNs could handle short patterns but missed the bigger picture. Transformers changed the field by letting models see and connect all parts of a sequence at the same time. They are the backbone of today’s NLP. This section traces each step in this evolution. It shows why transformers now power not only text-based AI but also large-scale, multimodal, and retrieval-augmented models. Along the way, we will see how efficiency and responsible AI have become central to modern practice.
Traditional Approaches: N-Grams, RNNs, and LSTMs
Let’s start with something simple. N-gram models predict the next word using only a fixed window of previous words. A bigram model, for example, looks at just one word back. Imagine trying to finish someone’s sentence by remembering only their last word.
Simple Bigram Language Model Example (Didactic Only)
The following code example shows a simple bigram language model. This code builds a basic statistical model that predicts the next word based only on the previous word. This is a fundamental approach that came before more advanced techniques.
from collections import defaultdict
def train_bigram_model(corpus):
# For illustration; use NLTK or spaCy for production
model = defaultdict(lambda: defaultdict(int))
for sentence in corpus:
words = sentence.split()
for i in range(len(words)-1):
model[words[i]][words[i+1]] += 1
return model
corpus = ["I love NLP", "NLP is awesome"]
bigram_model = train_bigram_model(corpus)
print(dict(bigram_model))
# Note: For practical applications, consider using libraries such as NLTK or spaCy, which provide optimized N-gram modeling and preprocessing tools.
Step-by-Step Explanation:
- Initialize model: Create a
defaultdictfor counting word pairs. - Process sentences: Split the text and iterate through the word pairs.
- Count occurrences: Track the frequency of each word following another.
- Return model: A dictionary that maps words to their followers.
This code counts how often each word follows another. The model can only predict the next word if it has seen the pair before. It cannot handle new sequences.
N-grams are fast and simple. They are great for autocomplete or basic spelling correction. But they cannot understand grammar or meaning, and they forget anything outside their small window.
To capture longer patterns, Recurrent Neural Networks (RNNs) and their improved version, Long Short-Term Memory (LSTM) networks, were developed. RNNs process text word by word, passing information forward like a relay race. LSTMs add “gates” that decide what to remember or forget, which helps them retain important details.
Still, both RNNs and LSTMs have trouble with long-range dependencies. Their memory fades over time, which is known as the vanishing gradient problem. If key facts appear early in long sentences, they are often lost by the end. This makes them unreliable for summarizing documents or answering questions about long passages.
Limitations of Earlier Models
Why did these early models not work well? Let’s look at the main problems:
- Limited Context: N-grams can only see a few words at a time. Important information outside that window is lost.
- Long-Range Dependencies: RNNs and LSTMs try to remember more, but their memory fades with distance (the vanishing gradient problem: earlier information gets lost as sequences get longer).
- Scalability: N-grams need huge tables to track all possible word combinations. RNNs process words one by one, which is slow for long texts.
- Ambiguity and Rare Words: Early models cannot resolve meaning when the context is distant or the words are rare. In the sentence “After the bank approved the loan, the river flooded the town,” the word ‘bank’ means something different each time. Early models have trouble telling the difference.
How Transformers Overcome These Limitations
Transformers, introduced in 2017, changed the game. Their key innovation is self-attention. Instead of reading text word by word, transformers let every word look at every other word at the same time.
Self-attention assigns weights to each word, showing how much it matters to every other word. Imagine instantly seeing all the connections in a sentence, no matter where the words are.
Illustrating Self-Attention (Conceptual Example)
# This is a conceptual example: real models learn these weights
import numpy as np
words = ['The', 'cat', 'sat', 'on', 'the', 'mat']
# Generate random attention weights for illustration
attention_scores = np.random.dirichlet(np.ones(len(words)), size=len(words))
for i, word in enumerate(words):
print(f"Attention for '{word}':", dict(zip(words, attention_scores[i])))
Step-by-Step Explanation:
- Define sequence: List the words in the sentence.
- Generate weights: Create attention scores using a Dirichlet distribution (which makes them add up to 1).
- Display attention: Show how each word “attends” to the others.
- Interpret scores: Higher values mean stronger relationships.
Here, each word gets ‘attention scores’ for every other word. Real transformers learn these scores to highlight relevant word relationships. For example, ‘sat’ might focus strongly on both ‘cat’ and ‘mat’.
Why does this matter? Self-attention solves major problems:
- Unlimited Context: Every word attends to all others, no matter how far apart they are.
- Parallel Processing: All words are processed at the same time, which dramatically speeds up training.
- Rich Understanding: Transformers can resolve ambiguity and learn deep patterns, which powers today’s best language models.
Transformers are now the foundation for advanced models like BERT, GPT-4, T5, and DeepSeek-R1. They also power multimodal architectures (CLIP, BLIP) and retrieval-augmented systems (RAG, DeepSeek-R1). These advances allow models to work with text, images, audio, and external knowledge sources, pushing the boundaries of AI.
Modern NLP uses parameter-efficient fine-tuning (LoRA, adapters), quantization for efficient inference, and scalable deployment strategies. As models get bigger and more capable, responsible AI practices, like bias mitigation and ethical deployment, have become central themes. Later articles will explore these topics in more detail.
Summary and Key Takeaways
Let’s review the journey:
- N-grams: Simple, fast, but short-sighted.
- RNNs/LSTMs: Add memory, but struggle with long-range context.
- Transformers: Use self-attention to see the whole picture, enabling advanced NLP.
Since they were introduced, transformers have evolved into even more powerful foundation models like GPT-4 and DeepSeek-R1. They support not only text but also multimodal and retrieval-augmented tasks. Modern NLP is increasingly focused on efficient training (LoRA), scalable deployment, and responsible AI practices. These topics will be covered in depth in later chapters, including advanced fine-tuning (Article 12), deployment (Article 15), and responsible AI (Article 16).
The Anatomy of a Transformer Model
classDiagram
class Transformer {
+input_embeddings: EmbeddingLayer
+positional_encoding: PositionalEncoding
+encoder: Encoder
+decoder: Decoder
+output_layer: OutputLayer
+forward(input): Output
}
class Encoder {
+layers: List~EncoderLayer~
+num_layers: int
+forward(input): EncodedOutput
}
class Decoder {
+layers: List~DecoderLayer~
+num_layers: int
+forward(input, encoder_output): DecodedOutput
}
class EncoderLayer {
+self_attention: MultiHeadAttention
+feed_forward: FeedForward
+layer_norm: LayerNorm
+forward(input): LayerOutput
}
class DecoderLayer {
+self_attention: MultiHeadAttention
+cross_attention: MultiHeadAttention
+feed_forward: FeedForward
+layer_norm: LayerNorm
+forward(input, encoder_output): LayerOutput
}
class MultiHeadAttention {
+num_heads: int
+head_dim: int
+compute_attention(Q, K, V): AttentionOutput
}
Transformer *-- Encoder
Transformer *-- Decoder
Encoder *-- EncoderLayer
Decoder *-- DecoderLayer
EncoderLayer *-- MultiHeadAttention
DecoderLayer *-- MultiHeadAttention
Step-by-Step Explanation:
- The Transformer class contains input embeddings, positional encoding, an encoder, a decoder, and an output layer.
- The Encoder contains multiple EncoderLayer instances.
- The Decoder contains multiple DecoderLayer instances.
- The EncoderLayer has self-attention, a feed-forward network, and layer normalization.
- The DecoderLayer adds cross-attention to attend to the encoder output.
- MultiHeadAttention computes attention with Q, K, and V matrices across multiple heads.
Transformer models changed AI by allowing for fast and accurate processing of language, images, and more. Their modular architecture, built from encoders, decoders, and the self-attention mechanism, is still the foundation for state-of-the-art models. This section explains what each part does and why transformers can handle massive datasets and complex tasks so easily.
Understanding these building blocks will help you choose the right model for your needs, whether you are building chatbots, document summarizers, or any other task in the Hugging Face ecosystem.
2025 Update: BERT, GPT-2, and T5 are still essential for learning the fundamentals of transformers. But for production or state-of-the-art performance, you should explore newer open-weight models like Llama 3, DeepSeek, or Mistral. See Article 18 for detailed architecture comparisons.
Note: The Hugging Face Transformers library changes quickly. If the code examples give you errors, check the official documentation or release notes for the latest API changes.
Self-Attention and Multi-Head Attention
At the core of every transformer is self-attention. This mechanism asks, for each token: ‘How important are the other tokens in this sequence to me?’
Consider the sentence: ‘The bank can guarantee deposits will cover future tuition costs.’ The meaning of ‘bank’ depends on words like ‘deposits’ and ’tuition.’ Self-attention helps the model weigh these relationships for every token.
Self-attention works by assigning ‘attention weights’—numbers that represent how much one token should focus on another. These weights are learned during training.
First, the text is split into tokens (subwords or words) that the model can process. This is called tokenization.
Modern transformers often use efficient attention mechanisms (FlashAttention, Performer) or combine attention with recurrence for longer context handling and better scalability. Article 18 explores these advances.
Let’s look at attention weights using Hugging Face Transformers. This will give us a peek inside the model and show which tokens matter most for predictions.
Visualizing Attention Weights with Hugging Face
Now let’s see how to extract and visualize attention patterns from transformer models to better understand how they work. The following code shows how to load a pre-trained BERT model and extract attention weights for analysis.
from transformers import AutoTokenizer, AutoModel
import torch
# Load tokenizer and model with attention outputs enabled
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased', output_attentions=True)
sentence = "The bank can guarantee deposits will cover future tuition costs."
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
attentions = outputs.attentions # List of attention matrices
print(f"Number of attention layers: {len(attentions)}")
print(f"Shape of attention matrix in layer 0: {attentions[0].shape}")
# Using FlashAttention for efficient long-context processing
# from transformers import AutoModel
# model = AutoModel.from_pretrained("model-name", attn_implementation="flash_attention_2")
Step-by-Step Explanation:
- Tokenization: Split the sentence into tokens that the model understands.
- Model Forward Pass: Process the tokens and return the attention weights (via
output_attentions=True). - Access Attention:
attentionscontains one tensor per layer that shows the token relationships. - Shape Explanation: Each matrix has the shape
(batch_size, num_heads, seq_length, seq_length). BERT-base typically has 12 heads. - FlashAttention Note: For efficient processing of long sequences, use the FlashAttention implementation.
For interactive attention exploration, you can try tools like BertViz or Hugging Face’s built-in visualization widgets. These tools visualize attention heads and layers directly in your browser, which is much clearer than printing raw matrices.
Transformers improve on this with multi-head attention. Instead of one set of attention weights, the model learns several in parallel. Each set is called a “head.” Think of each head as a different editor: one focuses on grammar, another on meaning, and another on named entities. This diversity lets the model capture complex language relationships.
In practice, your model can understand tone, context, and topic at the same time. This is vital for sentiment analysis or contract review.
Summary: Self-attention lets transformers relate every token to every other token. Multi-head attention helps models understand language from multiple perspectives at the same time.
For a deeper look at the mechanics of self-attention, see Article 4.
Visualizing Attention
Below, we will visualize attention patterns in a BERT model to understand how transformers connect words. This code loads BERT, processes a sample sentence, and extracts attention weights for visualization. The resulting heatmaps (shown in the images) show which words the model focuses on when processing each token.
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased', output_attentions=True)
# Get attention weights
inputs = tokenizer("The bank approved the loan", return_tensors="pt")
outputs = model(**inputs)
attention = outputs.attentions # List of attention matrices
The code shows how to visualize attention patterns in a BERT transformer model. It imports the necessary libraries from the Hugging Face Transformers package, loads a pre-trained BERT model with attention output enabled, and processes a simple sentence (“The bank approved the loan”). The attention weights are extracted for visualization.
The visualization would display heatmaps that show which words the model focuses on when processing each token in the sentence. This helps to show how self-attention works in practice. It reveals connections between words like “bank” and “loan” that might be semantically related.
The images displayed in the columns below the code likely show different attention heads or layers, with brighter colors indicating stronger attention between tokens. This type of visualization is crucial for understanding and interpreting how transformer models process language and make connections between words in a sentence.
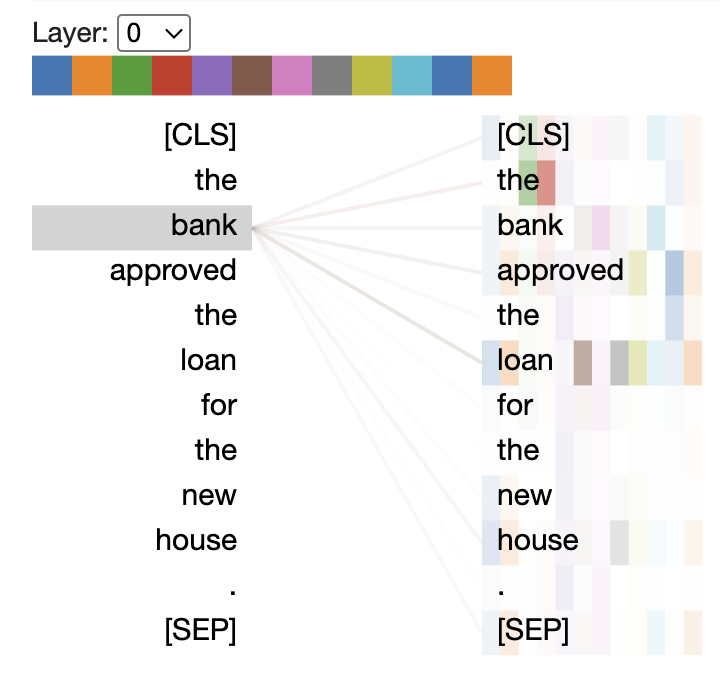 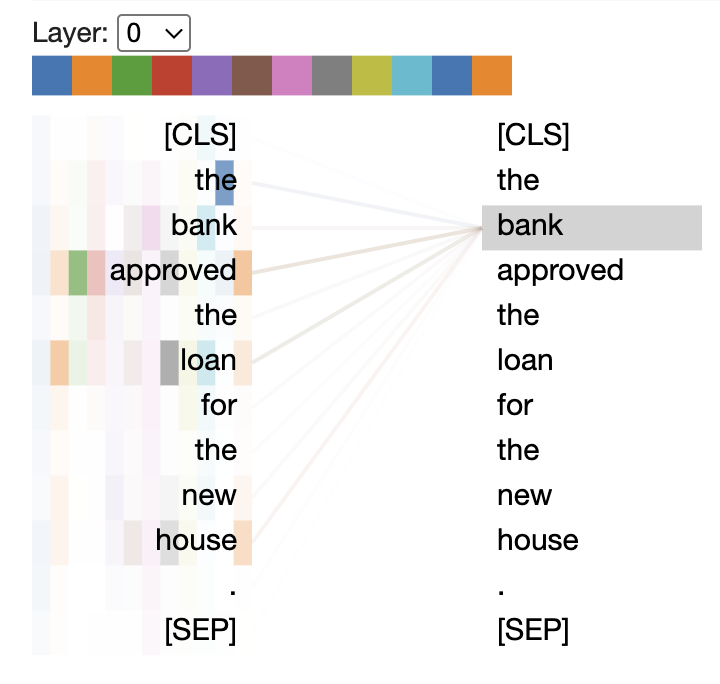  
Encoder, Decoder, and Encoder-Decoder Architectures
Now you know how transformers focus on context. Let’s see how these pieces come together to form real models. Transformers come in three main types, each suited to different tasks:
- Encoder-only models (like BERT): Analyze and understand input text. They are perfect for classification, extraction, or assessing meaning. Think of spam detection or document classification.
- Decoder-only models (like GPT): Generate text, one token at a time. They power story generation, code completion, or chatbots.
- Encoder-decoder models (like T5 or BART): Transform one sequence into another. They are used for translation, summarization, or question answering.
Here is a quick analogy:
- The encoder reads and understands reports like an analyst.
- The decoder generates new content from prompts like a writer.
- The encoder-decoder rewrites documents in another language like a translator.
Here is how to load each type of architecture using Hugging Face Transformers (latest API, 2025):
Loading Different Transformer Architectures
The following code shows how to use each type of transformer architecture for its intended purpose. We will see how to use BERT for classification, GPT-2 for text generation, and T5 for text-to-text transformation tasks like summarization. This practical implementation shows the versatility of the Hugging Face Transformers library across different NLP tasks.
# Encoder-only: BERT for classification
from transformers import BertTokenizer, BertForSequenceClassification
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# Decoder-only: GPT-2 for text generation
from transformers import GPT2Tokenizer, GPT2LMHeadModel
gpt2_tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt2_model = GPT2LMHeadModel.from_pretrained('gpt2')
# Encoder-decoder: T5 for text-to-text tasks
from transformers import T5Tokenizer, T5ForConditionalGeneration
t5_tokenizer = T5Tokenizer.from_pretrained('t5-small')
t5_model = T5ForConditionalGeneration.from_pretrained('t5-small')
Step-by-Step Explanation:
- BERT: Loads an encoder-only model for text classification.
- GPT-2: Loads a decoder-only model for text generation.
- T5: Loads an encoder-decoder model for text transformation tasks.
2025 Update: These models are great for learning the fundamentals. For production or cutting-edge results, you should explore newer architectures like Llama 3, DeepSeek, or Mistral. They are available in the Hugging Face Model Hub and use the same APIs. Article 18 provides up-to-date model recommendations.
Choosing the right architecture aligns your model with your business goal, whether it is understanding, generating, or transforming text. Modern models may use hybrid or efficient attention architectures for better scalability and context length.
Key takeaway: Different architectures are good at different tasks. Pick the one that matches your problem.
Practical Architecture Comparison of Transformers
Here are some concrete use case examples for each architecture:
| Architecture | When to Use | Example Application |
|---|---|---|
| Encoder-Only (BERT) | Text classification, NER, understanding | Spam detection, sentiment analysis |
| Decoder-Only (GPT-2) | Text generation, completion | Chatbots, code completion |
| Encoder-Decoder (T5) | Text transformation | Translation, summarization |
Reminder: While BERT, GPT-2, and T5 are great for learning, you should try these for real-world use:
- Llama 4 for better generation
- DeBERTa-v3 for improved classification
- Flan-T5 for better instruction following
Why Transformers Scale to Large Data and Tasks
Transformers are fast because they analyze all the tokens in a sequence at the same time. Earlier models like RNNs worked step by step, which made them slow and likely to forget earlier content.
To analyze a 1000-token document:
- An RNN reads each token one by one.
- A transformer analyzes all the tokens in parallel. It uses self-attention to connect distant ideas (like linking the introduction to the conclusion).
This parallelism allows transformers to be trained on huge datasets using modern hardware like GPUs and TPUs. That is why models like GPT-3, Llama 3, and DeepSeek, which have hundreds of billions of parameters, exist today.
Comparing Sequential vs. Parallel Processing
# Compare how RNNs (sequential) and transformers (parallel) process sequences
import time
sequence = list(range(1000)) # Simulate a 1000-token document
# Sequential processing (like RNN)
start = time.time()
for token in sequence:
# Simulate processing each token (placeholder)
pass
seq_time = time.time() - start
# Parallel processing (like Transformer)
start = time.time()
# Simulate processing all tokens at once (placeholder)
_ = [token for token in sequence]
par_time = time.time() - start
print(f"Sequential (RNN-like) time: {seq_time:.6f}s")
print(f"Parallel (Transformer-like) time: {par_time:.6f}s")
Step-by-Step Explanation:
- Create sequence: Simulate a 1000-token document.
- Sequential processing: Loop through the tokens one by one (RNN-style).
- Parallel processing: Process all the tokens at the same time (Transformer-style).
- Compare times: Show the speed difference (this is a simplified demonstration).
This code simplifies reality, but it illustrates the concept: transformers use parallel hardware to process data much faster than sequential models.
Modern transformer deployments use efficient attention kernels (FlashAttention, Performer, Longformer) or combine attention with state-space or recurrent modules for longer contexts and improved scalability. Retrieval-augmented generation (RAG) is increasingly used for tasks that require factuality and long-context reasoning. Article 18 dives deep into these advances.
For your projects, this scalability means:
- You can train on bigger, more diverse datasets for better results.
- You can handle long documents, chats, or transcripts with ease.
- You can iterate faster and bring AI solutions to market sooner.
Summary: Transformers scale because they process everything in parallel and can capture long-range relationships. Modern extensions push the boundaries for large-scale AI even further.
Key Takeaways
Let’s review the main points. You now have a clear understanding of how Natural Language Processing (NLP) is the backbone of modern AI. You also know why transformer models, especially those that use self-attention, power today’s most capable language and multimodal systems. While BERT was a breakthrough and is still widely used, models like GPT-4, Llama 3, DeepSeek-R1, and Mistral are setting new standards for language understanding and generation as of 2025.
NLP allows machines to read, understand, and generate human language. It powers chatbots, voice assistants, document analysis, and, increasingly, multimodal applications that combine text, images, and audio. In business, NLP and its transformer-based advances speed up decision-making and create new opportunities, like instant customer support and rapid document summarization.
Earlier models like N-grams, RNNs, and LSTMs could process sequences but had trouble with long-range context, ambiguity, and large-scale data.
Environment Setup
Before we dive into transformers, let’s make sure you have the right environment.
Poetry Setup (Recommended for Projects)
# Install poetry if not already installed
curl -sSL https://install.python-poetry.org | python3 -
# Create new project
poetry new nlp-transformers
cd nlp-transformers
# Add dependencies
poetry add transformers==4.53.0 datasets torch nltk spacy
poetry add --group dev jupyter ipykernel
# Activate environment
poetry shell
Mini-conda Setup (Alternative)
# Download and install mini-conda from https://docs.conda.io/en/latest/miniconda.html
# Create environment with Python 3.12.9
conda create -n nlp-transformers python=3.12.9
conda activate nlp-transformers
# Install packages
conda install -c pytorch -c huggingface transformers datasets torch
conda install -c conda-forge jupyterlab spacy nltk
Traditional pip with pyenv
# Install Python 3.12.9 with pyenv
pyenv install 3.12.9
pyenv local 3.12.9
# Create virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install packages
pip install transformers==4.53.0 datasets torch nltk spacy jupyterlab
Setting up your local env (.env)
SENTIMENT_MODEL=cardiffnlp/twitter-roberta-base-sentiment-latest
CLASSIFICATION_MODEL=MoritzLaurer/deberta-v3-large-zeroshot-v1.1-all-33
GENERATION_MODEL=gpt2
HUGGINGFACE_TOKEN=your-token-here # Optional
Here is a simple bigram model that shows these limitations.
Bigram Language Model: Counting Word Pairs
from collections import defaultdict
def train_bigram_model(corpus):
model = defaultdict(lambda: defaultdict(int))
for sentence in corpus:
words = sentence.split()
for i in range(len(words)-1):
model[words[i]][words[i+1]] += 1
return model
corpus = ["The bank will close soon", "She sat by the bank of the river"]
bigram_model = train_bigram_model(corpus)
for prev_word, next_words in bigram_model.items():
print(f"After '{prev_word}': {dict(next_words)}")
# Example output:
# After 'The': {'bank': 1}
# After 'bank': {'will': 1, 'of': 1}
Step-by-Step Explanation:
- Build model: Count which words follow which in the corpus.
- Process sentences: Track the frequencies of word pairs.
- Display results: Show the possible next words after each word.
- Observe limitations: The model cannot tell the difference between ‘bank’ (finance) and ‘bank’ (river). It only sees one word ahead.
This code counts word sequences. After ‘bank’, the model might predict ‘will’ or ‘of’. But it cannot tell if ‘bank’ refers to a financial institution or a riverbank. It lacks context awareness. The meaning is lost.
Transformers changed everything. With self-attention, they consider every word in a sentence at the same time. This unlocks deep understanding and flexible generation. Self-attention allows models to weigh which words matter most, regardless of their position. This delivers dramatic improvements over earlier approaches.
Let’s see how transformers use self-attention in practice, using Hugging Face Transformers. Note: Make sure you have transformers version 4.40.0 or newer for API compatibility.
Inspecting Attention Weights with Hugging Face Transformers
# Requires: transformers >= 4.40.0
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased', output_attentions=True)
sentence = "The bank will not close until 5pm."
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Get attention weights from the last layer
last_layer_attention = outputs.attentions[-1] # Shape: (batch, num_heads, seq_len, seq_len)
print(f"Attention shape: {last_layer_attention.shape}")
# Example output:
# Attention shape: torch.Size([1, 12, 10, 10])
Step-by-Step Explanation:
- Load model: Import BERT with attention output enabled.
- Tokenize input: Convert the sentence to tokens.
- Run model: Process the tokens and extract the attention weights.
- Examine shape: Each attention matrix shows how the words relate (12 heads, 10x10 token relationships).
We load BERT, tokenize a sentence, and extract the attention weights. Each attention matrix shows how much each word ‘attends’ to the others. This helps to resolve meanings, like which sense of ‘bank’ applies. While BERT is still foundational, many modern tasks use larger or more specialized models like GPT-4, Llama 3, or DeepSeek-R1. They follow similar principles but at a greater scale and with enhanced capabilities.
Transformers come in three main architectural types:
- Encoder-only (e.g., BERT, DeBERTa, Longformer): Best for understanding and classifying text.
- Decoder-only (e.g., GPT-4, Llama 3, Mistral): Best for generating text.
- Encoder-decoder (e.g., T5, BART): Best for translation and summarization. Choose the right architecture, like selecting the perfect tool from your toolbox.
Recent research has introduced more efficient attention mechanisms and transformer variants—FlashAttention, Longformer, Performer, and BigBird—enabling longer sequences and larger datasets with reduced computational cost. These architectures are becoming increasingly important for real-world and enterprise-scale deployments.
Today, transformers power not only text tasks but also multimodal applications that combine language, vision, and audio (see Article 7). Models like CLIP, BLIP, Flamingo, and Gemini show how transformers can jointly process text and images. This enables advanced search, captioning, and cross-modal reasoning.
Hybrid approaches like Retrieval-Augmented Generation (RAG) and RETRO extend the capabilities of transformers by combining language models with external retrieval systems. This improves factual accuracy and grounds responses in current information. These techniques are now dominant in enterprise and research settings.
Modern fine-tuning increasingly uses parameter-efficient methods like LoRA and other PEFT techniques (see Article 12). These allow for the rapid adaptation of large models with minimal resources, which democratizes advanced AI for organizations of all sizes.
Why do transformers scale so well? Unlike RNNs, they process all words in parallel, which makes them fast and powerful for large datasets and models. Innovations in efficient attention and scalable architectures have led to breakthroughs like ChatGPT, Llama 3, and DeepSeek-R1. Thanks to tools like Hugging Face, even small teams can use these models in real-world projects.
Quick recap of essentials:
- NLP powers AI across industries and modalities.
- Early models had limits with context, scale, and ambiguity.
- Transformers use self-attention for deep, flexible understanding.
- Efficient transformer variants and multimodal models drive state-of-the-art performance.
- Choosing the right architecture and fine-tuning strategy is key.
- Mastering these basics will set you up for success with Hugging Face and modern AI development.
Ready for hands-on work? In the next chapter, you will set up your environment and run your first Hugging Face NLP pipeline. Review the glossary below, experiment with the code, and try the exercises. Ready to build with state-of-the-art transformers? Let’s go!
For a deeper look at transformer internals and efficient attention, see Article 4. To jump into hands-on work, continue to Article 3.
Glossary
- Natural Language Processing (NLP): The field of AI focused on enabling computers to understand and generate human language.
- N-gram: A sequence of N words from a text, used in basic language models.
- Recurrent Neural Network (RNN): A neural network for sequential data, with memory of previous steps.
- Long Short-Term Memory (LSTM): An RNN variant that can capture long-range dependencies.
- Transformer: A model architecture based on self-attention, which allows for parallel processing and deep context.
- Self-Attention: A mechanism that lets a model weigh the importance of each word relative to others in a sequence.
- Encoder/Decoder: The two main parts of a transformer. Encoders process input, and decoders generate output.
- Multi-Head Attention: Multiple self-attention mechanisms running in parallel to capture different relationships.
- Efficient Transformer: A transformer variant (e.g., FlashAttention, Longformer, Performer, BigBird) designed to handle longer sequences and reduce computational cost.
- Multimodal Transformer: A model that can process and relate information from multiple data types (e.g., text, images, audio), such as CLIP or Gemini.
- Retrieval-Augmented Generation (RAG): A technique that combines language models with external retrieval systems to improve factual accuracy and grounding.
- Parameter-Efficient Fine-Tuning (PEFT): Fine-tuning methods (e.g., LoRA) that adapt large models using a small number of trainable parameters, which reduces compute and memory needs.
Summary
This article has established the essential building blocks of NLP and language modeling. It has traced the journey from simple statistical models to the revolutionary transformer architecture. By understanding the challenges of language, the limitations of early models, and the breakthrough of self-attention, readers now have the foundational knowledge to confidently explore, fine-tune, and deploy transformer-based AI using the Hugging Face ecosystem.
NLP Foundations Repository Links
Repository Overview
This article has a companion repository that contains a comprehensive codebase. It demonstrates the evolution of Natural Language Processing from traditional N-gram models to modern transformer architectures. The project includes:
- Traditional NLP: An implementation of bigram models that shows why simple counting approaches fail at language understanding.
- Ambiguity Challenges: Demonstrations of word sense disambiguation problems (e.g., “bank” as a financial institution vs. a river bank).
- Transformer Solutions: Visualization of self-attention mechanisms that enable context understanding.
- Architecture Comparisons: Side-by-side demonstrations of encoder-only (BERT), decoder-only (GPT-2), and encoder-decoder (T5) models.
- Real-world Applications: Practical implementations of sentiment analysis, document classification, and text generation with quantified business value.
The codebase serves as a hands-on companion to the article “Why Language Is Hard for AI—and How Transformers Changed Everything.” It makes abstract NLP concepts tangible through executable code and interactive visualizations.
Documentation Links
Module Documentation
| Document | Description |
|---|---|
| attention_visualization.md | Self-attention mechanism visualization and implementation |
| config.md | Configuration management and environment setup |
| main.md | Orchestrator design and educational flow |
| model_architectures.md | Encoder, decoder, and encoder-decoder comparison |
| ngram_models.md | Traditional NLP approaches and their limitations |
| nlp_applications.md | Real-world business applications with ROI analysis |
| word_disambiguation.md | Ambiguity resolution and transformer advantages |
| attention_explorer_notebook.md | Interactive notebook guide with BertViz |
Setup and Configuration
| Document | Description |
|---|---|
| tutorial.md | Complete step-by-step tutorial for all platforms |
| Taskfile.md | Task automation documentation and customization |
| pyproject.md | Poetry configuration and dependency management |
| code_base.md | High-level architecture and design patterns |
| article_review.md | Suggested improvements to the main article |
Source Code Links
Python Modules
| File | Description |
|---|---|
| *\init\*.py | Package initialization defining module metadata and version |
| config.py | Centralized configuration management handling environment variables, model selection, and device optimization |
| main.py | Entry point orchestrating the educational journey through all NLP demonstrations |
| ngram_models.py | Traditional bigram language model implementation showcasing limitations of counting-based approaches |
| word_disambiguation.py | Word sense disambiguation demonstrations using zero-shot classification to resolve ambiguity |
| attention_visualization.py | Self-attention visualization showing how transformers understand context through attention weights |
| model_architectures.py | Comparison of encoder-only (BERT), decoder-only (GPT-2), and encoder-decoder (T5) architectures |
| nlp_applications.py | Real-world NLP applications including sentiment analysis, document classification, and text generation |
Interactive Notebook
| File | Description |
|---|---|
| attention_explorer.ipynb | Jupyter notebook providing interactive visualization of transformer attention patterns using BertViz |
Configuration Files
| File | Description |
|---|---|
| pyproject.toml | Poetry configuration defining dependencies, build settings, and tool configurations |
| Taskfile.yml | Task runner configuration providing convenient commands for all demonstrations |
| .env.example | Environment variable template for model selection and API tokens |
Quick Navigation
- Main Repository: https://github.com/RichardHightower/art_hug_02
- Article Early Version: article.md
- README: README.md
- Tutorial: tutorial.md
Apache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting