February 27, 2017
In this part of Spark’s tutorial (part 3), we will introduce two important components of Spark’s Ecosystem: Spark Streaming and MLlib.

Spark Streaming
By Fadi Maalouli and R.H.
Spark Streaming is a real-time processing tool, that has a high level API, is fault tolerant, and is easy to integrate with SQL DataFrames and GraphX.
On a high level Spark Streaming works by running receivers that receive data from for example S3, Cassandra, Kafka etc… and it divides these data into blocks, then pushes these blocks into Spark, then Spark will work with these blocks of data as RDDs, from here you get your results. The following diagram will demonstrate the process:

Why is Spark Streaming being adopted widely?
- Has an easy high level API
- Easy to integrate with other parts of Spark ecosystem like Spark SQL.
- If you know how to use Spark, Spark Streaming will be intuitive and easy to operate as well (very similar)
Some of the companies that use Spark Streaming and how they use it?
Netflix
They are interested in using Spark Streaming for collecting data about trending movies and shows in real time, and using that data to give up to date recommendations to users based on their interest and habits [2].
Pearson
Pearson is the world’s largest education company, they help people all over the world to aim higher and improve their lives through education [4].
They are using Spark Streaming to monitor each student’s progress and what ways are more effective for them to learn faster [3].
Demonstrating how to use Spark Streaming with Kafka in Java
We will use the Spark Streaming receivers to receive data from Kafka, this data will be stored in what is called Spark executors then Spark Streaming can process the data.
In order to ensure that data won’t be lost when there is a failure you have to enable Write Ahead Logs in Spark Streaming.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
In order to incorporate Spark Streaming into your application that uses Kafka, you need to do the following three steps; Link Spark Streaming to your project, Program your application, and Deploy your application:
1 . Link Spark Streaming Kafka into your project by importing the following artifact from maven central:
Import Spark Streaming Kafka into your project
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.4.1</version>
</dependency>
For linking other Streaming sources like Flume, Kinesis, Twitter, and MQTT use the following for the artifactId:
- spark-streaming-flume_2.10
- spark-streaming-kinesis-asl_2.10
- spark-streaming-twitter_2.10
- spark-streaming-mqtt_2.10
2 . The programing part: Initialize a Streaming Context, this is the entry point for all Spark Streaming functionalities. It can be created from a SparkConf object. SparkConf enables you to configure some properties such as Spark Master and application name, as well as arbitrary key-value pairs through the set() method.
Spark Master is the cluster manager to connect to, some of the allowed URLs:
-
local (Run Spark locally with one worker thread)
-
local[K] (Run Spark locally with K threads, usually k is set up to match the number of cores on your machine)
-
spark://HOST:PORT (Connect to a given cluster master. The port must match with your master, default is 7077)
Setting up SparkConf and JavaStreamingContext
import org.apache.spark.*;
import org.apache.spark.streaming.api.java.*;
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaStreamingContext ssc = new JavaStreamingContext(conf, Duration(1000));
String master is a special “local[*]” string to run in local mode.
Duration(1000) is a batch interval this has to be set based on your performance needs. for more details on this check out this doc on [Performance Tuning. ] (http://spark.apache.org/docs/latest/streaming-programming-guide.html#setting-the-right-batch-interval)
You can also create a JavaStreamingContext from a JavaSparkContext:
####Create JavaStreamingContext from JavaSparkContext
import org.apache.spark.streaming.api.java.*;
JavaSparkContext sc =new JavaSparkContext(); //existing JavaSparkContext
JavaStreamingContext ssc = new JavaStreamingContext(sc, Durations.seconds(1));
Then create an input DStrream:
Create an input DStream
import org.apache.spark.streaming.kafka.*;
JavaPairReceiverInputDStream<String, String> kafkaStream =
KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]);
DStream represents a chain of RDDs each RDD contains data from a certain time interval. The following represents a high level diagram of a DStream:
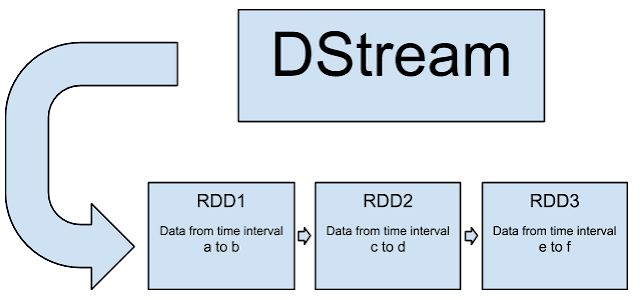 [Display] (http://2.bp.blogspot.com/-vmc04TRGfOA/Vdvq0d-kArI/AAAAAAAAARQ/nfQ1dM1NHgI/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.10.11%2BPM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
[Display] (http://2.bp.blogspot.com/-vmc04TRGfOA/Vdvq0d-kArI/AAAAAAAAARQ/nfQ1dM1NHgI/s640/Screen%2BShot%2B2015-08-24%2Bat%2B9.10.11%2BPM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
3 . Finally for deploying your application, if you are using Scala or Java simply package spark-streaming-kafka_2.10 and its dependencies into the application JAR. Then use spark-submit to launch your application. For more details on deploying your spark streaming application visit this link [deploying information ] (http://spark.apache.org/docs/latest/streaming-programming-guide.html#deploying-applications)
To Spark submit your application
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka_2.10:1.4.1 ...
The following is a simple example to demonstrate how to use Spark Streaming.
Simple example on Spark Streaming
This example is from Spark’s documentations [1]. Say we have a data server listening on a TCP socket and we want to count the words received by that server:
As mentioned previously first we need to create a JavaStreamingContext:
Create JavaStreamingContext
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1))
Then we need to create a DStream:
####Create a DStream
// Create a DStream that will connect to hostname:port, like localhost:9999
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
Note DStream lines will receive the data from the data server. Each block of data received is a line of words, remember we want to count the words so we need to transform the lines into words by looking for the spaces between the words and split them:
Transform the lines DStream into a words DStream
// Split each line into words
JavaDStream<String> words = lines.flatMap(
new FlatMapFunction<String, String>() {
@Override public Iterable<String> call(String x) {
return Arrays.asList(x.split(" "));
}
});
flatMap is a DStream method that will make a new DStream made of smaller blocks than the original stream in this case it is making lines into words.
Then we need to count the words received:
Counting the words
// Count each word in each batch
JavaPairDStream<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print();
To start the processing after all transformations are set up:
Start the processing
jssc.start(); // Start the computation
jssc.awaitTermination(); // Wait for the computation to terminate
MLlib
MLlib is a part of Spark’s ecosystem. MLlib is a machine learning framework its main goal is to make building a machine learning application easy, and scalable by learning from big data sets. MLlib consists of the following learning algorithms:
- Classification
- Dimensionality Reduction
- Clustering
- Regression
- Collaborative Filtering
- Recommendation
- Statistics
- and many more…
For a full list of algorithms with their descriptions visit the following [MLlib guide. ] (http://spark.apache.org/docs/latest/mllib-guide.html)
What if you want to go beyond these algorithms, then you will need what is called a ML Workflows.
What is ML Workflows?
The best way to explain ML Workflows is to go over a simple example. Lets say we have a large article that consists of many topics, this would be our data and we want to predict the topics using ML Workflow, here is a diagram of what we would have:
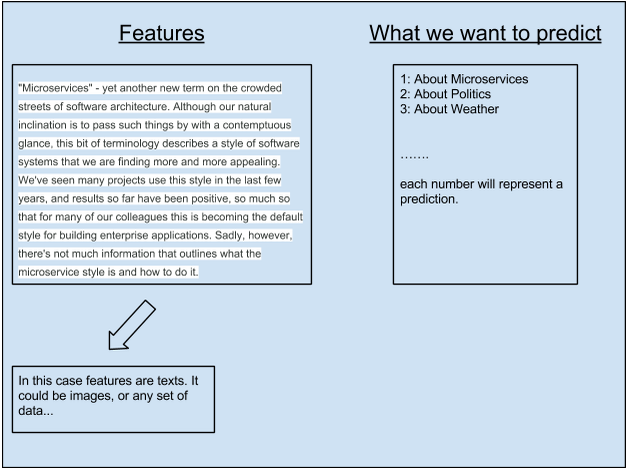 [Display] (http://4.bp.blogspot.com/-W2Hy9IH9LGc/Vd61PlO-GoI/AAAAAAAAASM/n7U1prasUGA/s640/Screen%2BShot%2B2015-08-26%2Bat%2B11.58.47%2BPM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
[Display] (http://4.bp.blogspot.com/-W2Hy9IH9LGc/Vd61PlO-GoI/AAAAAAAAASM/n7U1prasUGA/s640/Screen%2BShot%2B2015-08-26%2Bat%2B11.58.47%2BPM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
There are two main components for a ML workflow; Training, and Testing:
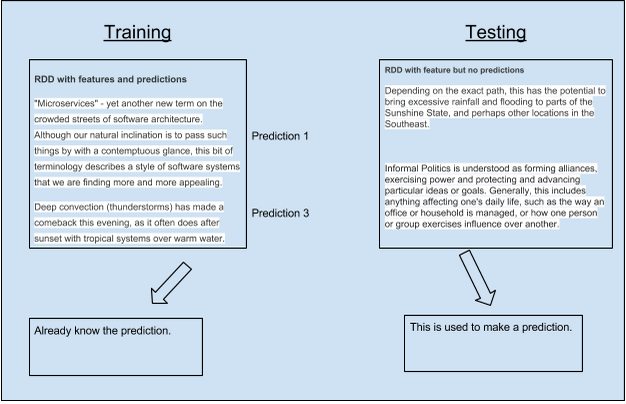
Training will consist of RDDs that have the features which are texts in this case and has the predictions next to the features this information will be available for each row or instance.
Testing will have only the features present in the RDD, then will use the model from training to make predictions for example by reading keywords.
Training will have several components of its own; Load data, pull features, train model, and evaluate. Here is a diagram for demonstration:
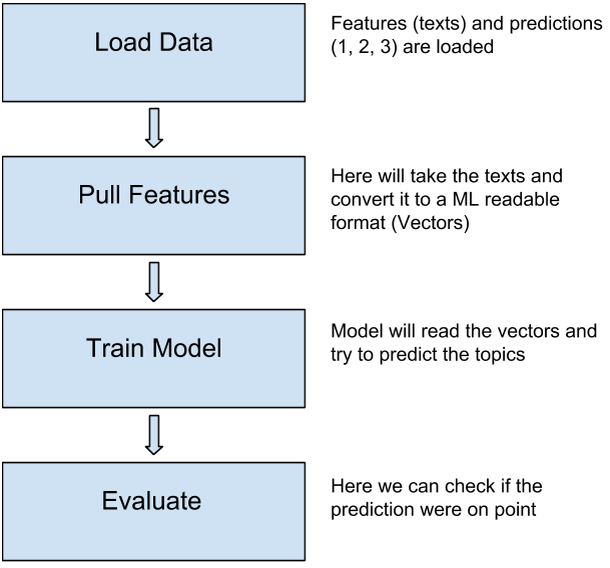
Some of the problems that will be encountered using this ML Workflow:
- You might need to work with a lot of RDDs and data types.
- It might be easy to write the code for the ML Workflow but it will be hard to reuse it later, especially when you move into testing, it needs to handle all kinds of data.
- In order to improve the final result you might need to play with each step’s parameter in the ML Workflow based on the data you have.
To fix these problems, Spark came up with Pipelines. How does Pipelines make things easier?
Cloudurable specialize in AWS DevOps Automation for SMACK! Cassandra, Spark and Kafka
We hope this tutorial on Spark Streaming and MLib is useful. We also provide Spark consulting, Casandra consulting and Kafka consulting to get you setup fast in AWS with CloudFormation and CloudWatch. Support us by checking out our Spark Training, Casandra training and Kafka training.
####Pipelines
Pipelines will make use of the DataFrames, which were explained previously but to recap, DataFrames are basically RDDs that have named columns and types (schema), from our example we can have one column as the predictions and an other as the texts, it also provides a Domain Specific Language (DSL) for example we can filter all the predictions that are equal to 1 (Microservices topic) from the table. This Pipeline feature will take care of the first problem stated above; dealing with a lot of RDDs and data types.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
We can do Abstractions with Pipelines, trasforming one DataFrame into another, for example during the Pull Features step in ML Workflow we can transform the loaded data (texts, and predictions columns) into another DataFrame that has Texts, Predictions, and Features columns (Features will be made from the texts)
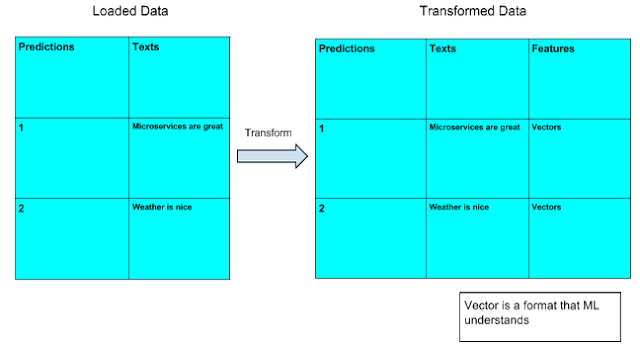 [Display] (http://1.bp.blogspot.com/-EyVz8HFBnWY/VeQBJ8Vhc7I/AAAAAAAAAU8/d7KnwoLPh4k/s640/Screen%2BShot%2B2015-08-31%2Bat%2B12.23.59%2BAM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
[Display] (http://1.bp.blogspot.com/-EyVz8HFBnWY/VeQBJ8Vhc7I/AAAAAAAAAU8/d7KnwoLPh4k/s640/Screen%2BShot%2B2015-08-31%2Bat%2B12.23.59%2BAM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
An Estimator can be used in the next step of the ML Workflow Train Model, what an estimator does is that it takes the features and predictions from a Dataframe and will make a prediction for us, matching a feature with a prediction.
In the final stage of the ML Workflow Evaluate, we can use an evaluator, this will take the final DataFrame and return a value. For example it can compare the prediction we got from the previous step with what it should be and then return how accurate it was.
Here is a diagram to summarize the process:
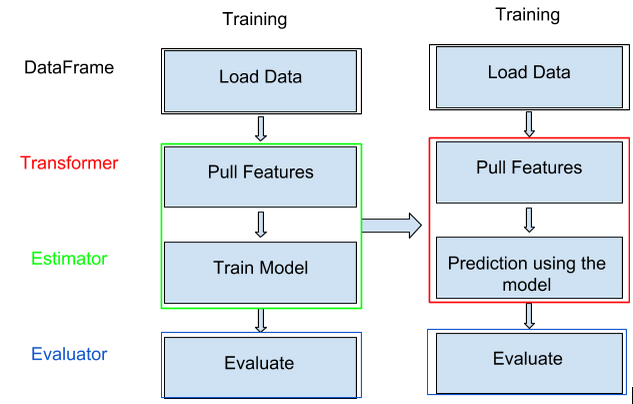 [Display] (http://1.bp.blogspot.com/-J_go8BAh1eM/VeAJxfWe1fI/AAAAAAAAATk/ty2Evawsjsc/s640/Screen%2BShot%2B2015-08-28%2Bat%2B12.11.29%2BAM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
[Display] (http://1.bp.blogspot.com/-J_go8BAh1eM/VeAJxfWe1fI/AAAAAAAAATk/ty2Evawsjsc/s640/Screen%2BShot%2B2015-08-28%2Bat%2B12.11.29%2BAM.png) - [Edit] (https://docs.google.com/document/d/1yrQrP9wkIHUaGRJEQ9TByWlShptCs_wAnWu9WWDoDPE/edit?usp=sharing)
In the training part at the top we load data, we get a DataFrame then we transform that data as mentioned before, then We use a model to estimate, in this case estimate a topic prediction. Now under training in that green box (transformer and estimator) will act as an estimator. If we go to testing we use the model from training to do the estimation, and the red block will act as a transformer, so now under testing instead of having new models to make predictions, it just gets data at the top and outputs the predictions at the bottom, no need for models to predict. This will take care of the second problem listed above.
Only one problem left from the three mentioned above, the parameter tuning problem, with Pipelines this can be taken care of by passing the pipeline to a CrossValidator which will take care of the parameter tuning automatically.
If we zoom into the green box under training (from above), this would be the Pipeline. This Pipeline consists of three parts Tokenizer, HashingTF, and LogisticRegression:
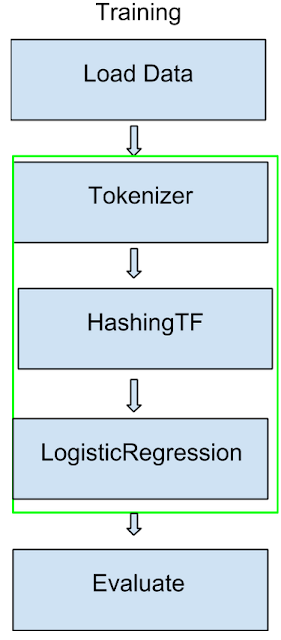
Tokenizer will take the text data from the DataFrame and break them into words, then HashingTF will take these words and transform them into vector feature a format that would be readable by LogisticRegression, and finally a model will be produced that can make predictions.
Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
##References
[1] http://spark.apache.org/docs/
[2] http://techblog.netflix.com/2015/03/can-spark-streaming-survive-chaos-monkey.html
[4] https://www.pearson.com/about-us.html
Cloudurable specialize in AWS DevOps Automation for SMACK! Cassandra, Spark and Kafka
We hope this tutorial on Spark Streaming and MLib is useful. We also provide Spark consulting, Casandra consulting and Kafka consulting to get you setup fast in AWS with CloudFormation and CloudWatch. Support us by checking out our Spark Training, Casandra training and Kafka training.
About Cloudurable
We hope you enjoyed this article. Please provide feedback. Cloudurable provides Spark training, and Spark consulting “Apache Spark Professional Services and Consulting”.
Check out our new GoLang course. We provide onsite Go Lang training which is instructor led.
TweetApache Spark Training
Kafka Tutorial
Akka Consulting
Cassandra Training
AWS Cassandra Database Support
Kafka Support Pricing
Cassandra Database Support Pricing
Non-stop Cassandra
Watchdog
Advantages of using Cloudurable™
Cassandra Consulting
Cloudurable™| Guide to AWS Cassandra Deploy
Cloudurable™| AWS Cassandra Guidelines and Notes
Free guide to deploying Cassandra on AWS
Kafka Training
Kafka Consulting
DynamoDB Training
DynamoDB Consulting
Kinesis Training
Kinesis Consulting
Kafka Tutorial PDF
Kubernetes Security Training
Redis Consulting
Redis Training
ElasticSearch / ELK Consulting
ElasticSearch Training
InfluxDB/TICK Training TICK Consulting