February 27, 2017
Analytics with Apache Spark Tutorial Part 2 : Spark SQL
Using Spark SQL from Python and Java
Combining Cassandra and Spark
By Fadi Maalouli and R.H.
Spark, a very powerful tool for real-time analytics, is very popular. In the first part of this series on Spark we introduced Spark. We covered Spark’s history, and explained RDDs (which are used to partition data in the Spark cluster). We also covered the Apache Spark Ecosystem.
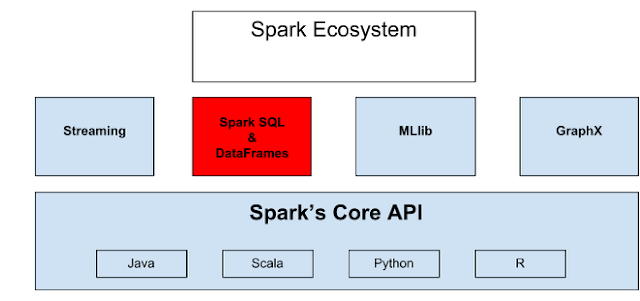
Part 2 introduces an important part of the Spark Ecosystem, namely, Spark SQL and DataFrames. This tutorial will show how to use Spark and Spark SQL with Cassandra. In case you have missed part 1 of this series, check it out [Introduction to Apache Spark Part 1, real-time analytics] (http://www.mammatustech.com/introduction-to-apache-spark).
Apache Spark is the natural successor and complement to Hadoop and continues the BigData trend. Spark provides an easy to use API to perform large distributed jobs for data analytics. It is faster than other forms of analytics since much can be done in-memory. Apache Spark puts the power of BigData into the hands of mere mortal developers to provide real-time data analytics. Spark SQL is an example of an easy-to-use but power API provided by Apache Spark.
 [Display ] (http://1.bp.blogspot.com/-BklNJ2CjC3s/VejWK5i2WHI/AAAAAAAAAVU/ih103fAbUGY/s640/Screen%2BShot%2B2015-09-03%2Bat%2B4.21.21%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
[Display ] (http://1.bp.blogspot.com/-BklNJ2CjC3s/VejWK5i2WHI/AAAAAAAAAVU/ih103fAbUGY/s640/Screen%2BShot%2B2015-09-03%2Bat%2B4.21.21%2BPM.png) - [Edit] (https://docs.google.com/document/d/1rg5yaH1OHaEbJZxFAiAW7GXXek8F6KJ51pzr7U7ec1Y/edit?usp=sharing)
Spark SQL
Spark SQL lets you run SQL and hiveQL queries easily. (Note that hiveQL is from Apache Hive which is a data warehouse system built on top of Hadoop for providing BigData analytics.) Spark SQL can locate tables and meta data without doing any extra work. Spark SQL provides the ability to query structured data inside of Spark, using either SQL or a familiar DataFrame API (RDD). You can use Spark SQL with your favorite language; Java, Scala, Python, and R:
Spark SQL Query data with Java
String query = "SELECT * FROM table";
ResultSet results = session.execute(query);
At the core of Spark SQL there is what is called a DataFrame. A DataFrame simply holds data as a collection of rows and each column in the row is named. With DataFrames you can easily select, plot, and filter data.
You can use DataFrames to input and output data, for example you can mount the following data formats as tables and start doing query operations on them out of the box using DataFrames in Spark SQL:
- RDD
- JSON
- Hive
- Parquet
- MySQL
- HDFS
- S3
- JDBC
- and more …
Once you read the data, with DataFrames you can easily filter data, select column, count, average, and join data together from different sources.
If you are planning on reading and writing data to do analysis, Spark SQL can automate the process and make it much easier for you.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Let’s demonstrate how to use Spark SQL and DataFrames within the Python Spark shell with the following example. We will pull the commit history data for QBit, the Java Microservices Lib from Github. Load it into Spark, then play with the data, here are the steps:
Start the Python Spark shell, with your terminal:
Start the Python Spark shell
cd spark-1.5.0-bin-hadoop2.4
./bin/pyspark
15/08/22 22:30:40 INFO BlockManagerMaster: Registered BlockManager
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.5.0
/_/
Using Python version 2.7.5 (default, Mar 9 2014 22:15:05)
SparkContext available as sc, HiveContext available as sqlContext.
Pull the commit history for QBit from github into a file called test.log:
####Pull the commit history as a log file
git log > test.log
Since we are using Python this time let’s first make test.log as a RDD call it textFile and do some operations on it:
####Create a textFile RDD from test.log
textFile = sc.textFile("../qbit/test.log")
Now we have a RDD called textFile that is partitioned into lines of text, let’s count the lines in this RDD:
Count the lines in the textFile with Spark RDD
textFile.count()
5776
We got 5776 lines. Let’s filter all the lines that have the word commit:
Filter the lines with Commit using Spark RDD
linesWithCommit = textFile.filter(lambda line: "commit" in line)
Enough playing with RDDs since we have done so in a previous example, we just wanted to demonstrate how easy it is to do with Python.
Now to use a Dataframe, let’s pull the log history file from github as a JSON type and call the file sparktest.json:
Pull the commit history from github as a JSON
git log --pretty=format:'{"commit":"%H","author":"%an","author_email":"%ae","date":"%ad","message":"%f"}' > sparktest.json
At the start of Spark SQL operation, we need a sqlContext. A sqlContext can be made by using SparkContext:
Create the Spark SQL context
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
Within the shell sqlContext will exist as sqlContext similarly SparkContext will exist as sc out of the box no need to make one.
Now let’s load the JSON data into spark as a DataFrame called dataframe:
Load the JSON data into a DataFrame called dataframe
dataframe = sqlContext.load("../qbit/sparktest.json", "json")
When we load the data, you just call load() on the sqlContext with the file directory and file type as your parameters. Spark will figure out all the columns and their names automatically for dataframe. To make sure that everything worked as it should, print the schema:
Print the schema for the Spark SQL dataframe
dataframe.printSchema()
root
|-- author: string (nullable = true)
|-- author_email: string (nullable = true)
|-- commit: string (nullable = true)
|-- date: string (nullable = true)
|-- message: string (nullable = true)
This root map will show the column names and types for each row. Each row in this example represents one commit on Github for the QBit Microservices Lib project. Once we have that we can start playing with the data.
For example we can get the first commit on file which represents the latest commit on github:
Getting the latest commit to do analytics with it
dataframe.first()
Row(author=u'Richard Hightower', author_email=u'richardhightower@gmail.com', commit=u'696a94f80d1eedae97175f76b9139a340fab1a27', date=u'Wed Aug 19 17:51:11 2015 -0700', message=u'Merge-pull-request-359-from-advantageous-add_better_uri_param_handling')
We can select an entire column and show its contents. For example let’s select the author column and show the last 20 contributors on the QBit Microservices Lib, by default Spark will show the last 20:
analytics with Spark SQL - Select the columns author and show the last 20
dataframe.select("author").show()
+-----------------+
| author|
+-----------------+
|Richard Hightower|
| Rick Hightower|
| Rick Hightower|
|Richard Hightower|
| Rick Hightower|
|Richard Hightower|
| Rick Hightower|
|Geoffrey Chandler|
|Geoffrey Chandler|
|Richard Hightower|
|Richard Hightower|
|Richard Hightower|
|Richard Hightower|
|Richard Hightower|
|Richard Hightower|
| Rick Hightower|
| Rick Hightower|
| Rick Hightower|
| Rick Hightower|
| Rick Hightower|
+-----------------+
You can show more or less simply by setting the show() parameter to the desired number, let’s show the last 5 authors that contributed to the QBit Microservices Lib:
Select the column author and show the last 5
dataframe.select("author").show(5)
+-----------------+
| author|
+-----------------+
|Richard Hightower|
| Rick Hightower|
| Rick Hightower|
|Richard Hightower|
| Rick Hightower|
+-----------------+
Think about this for a moment. Here we took some fairly unstructured data. In this case we grabbed some git commit logs from a project, and we can immediately start running queries against it. Now imagine doing this with thousands of projects, perhaps against every git repository in a big company. And imagine if we needed to do some analysis often that instead of indexing this one off data for analysis, we just use our Spark cluster to process a ton of unstructured data. You can start to see the power of Spark as a realtime data analytics platform, which is both easy to use and scalable and powerful.
Let’s select the date column and show the last 20 commit dates:
Select the column date and show the last 20 commit dates
dataframe.select("date").show()
+--------------------+
| date|
+--------------------+
|Wed Aug 19 17:51:...|
|Wed Aug 19 17:37:...|
|Wed Aug 19 16:59:...|
|Wed Aug 19 14:47:...|
|Wed Aug 19 14:42:...|
|Wed Aug 19 13:05:...|
|Wed Aug 19 11:59:...|
|Mon Aug 17 10:18:...|
|Mon Aug 17 10:17:...|
|Mon Aug 17 00:46:...|
|Sun Aug 16 23:52:...|
|Sun Aug 16 23:33:...|
|Sun Aug 16 23:05:...|
|Sun Aug 16 23:03:...|
|Sun Aug 16 22:33:...|
|Thu Aug 13 21:20:...|
|Thu Aug 13 21:15:...|
|Thu Aug 13 20:31:...|
|Thu Aug 13 20:05:...|
|Thu Aug 13 20:04:...|
+--------------------+
Let’s get the number of commits done on the QBit Microservices Lib from the dataframe, by counting the rows:
The number of commits done on QBit Microservice Lib
dataframe.count()
914
914 is the number of commits, we can also see that on Github as well.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
We can also use filters on DataFrames, for example we can see how many commits were made by Richard Hightower and Geoffrey Chandler:
Filter commits made by Richard Hightower and count them
dataframe.filter(dataframe.author =="Richard Hightower").count()
708
708 commits were made by Richard Hightower.
Filter commits made by Geoffrey Chandler and count them
dataframe.filter(dataframe.author =="Geoffrey Chandler").count()
102
102 commits were made by Geoffrey Chandler.
In the previous example we have created a DataFrame from a JSON data file. You can also make a DataFrame out of a RDD in two different ways:
- If columns and their types are not known until runtime, you can create a schema and apply it to a RDD.
- If columns and their types are known, you can use a method called reflection.
For simplicity, to create a RDD, let’s use the people.txt file provided by Spark, it has only three names with their age separated by a comma. Located under the following directory ~/spark/examples/src/main/resources/people.txt. The coding steps will be commented well to understand them.
People.txt Listing
Michael, 29
Andy, 30
Justin, 19
Create a Spark SQL schema and apply it to the textFile RDD
# Import data types
from pyspark.sql.types import *
# Create a RDD from `people.txt`
# then convert each line to a tuple.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: (p[0], p[1].strip()))
# encode the schema in a string.
schemaString = "name age"
# Create a type fields
fields = [StructField(field_name, StringType(), True) \
for field_name in schemaString.split()]
# Create the schema
schema = StructType(fields)
# Apply the schema to the RDD.
schemaPeople = sqlContext.createDataFrame(people, schema)
# In order to query data you need
# to register the DataFrame as a table.
schemaPeople.registerTempTable("people")
# Using sql query all the name from the table
results = sqlContext.sql("SELECT name FROM people")
# The results of SQL queries are RDDs
# and support all the normal RDD operations.
names = results.map(lambda p: "Name: " + p.name)
for name in names.collect():
print name
Will produce the following:
Output
Name: Michael
Name: Andy
Name: Justin
Which are indeed all the names.
You can see that it is easy to take unstructured data and give it enough structure to start querying it. Spark can even split the data up amongst cluster nodes and do the analysis in parallel. You can start to see Apache Spark’s appeal as the a fast and general engine for large-scale data processing for real-time analytics and ad hoc fast analytics.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Let’s cover the reflection method for doing analytics.
Using the reflection method for analytics with Spark SQL
# First we need to import the following Row class
from pyspark.sql import SQLContext, Row
# Create a RDD peopleAge,
# when this is done the RDD will
# be partitioned into three partitions
peopleAge = sc.textFile("examples/src/main/resources/people.txt")
# Since name and age are separated by a comma let's split them
parts = peopleAge.map(lambda l: l.split(","))
# Every line in the file will represent a row
# with 2 columns name and age.
# After this line will have a table called people
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
# Using the RDD create a DataFrame
schemaPeople = sqlContext.createDataFrame(people)
# In order to do sql query on a dataframe,
# you need to register it as a table
schemaPeople.registerTempTable("people")
# Finally we are ready to use the DataFrame.
# Let's query the adults that are aged between 21 and 50
adults = sqlContext.sql("SELECT name FROM people \
WHERE age >= 21 AND age <= 50")
# loop through names and ages
adults = adults.map(lambda p: "Name: " + p.name)
for Adult in adults.collect():
print Adult
Will get:
Output
Name: Michael
Name: Andy
Which are indeed aged between 21 and 50.
Using Spark, SparkSQL while working with Cassandra
Spark working with Cassandra
Let’s say you want to make a program with Java that uses Spark and Cassandra. Here are the steps that enables Apache Spark to work with Apache Cassandra:
First we need to import the following dependencies:
- spark-cassandra-connector_2.10:1.1.1-rc4'
- spark-cassandra-connector-java_2.10:1.1.1'
- spark-streaming_2.10:1.5.0'
Using Gradle:
Gradle build file for analytics example with Spark SQL and Cassandra
dependencies {
//Spark and Cassandra connector to work with java
compile 'com.datastax.spark:spark-cassandra-connector_2.10:1.1.1-rc4'
compile 'com.datastax.spark:spark-cassandra-connector-java_2.10:1.1.1'
compile 'org.apache.spark:spark-streaming_2.10:1.5.0'
}
Next we setup Spark configurations. The SparkConf is to configure properties like Spark master and application name, as well as arbitrary key-value pairs such as spark.cassandra.connection.host through the set() method.
Spark master is the cluster manager to connect to, some of the allowed URLs:
- local (Run Spark locally with one worker thread like we are using in this example)
- local[K] Run Spark locally with K threads, usually k is setup to match the number of cores n your machine
spark://HOST:PORT(Connect to a given cluster master. The port must match with your master, default is 7077)
In order to connect Spark with Cassandra we need to set spark.cassandra.connection.host to Sparks masters host which is our local host in this case; here is the Spark configuration:
SparkConf conf = new SparkConf();
...
conf.setAppName("TODO spark and cassandra");
conf.setMaster("local");
conf.set("spark.cassandra.connection.host", "localhost");
Now we are ready to create the schema, meaning create a keyspace and a table in Cassandra that will hold our data:
Create a connector instance of CassandraConnector and create a keyspace todolist and a table todolisttable in Cassandra
private void createSchema(JavaSparkContext sc) {
CassandraConnector connector =
CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
session.execute(deletekeyspace);
session.execute(keyspace);
session.execute("USE todolist");
session.execute(table);
session.execute(tableRDD);
}
}
As you can see above we create an instance connector of CassandraConnector and execute the CQL (Cassandra Query Language). We will cover this topic in more detail in a different article - coming soon.
####The Cassandra CQL commands used
/* Delete keyspace todolist if exists. */
String deletekeyspace = "DROP KEYSPACE IF EXISTS todolist";
/* Create keyspace todolist. */
String keyspace = "CREATE KEYSPACE IF NOT EXISTS todolist" +
" WITH replication = {'class': 'SimpleStrategy'," +
" 'replication_factor':1}";
/* Create table todolisttable. */
String table = "CREATE TABLE todolist.todolisttable(" +
+ " id text PRIMARY KEY, "
+ " description text, "
+ " category text, "
+ " date timestamp )";
/* Create table temp. */
String tableRDD = "CREATE TABLE todolist.temp(id text PRIMARY KEY, "
+ "description text, "
+ "category text )";
Now we have two tables todolisttable and temp, let’s load some data into todolisttable table, using Cassandra CQL to load some todo items:
private void loadData(JavaSparkContext sc) {
CassandraConnector connector = CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
session.execute(task1);
session.execute(task2);
session.execute(task3);
session.execute(task4);
session.execute(task5);
session.execute(task6);
session.execute(task7);
}
Here are the todo items that are being loaded into Cassandra, followed by the CQL commands.
todo items that are loaded with Cassandra CQL commands into Spark
TodoItem item = new TodoItem("George", "Buy a new computer", "Shopping");
TodoItem item2 = new TodoItem("John", "Go to the gym", "Sport");
TodoItem item3 = new TodoItem("Ron", "Finish the homework", "Education");
TodoItem item4 = new TodoItem("Sam", "buy a car", "Shopping");
TodoItem item5 = new TodoItem("Janet", "buy groceries", "Shopping");
TodoItem item6 = new TodoItem("Andy", "go to the beach", "Fun");
TodoItem item7 = new TodoItem("Paul", "Prepare lunch", "Coking");
//index data
String task1 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item.toString();
String task2 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item2.toString();
String task3 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item3.toString();
String task4 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item4.toString();
String task5 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item5.toString();
String task6 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item6.toString();
String task7 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item7.toString();
And to query the data from Cassandra’s todolisttable:
Query data from Cassandra’s todolisttable
private void queryData(JavaSparkContext sc) {
CassandraConnector connector =
CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
ResultSet results = session.execute(query);
System.out.println("Query all results from cassandra:\n" + results.all());
}
}
To access the data from Cassandra’s table as a Spark RDD:
Access data from Cassandra’s table as a Spark RDD
public void accessTableWitRDD(JavaSparkContext sc){
JavaRDD<String> cassandraRDD = javaFunctions(sc).cassandraTable("todolist", "todolisttable")
.map(new Function<CassandraRow, String>() {
@Override
public String call(CassandraRow cassandraRow) throws Exception {
return cassandraRow.toString();
}
});
}
In order to read tables from Cassandra as a RDD, we use cassandraTable("keyspace", "table") method. For cassandraTable method to work we need to wrap the sparkcontext with a special wrapper, and we use javaFunctions() method to do so.
For this RDD the data type is CassandraRow
To print out this RDD:
####Print out the Spark RDD’s data
System.out.println("\nData as CassandraRows from a RDD: \n" + StringUtils.join(cassandraRDD.toArray(), "\n"));
We can also save RDDs into Cassandra as easily as reading them, to do so will create a RDD of type TodoItem and populate it with some data then save it into a temp table in Cassandra:
####Create a RDD holding a list of todo items then save to Cassandra
public void saveRDDToCass(JavaSparkContext sc) {
List<TodoItem> todos = Arrays.asList(
new TodoItem("George", "Buy a new computer", "Shopping"),
new TodoItem("John", "Go to the gym", "Sport"),
new TodoItem("Ron", "Finish the homework", "Education"),
new TodoItem("Sam", "buy a car", "Shopping"),
new TodoItem("Janet", "buy groceries", "Shopping"),
new TodoItem("Andy", "go to the beach", "Fun"),
new TodoItem("Paul", "Prepare lunch", "Coking")
);
JavaRDD<TodoItem> rdd = sc.parallelize(todos);
javaFunctions(rdd).writerBuilder("todolist", "temp", mapToRow(TodoItem.class)).saveToCassandra();
Above we just created an array list of TodoItem then created a Spark RDD rdd with all the data using the parallelize method, and then saved rdd into a keyspace todolist and a table temp by invoking the writerBuilder method on the wrapped rdd.
To make sure the rdd was saved into the table temp in Cassandra, let’s query temp from Cassandra:
Query the temp table from Cassandra
String query1 = "SELECT * FROM todolist.temp";
ResultSet results1 = session.execute(query1);
System.out.println("\nQuery all results from temp" +
" table after saving a RDD into Cassandra:\n" +
results1.all());
At the end we will provide the full code listing. Also there will be a Run it section with all the instruction on how to pull the code from Github and on how to run it on your machine.
Spark SQL working with Cassandra
Spark SQL enables you to query structured data such as RDDs and any stored data on Cassandra, in order to use Spark SQL we need to do the following:
- Create a SQLContext. (SQLContext wraps the SparkContext)
- Load data in parquet format (parquet format is a columnar storage; meaning that data tables are structured as columns sections of data rather than rows of data).
- Once data is loaded then we will have a
DataFrame. - This extra info enables you to query data after you register the data as a table using SQL
- SQL queries are of type row objects
- SQL query is a very powerful tool
Note that the Spark DataFrame has all the functions as a normal Spark RDD, plus more meta-data about the names and types of the columns in the dataset.
Helpful information about Spark SQL:
- Spark SQL can cache tables in memory
- When you query with SQL, the results are RDDs
- Reading data in parquets: columnar storage helps you to avoid not needed data
- RDDs can be stored in parquet files
- JSON objects can be converted into
DataFrameby using ajsonRDD
Recall that RDD provides the parallelism. An RDD is a is a Resilient distributed data. An RDD is a main component of Spark. A RDD (Resilient distributed data) is a representation of data. A RDD is data that can be partitioned on a cluster (sharded data if you will). The partitioning enables the execution of tasks in parallel. The more partitions you have, the more parallelism you can do.
Parquet is a columnar format. Parquets are supported by other data processing systems like Hive. Apache Parquet is part of the Hadoop ecosystem. Parquets are designed to be cross-language, cross data processing framework, columnar data format. Spark SQL can read and write Parquet files. These Parquet preserves the schema of the data.
Now let’s demonstrate how to use Spark SQL in java using a todo item example.
First we need to import spark-sql dependcy in our gradle file:
Use the Spark SQL dependency in Gradle
dependencies {
compile 'org.apache.spark:spark-sql_2.10:1.5.0'
}
Next, create the Spark’s configuration to connect with Cassandra:
Spark configuration for Cassandra
SparkConf conf = new SparkConf();
conf.setAppName("TODO sparkSQL and cassandra");
conf.setMaster("local");
conf.set("spark.cassandra.connection.host", "localhost");
Create a Spark context (JavaSparkContext).
Create a Spark context
JavaSparkContext sc = new JavaSparkContext(conf);
The SQLContext is used to connect to Cassandra using SQL:
Create a Spark SQL Context
SQLContext sqlContext = new SQLContext(sc);
SQLContext enables you to register RDDs, and to do query operations using Spark SQL.
Let’s create a RDD (rdd) and load some data to it (TodoItems):
RDD loading TodoItems
List<TodoItem> todos = Arrays.asList(
new TodoItem("George", "Buy a new computer", "Shopping"),
new TodoItem("John", "Go to the gym", "Sport"),
new TodoItem("Ron", "Finish the homework", "Education"),
new TodoItem("Sam", "buy a car", "Shopping"),
new TodoItem("Janet", "buy groceries", "Shopping"),
new TodoItem("Andy", "go to the beach", "Fun"),
new TodoItem("Paul", "Prepare lunch", "Cooking")
);
JavaRDD<TodoItem> rdd = sc.parallelize(todos);
Notice that we parallelize the Todo data among the Spark cluster. The JavaRDD is produced from the context.parallelize.
Then create a DataFrame from the sqlContext:
Create a DataFrame from the sqlContext
DataFrame dataframe = sqlContext.createDataFrame(rdd, TodoItem.class);
Note that it got the schema from the Java class TodoItem.class.
Then register it as a table called todo:
Register DataFrame as a table called todo
sqlContext.registerDataFrameAsTable(dataframe, "todo");
This will allow us to query against the DataFrame using the name todo.
Now we are ready to do all the operations offered by Spark SQL, lets first count how many todo items there is, this will also load the data in memory to enable faster query operations:
Getting the count of TODO items with the DataFrame
System.out.println("Total number of TodoItems = [" + rdd.count() + "]\n");
And finally let’s query the data using SQL:
Show and select the TodoItems in a DataFrame using Spark SQL:
DataFrame result = sqlContext.sql("SELECT * from todo");
System.out.println("Show the DataFrame result:\n");
result.show();
System.out.println("Select the id column and show its contents:\n");
result.select("id").show();
To get the code and for instructions on how to run it, go to the Run it section at the end. Here is the full code listing for this example.
Full code Listing
SparkApp.java Linsting
package com.example;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
import com.datastax.spark.connector.cql.CassandraConnector;
import com.datastax.spark.connector.japi.CassandraRow;
import org.apache.commons.lang.StringUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.Serializable;
import java.util.Arrays;
import java.util.List;
import static com.datastax.spark.connector.japi.CassandraJavaUtil.javaFunctions;
import static com.datastax.spark.connector.japi.CassandraJavaUtil.mapToRow;
//import org.apache.cassandra.cql.BatchStatement;
/**
* Created by fadi on 5/18/15.
*/
public class SparkApp implements Serializable {
static final Logger logger = LoggerFactory.getLogger(SparkApp.class);
TodoItem item = new TodoItem("George", "Buy a new computer", "Shopping");
TodoItem item2 = new TodoItem("John", "Go to the gym", "Sport");
TodoItem item3 = new TodoItem("Ron", "Finish the homework", "Education");
TodoItem item4 = new TodoItem("Sam", "buy a car", "Shopping");
TodoItem item5 = new TodoItem("Janet", "buy groceries", "Shopping");
TodoItem item6 = new TodoItem("Andy", "go to the beach", "Fun");
TodoItem item7 = new TodoItem("Paul", "Prepare lunch", "Coking");
String keyspace = "CREATE KEYSPACE IF NOT EXISTS todolist WITH replication = {'class': 'SimpleStrategy', 'replication_factor':1}";
//index data
String task1 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item.toString();
String task2 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item2.toString();
String task3 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item3.toString();
String task4 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item4.toString();
String task5 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item5.toString();
String task6 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item6.toString();
String task7 = "INSERT INTO todolisttable (ID, Description, Category, Date)"
+ item7.toString();
//delete keyspace
String deletekeyspace = "DROP KEYSPACE IF EXISTS todolist";
//delete table
String deletetable = "DROP TABLE todolisttable";
//create table
String table = "CREATE TABLE todolist.todolisttable(id text PRIMARY KEY, "
+ "description text, "
+ "category text, "
+ "date timestamp )";
String tableRDD = "CREATE TABLE todolist.temp(id text PRIMARY KEY, "
+ "description text, "
+ "category text )";
//Query all data
String query = "SELECT * FROM todolist.todolisttable";
String query1 = "SELECT * FROM todolist.temp";
//Update table
String update = "UPDATE todolisttable SET Category='Fun',Description='Go to the beach' WHERE ID='Ron'";
//Deleting data where the index id = George
String delete = "DELETE FROM todolisttable WHERE ID='George'";
//Deleting all data
String deleteall = "TRUNCATE todolisttable";
//---------------------------------------------------------------------------------
private transient SparkConf conf;
private SparkApp(SparkConf conf) {
this.conf = conf;
}
private void run() {
JavaSparkContext sc = new JavaSparkContext(conf);
createSchema(sc);
loadData(sc);
saveRDDToCassandra(sc);
queryData(sc);
accessTableWitRDD(sc);
sc.stop();
}
private void createSchema(JavaSparkContext sc) {
CassandraConnector connector = CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
session.execute(deletekeyspace);
session.execute(keyspace);
session.execute("USE todolist");
session.execute(table);
session.execute(tableRDD);
}
}
private void loadData(JavaSparkContext sc) {
CassandraConnector connector = CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
session.execute(task1);
session.execute(task2);
session.execute(task3);
session.execute(task4);
session.execute(task5);
session.execute(task6);
session.execute(task7);
}
}
private void queryData(JavaSparkContext sc) {
CassandraConnector connector = CassandraConnector.apply(sc.getConf());
try (Session session = connector.openSession()) {
ResultSet results = session.execute(query);
System.out.println("\nQuery all results from cassandra's todolisttable:\n" + results.all());
ResultSet results1 = session.execute(query1);
System.out.println("\nSaving RDD into a temp table in casssandra then query all results from cassandra:\n" + results1.all());
}
}
public void accessTableWitRDD(JavaSparkContext sc){
JavaRDD<String> cassandraRDD = javaFunctions(sc).cassandraTable("todolist", "todolisttable")
.map(new Function<CassandraRow, String>() {
@Override
public String call(CassandraRow cassandraRow) throws Exception {
return cassandraRow.toString();
}
});
System.out.println("\nReading Data from todolisttable in Cassandra with a RDD: \n" + StringUtils.join(cassandraRDD.toArray(), "\n"));
// javaFunctions(cassandraRDD).writerBuilder("todolist", "todolisttable", mapToRow(String.class)).saveToCassandra();
}
public void saveRDDToCassandra(JavaSparkContext sc) {
List<TodoItem> todos = Arrays.asList(
new TodoItem("George", "Buy a new computer", "Shopping"),
new TodoItem("John", "Go to the gym", "Sport"),
new TodoItem("Ron", "Finish the homework", "Education"),
new TodoItem("Sam", "buy a car", "Shopping"),
new TodoItem("Janet", "buy groceries", "Shopping"),
new TodoItem("Andy", "go to the beach", "Fun"),
new TodoItem("Paul", "Prepare lunch", "Coking")
);
JavaRDD<TodoItem> rdd = sc.parallelize(todos);
javaFunctions(rdd).writerBuilder("todolist", "temp", mapToRow(TodoItem.class)).saveToCassandra();
}
//----------------------------------------------------------------------------------------------------------------------------
public static void main( String args[] )
{
SparkConf conf = new SparkConf();
conf.setAppName("TODO spark and cassandra");
conf.setMaster("local");
conf.set("spark.cassandra.connection.host", "localhost");
SparkApp app = new SparkApp(conf);
app.run();
}
}
SparkSQLApp.java Listing
package com.example;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
import java.util.Arrays;
import java.util.List;
/**
* Created by fadi on 6/14/15.
*/
public class SparkSQLApp {
private transient SparkConf conf;
private SparkSQLApp(SparkConf conf) {
this.conf = conf;
}
private void run() {
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
createDataframe(sc, sqlContext);
querySQLData(sqlContext);
sc.stop();
}
public void createDataframe(JavaSparkContext sc, SQLContext sqlContext ) {
List<TodoItem> todos = Arrays.asList(
new TodoItem("George", "Buy a new computer", "Shopping"),
new TodoItem("John", "Go to the gym", "Sport"),
new TodoItem("Ron", "Finish the homework", "Education"),
new TodoItem("Sam", "buy a car", "Shopping"),
new TodoItem("Janet", "buy groceries", "Shopping"),
new TodoItem("Andy", "go to the beach", "Fun"),
new TodoItem("Paul", "Prepare lunch", "Cooking")
);
JavaRDD<TodoItem> rdd = sc.parallelize(todos);
DataFrame dataframe = sqlContext.createDataFrame(rdd, TodoItem.class);
sqlContext.registerDataFrameAsTable(dataframe, "todo");
System.out.println("Total number of TodoItems = [" + rdd.count() + "]\n");
}
public void querySQLData(SQLContext sqlContext) {
DataFrame result = sqlContext.sql("SELECT * from todo");
System.out.println("Show the DataFrame result:\n");
result.show();
System.out.println("Select the id column and show its contents:\n");
result.select("id").show();
}
public static void main( String args[] )
{
SparkConf conf = new SparkConf();
conf.setAppName("TODO sparkSQL and cassandra");
conf.setMaster("local");
conf.set("spark.cassandra.connection.host", "localhost");
SparkSQLApp app = new SparkSQLApp(conf);
app.run();
}
}
Todoitem.java Listing
package com.example;
import java.io.Serializable;
import java.time.LocalDateTime;
public class TodoItem implements Serializable {
private String id;
private String description;
private String category;
private final LocalDateTime date = LocalDateTime.now();
public TodoItem(String id, String description, String category) {
this.id = id;
this.description = description;
this.category = category;
}
public String getId(){
return this.id;
}
public String getDescription(){
return this.description;
}
public String getCategory(){
return this.category;
}
public void setId(String id) {
this.id = id;
}
public void setDescription(String description) {
this.description = description;
}
public void setCategory(String category) {
this.category = category;
}
@Override
public String toString() {
return "VALUES ( " + "'" + this.id +"'" + ", " + "'" + this.description +"'" + ", " + "'" + this.category +"'" +", " + "'" + date +"'" + ")";
}
}
build.gradle Listing
apply plugin: 'idea'
apply plugin: 'java'
apply plugin: 'jetty'
apply plugin: 'application'
applicationName = 'todocass'
applicationDefaultJvmArgs = ["-Dlogback.configurationFile=etc/todosolr/logging.xml"]
sourceCompatibility = 1.8
version = '1.0'
repositories {
mavenLocal()
mavenCentral()
}
task runSpark(type: JavaExec, dependsOn: 'classes') {
main = "com.example.SparkApp"
classpath = sourceSets.main.runtimeClasspath
}
task runSparkSQL(type: JavaExec, dependsOn: 'classes') {
main = "com.example.SparkSQLApp"
classpath = sourceSets.main.runtimeClasspath
}
dependencies {
//spark and cassandra connector to work with java
compile 'com.datastax.spark:spark-cassandra-connector_2.10:1.1.1-rc4'
compile 'com.datastax.spark:spark-cassandra-connector-java_2.10:1.1.1'
compile 'org.apache.spark:spark-streaming_2.10:1.5.0'
compile 'org.apache.spark:spark-sql_2.10:1.5.0'
//logback dependencies
compile 'ch.qos.logback:logback-core:1.1.3'
compile 'ch.qos.logback:logback-classic:1.1.3'
compile 'org.slf4j:slf4j-api:1.7.12'
}
//Install/copy tasks
task copyDist(type: Copy) {
dependsOn "installApp"
from "$buildDir/install/todocass"
into 'opt/todocass'
}
task copyLog(type: Copy) {
from "src/main/resources/logback.xml"
into "etc/todocass/"
}
task copyLogToImage(type: Copy) {
from "src/main/resources/logback.xml"
into "image-todo-cass/etc"
}
task copyDistToImage(type: Copy) {
dependsOn "installApp"
from "$buildDir/install/todocass"
into "$projectDir/image-todo-cass/opt/todocass"
}
Cloudurable specialize in AWS DevOps Automation for SMACK! Cassandra, Spark and Kafka
We hope this tutoiral on Spark and Cassandra helpful. We also provide Spark consulting, Casandra consulting and Kafka consulting to get you setup fast in AWS with CloudFormation and CloudWatch. Support us by checking out our Spark Training, Casandra training and Kafka training.
Run it
First run Cassandra:
cd ~/cassandra
bin/cassandra -f
Get the code:
git clone https://github.com/MammatusTech/Spark-Course.git
Then build Spark-Course:
cd Spark-Course
gradle clean build
First run SparkApp, this is the example of Spark working with Cassandra:
gradle runSpark
you should see the following:
Query all results from cassandra's todolisttable:
[Row[George, Shopping, Mon Jun 15 13:36:07 PDT 2015, Buy a new computer], Row[Janet, Shopping, Mon Jun 15 13:36:07 PDT 2015, buy groceries], Row[John, Sport, Mon Jun 15 13:36:07 PDT 2015, Go to the gym], Row[Paul, Coking, Mon Jun 15 13:36:07 PDT 2015, Prepare lunch], Row[Ron, Education, Mon Jun 15 13:36:07 PDT 2015, Finish the homework], Row[Andy, Fun, Mon Jun 15 13:36:07 PDT 2015, go to the beach], Row[Sam, Shopping, Mon Jun 15 13:36:07 PDT 2015, buy a car]]
Saving RDD into a temp table in casssandra then query all results from cassandra:
[Row[George, Shopping, Buy a new computer], Row[Janet, Shopping, buy groceries], Row[John, Sport, Go to the gym], Row[Paul, Coking, Prepare lunch], Row[Ron, Education, Finish the homework], Row[Andy, Fun, go to the beach], Row[Sam, Shopping, buy a car]]
Reading Data from todolisttable in Cassandra with a RDD:
CassandraRow{id: Paul, category: Coking, date: 2015-06-15 13:36:07-0700, description: Prepare lunch}
CassandraRow{id: Sam, category: Shopping, date: 2015-06-15 13:36:07-0700, description: buy a car}
CassandraRow{id: Ron, category: Education, date: 2015-06-15 13:36:07-0700, description: Finish the homework}
CassandraRow{id: Janet, category: Shopping, date: 2015-06-15 13:36:07-0700, description: buy groceries}
CassandraRow{id: John, category: Sport, date: 2015-06-15 13:36:07-0700, description: Go to the gym}
CassandraRow{id: George, category: Shopping, date: 2015-06-15 13:36:07-0700, description: Buy a new computer}
CassandraRow{id: Andy, category: Fun, date: 2015-06-15 13:36:07-0700, description: go to the beach}
Then run SparkSQLAPP, this is the example of Spark SQL working with Cassandra:
gradle runSparkSQL:
you should see the following:
Total number of TodoItems = [7]
Show the DataFrame result:
+---------+-------------------+------+
| category| description| id|
+---------+-------------------+------+
| Shopping| Buy a new computer|George|
| Sport| Go to the gym| John|
|Education|Finish the homework| Ron|
| Shopping| buy a car| Sam|
| Shopping| buy groceries| Janet|
| Fun| go to the beach| Andy|
| Cooking| Prepare lunch| Paul|
+---------+-------------------+------+
Select the id column and show its contents:
+------+
| id|
+------+
|George|
| John|
| Ron|
| Sam|
| Janet|
| Andy|
| Paul|
+------+
Conclusion for Part 2 Spark Tutorial
We showed that Spark is a very powerful tool for real-time analytics. We introduces an important part of the Spark Ecosystem, namely, Spark SQL and DataFrames. DataFrames build on top of RDD to provide partitions of data that can be processed in parallel.
We also demonstrated how to use Spark and Spark SQL with Cassandra.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Apache Spark has proven to be a natural successor to Hadoop and continues the BigData trend. It works well in the Hadoop world and can be a fast on-ramp to BigData data analsyis. Spark provides an easy to use API to perform large distributed jobs for data analytics. Apache Spark puts the power of BigData into the hands of mere mortal developers to provide real-time data analytics. Spark SQL is an example of an easy-to-use but power API provided by Apache Spark.
Reference
About Cloudurable
We hope you enjoyed this article. Please provide feedback. Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Check out our new GoLang course. We provide onsite Go Lang training which is instructor led.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting