February 27, 2017
Introduction to BigData Analytics with Apache Spark Part 1
By Fadi Maalouli and R.H.
Spark Overview
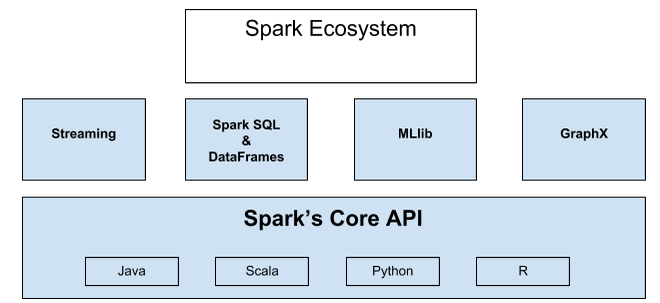
Apache Spark, an open source cluster computing system, is growing fast. Apache Spark has a growing ecosystem of libraries and framework to enable advanced data analytics. Apache Spark’s rapid success is due to its power and and ease-of-use. It is more productive and has faster runtime than the typical MapReduce BigData based analytics. Apache Spark provides in-memory, distributed computing. It has APIs in Java, Scala, Python, and R. The Spark Ecosystem is shown below.
 [Display ] (http://2.bp.blogspot.com/-bJJ6nHF4r1o/VeFRpor-bfI/AAAAAAAAAUQ/WiFPHP4_pBA/s1600/Screen%2BShot%2B2015-08-28%2Bat%2B11.30.22%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
[Display ] (http://2.bp.blogspot.com/-bJJ6nHF4r1o/VeFRpor-bfI/AAAAAAAAAUQ/WiFPHP4_pBA/s1600/Screen%2BShot%2B2015-08-28%2Bat%2B11.30.22%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
{kind=link}
The entire ecosystem is built on top of the core engine. The core enables in memory computation for speed and its API has support for Java, Scala, Python, and R. Streaming enables processing streams of data in real time. Spark SQL enables users to query structured data and you can do so with your favorite language, a DataFrame resides at the core of Spark SQL, it holds data as a collection of rows and each column in the row is named, with DataFrames you can easily select, plot, and filter data. MLlib is a Machine Learning framework. GraphX is an API for graph structured data. This was a brief overview on the ecosystem.
A little history about Apache Spark:
-
Originally developed in 2009 in UC Berkeley AMP lab, became open sourced in 2010, and now it is part of the top level Apache Software Foundation.
-
Has about 12,500 commits made by about 630 contributors (as seen on the Apache Spark Github repo).
-
Mostly written in Scala.
-
Google search interests for Apache Spark has sky rocketed recently, indicating a wide range of interest. (108,000 searches in July according to Google Ad Word Tools about ten times more than Microservices).

-
Some of Spark’s distributors: IBM, Oracle, DataStax, BlueData, Cloudera…
-
Some of the applications that are built using spark: Qlik, Talen, Tresata, atscale, platfora…
-
Some of the companies that are using Spark: Verizon, NBC, Yahoo, Spotify…
The reason people are so interested in Apache Spark is it puts the power of Hadoop in the hands of developers. It is easier to setup an Apache Spark cluster than an Hadoop Cluster. It runs faster. And it is a lot easier to program. It puts the promise and power of Big Data and real time analysis in the hands of the masses. With that in mind, let’s introduce Apache Spark in this quick tutorial.
Cloudurable specialize in AWS DevOps Automation for Cassandra, Spark and Kafka
We hope this web page on Spark is helpful. We also provide Spark consulting, Casandra consulting and Kafka consulting to get you setup fast in AWS with CloudFormation and CloudWatch. Support us by checking out our Spark Training, Casandra training and Kafka training.
Download Spark, and How to use the interactive shell
A great way to experiment with Apache Spark is to use the available interactive shells. There is a Python Shell and a Scala shell.
To download Apache Spark go here , and get the latest pre built version so we can run the shell out of the box.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Right now Apache Spark is version 1.4.1 released on July 15, 2015.
Unzip Spark
tar -xvzf ~/spark-1.4.1-bin-hadoop2.4.tgz
To run the Python shell
cd spark-1.4.1-bin-hadoop2.4
./bin/pyspark
We won’t use the Python shell here in this section.
The Scala interactive shell runs on the JVM therefore it enables you to use Java libraries.
To run the Scala shell
cd spark-1.4.1-bin-hadoop2.4
./bin/spark-shell
You should see something like this:
The Scala shell welcome message
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25)
Type in expressions to have them evaluated.
Type :help for more information.
15/08/24 21:58:29 INFO SparkContext: Running Spark version 1.4.1
The following is a simple exercise just to get you started with the shell. You might not understand what we are doing right now but we will explain in detail later. With the Scala shell, do the following:
Create a textFile RDD from the README file in Spark
val textFile = sc.textFile("README.md")
Get the first element in the RDD textFile
textFile.first()
res3: String = # Apache Spark
You can filter the RDD textFile to return a new RDD that contains all the lines with the word Spark, then count its lines.
Filtered RDD linesWithSpark and count its lines
val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark.count()
res10: Long = 19
To find the line with the most amount of words in the RDD linesWithSpark do the following. Using the map method, map each line in the RDD to a number, and look for spaces. Then use the method reduce to look for the lines that has the most amount of words.
####Find the line in the RDD textFile that has the most amount of words
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res11: Int = 14
Line 14 has the most words.
You can also import Java libraries for example like the Math.max() method because the arguments map and reduce are Scala function literals.
Importing Java methods in the Scala shell
import java.lang.Math
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
res12: Int = 14
We can easily cache data in memory for example. Lets cache the filtered RDD linesWithSpark:
linesWithSpark.cache()
res13: linesWithSpark.type = MapPartitionsRDD[8] at filter at <console>:23
linesWithSpark.count()
res15: Long = 19
This was a brief overview on how to use the Spark interactive shell.
RDDs
Spark enables users to execute tasks in parallel on a cluster. This parallelism is made possible by using one of the main component of Spark, a RDD. A RDD (Resilient distributed data) is a representation of data. A RDD is data that can be partitioned on a cluster (sharded data if you will). The partitioning enables the execution of tasks in parallel. The more partitions you have, the more parallelism you can do. The diagram bellow is a representation of a RDD:
 [Display ] (http://3.bp.blogspot.com/-t_IupTFEy90/VdvqznUkOfI/AAAAAAAAAQ4/7-TNDWH3Xp4/s1600/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.13%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
[Display ] (http://3.bp.blogspot.com/-t_IupTFEy90/VdvqznUkOfI/AAAAAAAAAQ4/7-TNDWH3Xp4/s1600/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.13%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
{kind=link}
Think of each column as a partition, you can easily assign these partitions to nodes on a cluster.
In order to create a RDD, you can read data from an external storage; for example from Cassandra or Amazon Simple Storage Service, HDFS, or any data that offers Hadoop input format. You can also create a RDD by reading a text file, an array, or JSON. On the other hand if the data is local to your application you just need to parallelize it then you will be able to apply all the Spark features on it and do analysis in parallel across the Apache Spark Cluster. To test it out, with a Scala Spark shell:
Make a RDD thingsRDD from a list of words
val thingsRDD = sc.parallelize(List("spoon", "fork", "plate", "cup", "bottle"))
thingsRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:24
####Count the word in the RDD thingsRDD
thingsRDD.count()
res16: Long = 5
In order to work with Spark you need to start with a Spark Context. When you are using a shell, Spark Context already exists as sc. When we call the parallelize method on the Spark Context, we will get a RDD that is partitioned and ready to be distributed across nodes.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
What can we do with a RDD?
With a RDD, we can either transform data or take actions on that data. This means with a transformation we can change its format, search for something, filter data etc. With actions you make changes, you pull data out, collect data, and even count().
For example, lets create a RDD textFile from the text file README.md available in Spark, this file contains lines of text. When we read the file into the RDD with textFile, the data will get partitioned into lines of text which can be spread across the cluster and operated on in parallel.
####Create RDD textFile from README.md
val textFile = sc.textFile("README.md")
####Count the lines
textFile.count()
res17: Long = 98
The count 98 represents the amount of lines the file README.md has.
Will get something that looks like this:
 [Display ] (http://1.bp.blogspot.com/-pEGRBiyUXug/VdvqzqOz4cI/AAAAAAAAARA/lPAijbSTp-E/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.24%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
[Display ] (http://1.bp.blogspot.com/-pEGRBiyUXug/VdvqzqOz4cI/AAAAAAAAARA/lPAijbSTp-E/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.24%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
Then we can filter out all the lines that have the word Spark, and create a new RDD linesWithSpark that contains that filtered data.
####Create the filtered RDD linesWithSpark
val linesWithSpark = textFile.filter(line => line.contains("Spark"))
Using the previous diagram where we showed how a textFile RDD would look like, the RDD linesWithSpark will look like the following:
 [Display ] (http://4.bp.blogspot.com/-QhoC7esU6_0/Vdvqzl4qS_I/AAAAAAAAAQ8/PDQhkFF5rpE/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.34%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
[Display ] (http://4.bp.blogspot.com/-QhoC7esU6_0/Vdvqzl4qS_I/AAAAAAAAAQ8/PDQhkFF5rpE/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.09.34%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
It is worth mentioning, we also have what is called a Pair RDD, this kind of RDD is used when we have a key/value paired data. For example if we have data like the following table, Fruits matching its color:
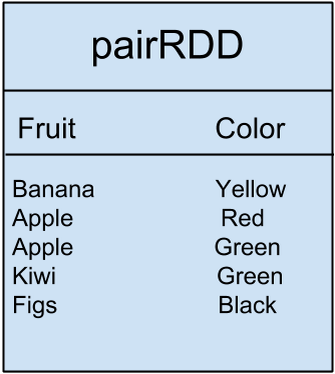
[Display ] (http://4.bp.blogspot.com/-nvVTePFraZ8/Vd1dwJ5KJWI/AAAAAAAAAR4/RjkhSWLuekQ/s400/Screen%2BShot%2B2015-08-25%2Bat%2B11.33.10%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
We can execute a groupByKey() transformation on the fruit data to get:
pairRDD.groupByKey()
Banana [Yellow]
Apple [Red, Green]
Kiwi [Green]
Figs [Black]
This transformation just grouped 2 values which are (Red and Green) with one key which is (Apple). These are examples of transformation changes so far.
Once we have filtered a RDD, we can collect/materialize its data and make it flow into our application, this is an example of an action. Once we do this, all the data in the RDD are gone, but we can still call some operations on the RDD’s data since they are still in memory.
####Collect or materialize the data in linesWithSpark RDD
linesWithSpark.collect()
Important to note that every time we call an action in Spark for example a count() action, Spark will go over all the transformations and computations done to that point and then return the count number, this will be somewhat slow. To fix this problem and increase the performance speed you can cache a RDD in memory. This way when you call an action time after time, you won’t have to start the process from the beginning, you just get the results of the cached RDD from memory.
####Cashing the RDD linesWithSpark
linesWithSpark.cache()
If you like to delete the RDD linesWithSpark from memory you can use the unpersist() method:
####Deleting linesWithSpark from memory
linesWithSpark.unpersist()
Otherwise Spark automatically delete the oldest cashed RDD using the least recently used logic (LRU).
Here is a list to summarize the Spark process from start to end:
- Create a RDD of some sort of data.
- Transform the RDD’s data by filtering for example.
- Cache the transformed or filtered RDD if needed to be reused.
- Do some actions on the RDD like pulling the data out, counting, storing data to Cassandra etc…
Here is a list of some of the transformations that can be used on a RDD:
- filter()
- map()
- sample()
- union()
- groupbykey()
- sortbykey()
- combineByKey()
- subtractByKey()
- mapValues()
- Keys()
- Values()
Here is a list of some of the actions that can be made on a RDD:
- collect()
- count()
- first()
- countbykey()
- saveAsTextFile()
- reduce()
- take(n)
- countBykey()
- collectAsMap()
- lookup(key)
For the full lists with their descriptions, check out the following Spark documentation.
Conclusion
We introduced Apache Spark, a fast growing, open source cluster computing system. We showed some of the Apache Spark libraries and frameworks to enable advanced data analytics. We showed a glimpse of why Apache Spark is rapidly succeeding due to its power and and ease-of-use. We demonstrated Apache Spark to provide an in-memory, distributed computing environment and just how easy it is to use and grasp.
##Reference
About Cloudurable
We hope you enjoyed this article. Please provide feedback. Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Check out our new GoLang course. We provide onsite Go Lang training which is instructor led.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting